一种结合全局运动参数的行为识别方法与流程
本发明涉及行为识别技术,特别涉及第一视角的行为识别技术。
背景技术:
伴随着深度学习的发展和可穿戴的智能设备的增加,第一视角的行为识别越来越重要,同时也带来一定的挑战性。传统方法解决行为识别问题主要采用手工特征设计,例如,传统算法表现最好的idt,其主要是通过手工提取hof、hog、mbh、trajectory4等特征,然后利用fv(fishervector)方法对特征进行编码,再基于编码特征训练svm分类器;然而深度学习的出现,通过网络模型自己学习特征,可以很好的克服手工提取特征问题。深度学习主要包括two-stream、三维卷积等方向;其中two-stream包含两个支路,其中之一是利用光流作为网络模型输入,然而提取光流需要消耗大量时间,不过光流的确可以提供很好的运动信息以供网络模型学习,所以缺失光流对准确率会有很大的影响。而且由于智能设备穿戴者的一些自然动作,相机经常会产生抖动和模糊的镜头,出现难以理解的视频,增加行为识别难度,因此运动信息对于可穿戴智能设备的行为识别是必不可少的。
目前,对于可穿戴设备第一视角行为识别,增加运动信息主要通过提取光流和增加传感器芯片(陀螺仪,加速器等);然而提取光流消耗大量时间,增加网络运行时间,很难实现实时检测,而增加传感器,没有增加网络运行时间,但是增加可穿戴智能设备的成本,这对可穿戴设备的智能产品都不是很友好。
技术实现要素:
本发明所要解决的技术问题是,提供一种适用于可穿戴智能设备的第一视角行为识别方法。
本发明为解决上述技术问题所采用的技术方案是,一种结合全局运动参数的行为识别方法,包括以下步骤:
1)待识别的行为视频输入行为识别网络后,同时进入步骤2)与步骤3);
2)通过三维卷积对输入的行为视频进行处理提取行为视频特征,进入步骤4);
3)提取行为视频的全局运动参数,再提取全局运动参数的全局运动信息特征,进入步骤4);
4)将行为视频特征与全局运动信息特征通过相加的方式进行融合,得到融合特征;
5)对融合特征进行行为识别。
由于智能设备是戴在头部的,所以随着头部的运动会产生全局运动信息,这对于行为识别会产生很大的干扰,将原始行为视频的特征与全局运动信息特征进行融合,能减少全局运动信息的影响。
本发明的有益效果是,不增加智能设备的成本,只稍微增加网络运行时间,计算复杂度低,将全局运动信息融入行为识别网络,为行为识别网络提供全局信息,减少头部抖动以及一些全局信息的干扰,使得预测准确率更高,而且全局运动参数的提取相对于光流的提取极大的降低了时间成本。
附图说明
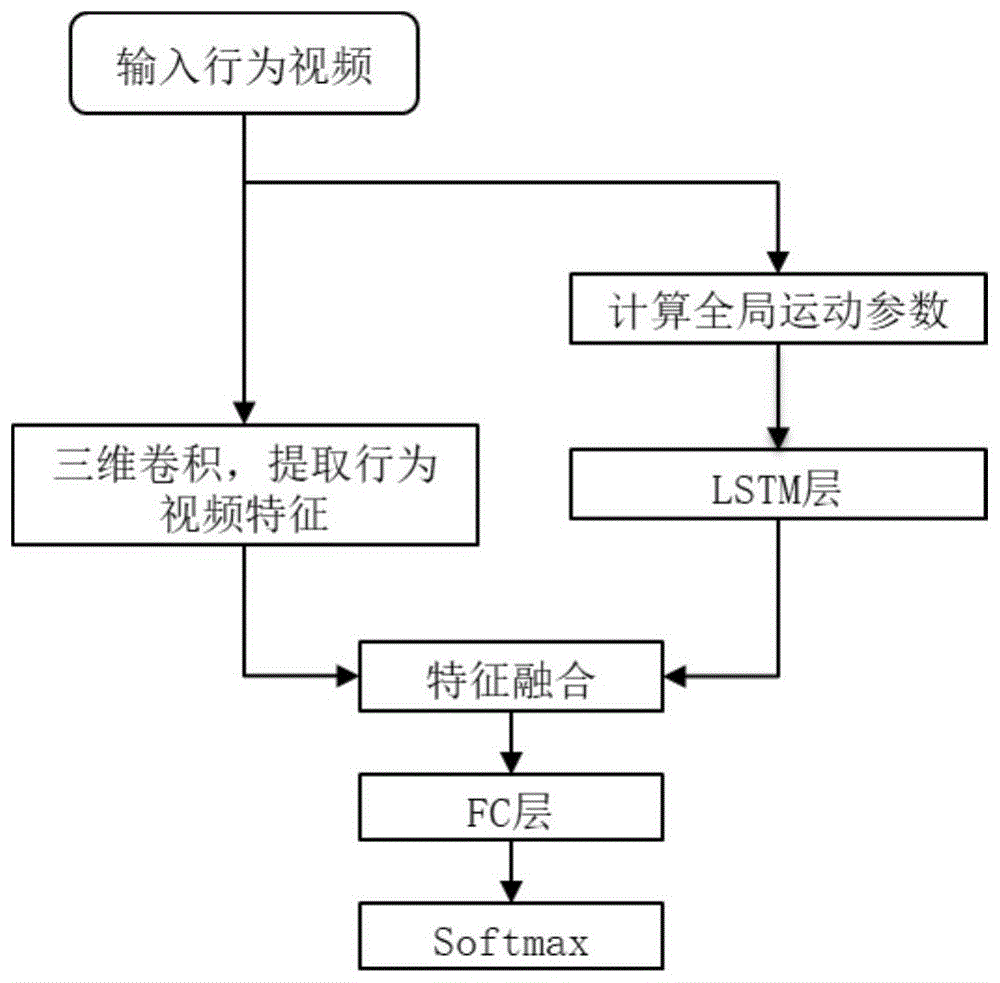
图1:实施例流程图。
具体实施方式
行为识别网络在训练时包括三维卷积网络、全局运动参数计算模块、长短期记忆网络lstm、fc层、softmaxloss模块;行为识别网络在测试时包括三维卷积网络、全局运动参数计算模块、长短期记忆网络lstm、fc层、softmax模块。
由于two_stream是将图像作为网络输入,是对每帧图像单独处理。然而行为识别是一个连续动作,仅仅对单帧进行处理,没有利用前后帧的信息,从时间维度上看连续性存在一定的问题。如图1所示,本发明的行为识别网络将输入的行为视频分做两个支路,一个支路输入至三维卷积网络,通过三维卷积对行为视频处理得到行为视频特征,行为视频特征中包括有前后帧之间的信息,能提高之后行为识别的准确率。
