一种构建半自动智能文本处理系统的方法与流程
背景技术:
随着大数据时代的到来,每一个企业组织每天都会产生大量的数据。要想获得数据潜在的价值,就必须使用合适的方法对这些数据进行分析和处理。其中有一类较难处理的数据,那就是非结构化的文本数据。近年来,深度学习技术取得了飞速发展,自然语言处理也借助于深度学习取得了重大突破。除此之外,计算机硬件进步和hadoop,spark等优秀大数据处理解决方案的不断完善,使得对海量文本数据的分析处理成为了可能。
非结构化的文本数据只有经过处理后成为结构化的数据才能进行统计分析,进而辅助决策的制定。采用深度学习进行文本数据分析最重要的是训练样本的数量。在一个项目的开始阶段,往往会将可获得的所有数据用作训练样本,。但是,新的数据还是会源源不断的产生,使用旧的数据训练的模型并不能保证在新的数据上的泛化能力,为此就要不断的使用新的数据来更新模型,使模型的准确率和召回率能够不断提升,这将是一个长期过程。为了提升系统运行效率,使得整个打标,分析,入库,可视化展示流程规范化,需要设计一种全新的系统架构。
技术实现要素:
本发明设计了一种系统架构,能够实现自动的从数据源获取数据、数据预处理、使用自然语言处理算法进行分析、分析结果回写、数据可视化展示。并且系统内部提供了进行人工打标的规范化接口,当新的经由人工标注的训练样本积累到一定数量时,系统会自动的使用这些样本数据来训练新的模型。随着数据的不断积累,此系统的文本标注的效率可以稳步上升,并且大大减少了人工干预,节省了大量人力成本。
附图说明
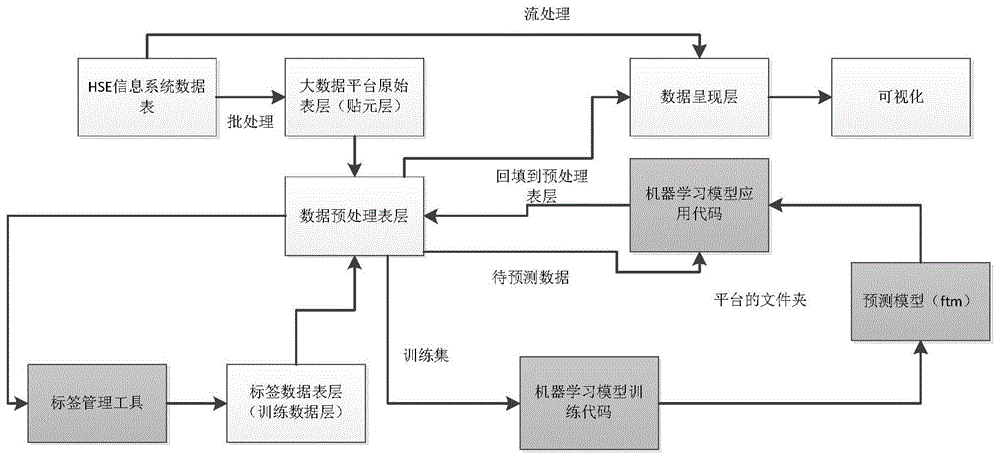
图1是本发明的系统架构图。
图2是本发明的是训练模型代码涉及的主要算法。
具体实施方式
结合附图说明系统的构建过程。
a.数据接入:数据分为流处理和批处理两类。流处理主要考虑未来信息系统有生产运行动态数据接入后能基于实时动态数据进行分析处理。批处理主要针对安全监管数据的分析应用。
b.大数据平台原始表层(贴元层):数据预处理以及分析方法是多样的,在处理的过程中可能需要反复与原始数据进行核对,贴元层的设计目的是保留信息系统流入的原始数据,增加后续数据预处理等环节的容错能力。
c.数据预处理表层:主要是对数据进行拆分、去空值等工作。事故事件的预处理过程已经确定,平台的建设过程中实现事故事件数据预处理表层的具体设计。
d.标签管理工具:标签工具是.py程序,在应用的过程中是逐条读取表里的数据进行标签标注.工具的输入是csv表,输出是csv表,因此数据预处理表层要设计两个csv数据接口,输出数据给标签工具,并接收来自标签数据表层的csv数据。
e.机器学习模型训练代码:训练数据回填到数据预处理表层存储,并将其喂给机器学习模型训练代码,经过训练形成预测模型。
f.预测模型:形成的预测模型即是用来进行文本分类的模型,是一个ftm文件。
g.机器学习模型应用代码:上载预测模型的代码,这个代码的输入是待预测的数据(这个数据和训练数据构成预处理数据的全集),输出的预测后的数据再回填入数据预处理表层。
h.数据呈现:数据预处理表层的数据流入数据呈现层,数据呈现层的数据直接连接bi工具或者可视化展示程序。
技术特征:
1.a.数据接入:数据分为流处理和批处理两类。流处理主要考虑未来信息系统有生产运行动态数据接入后能基于实时动态数据进行分析处理。批处理主要针对安全监管数据的分析应用。
b.大数据平台原始表层(贴元层):数据预处理以及分析方法是多样的,在处理的过程中可能需要反复与原始数据进行核对,贴元层的设计目的是保留信息系统流入的原始数据,增加后续数据预处理等环节的容错能力。
c.数据预处理表层:主要是对数据进行拆分、去空值等工作。事故事件的预处理过程已经确定,平