另一个支路是输入至全局运动参数计算模块从行为视频中提取全局运动参数,使网络模型利用全局信息,减少全局运动信息对行为识别的影响,首先要根据行为视频提取全局运动参数,实施例采用的是六参数模型的全局运动估计:
其中,(x,y)代表参考帧中像素的坐标,(x′,y′)代表当前帧中像素的坐标,p=(a,b,c,d,e,f)t为六参数矢量。
将当前帧划分成n个宏块,将计算出的运动矢量与估计出的当前帧的坐标,通过最小二乘法迭代来计算六参数最优估计:
其中(xk,yk)为第k个宏块的运动矢量,(x′k,y′k)是第k个宏块的坐标。
然后,将计算得到的全局运动参数送入长短期记忆网络lstm得到全局运动信息特征,将全局运动信息特征与行为视频特征进行特征融合,最终经过一个全连接层fc对融合特征进行判决之前的预处理。在训练阶段,softmaxloss模块接收到fc层输入的融合特征后用交叉熵计算损失,并计算损失函数的梯度,采用sgd梯度下降法更新行为识别网络模型参数。训练直至网络模型收敛,性能达到最优。训练完成后,fc层对融合特征进行判决之前的预处理得到每种行为的预测值后,输入至softmax进行行为识别。
技术特征:
1.一种结合全局运动参数的行为识别方法,其特征在于,包括以下步骤:
1)待识别的行为视频输入行为识别网络后,同时进入步骤2)与步骤3);
2)通过三维卷积对输入的行为视频进行处理提取行为视频特征,进入步骤4);
3)提取行为视频的全局运动参数,再提取全局运动参数的全局运动信息特征,进入步骤4);
4)将行为视频特征与全局运动信息特征通过相加的方式进行融合,得到融合特征;
5)对融合特征进行行为识别。
2.如权利要求1所述方法,其特征在于,全局运动参数为六参数模型的全局运动估计得到参数:
其中,(x,y)代表参考帧中像素坐标,(x′,y′)代表当前帧中像素的坐标,p=(a,b,c,d,e,f)t为六参数矢量;
提取行为视频的全局运动参数的方法是:将当前帧划分成n个宏块,将计算出的运动矢量与估计出的当前帧的坐标,通过最小二乘法迭代来计算六参数最优估计:
其中,(xk,yk)为第k个宏块的运动矢量,(x′k,y′k)是k个宏块的坐标。
3.如权利要求1所述方法,其特征在于,步骤3)中通过长短期记忆网络lstm提取全局运动信息特征。
技术总结
本发明提供一种结合全局运动参数的行为识别方法。由于智能设备是戴在头部的,所以随着头部的运动会产生全局运动信息,这对于行为识别会产生很大的干扰,将原始行为视频的特征与全局运动信息特征进行融合,能减少全局运动信息的影响。本发明不增加智能设备的成本,只稍微增加网络运行时间,计算复杂度低,将全局运动信息融入行为识别网络,为行为识别网络提供全局信息,减少头部抖动以及一些全局信息的干扰,使得预测准确率更高,而且全局运动参数的提取相对于光流的提取极大的降低了时间成本。
技术研发人员:李宏亮;王强;杨健榜;王晓朋;罗鹏飞;陶聚
受保护的技术使用者:电子科技大学
技术研发日:2019.08.28
技术公布日:2019.12.24
- 还没有人留言评论。精彩留言会获得点赞!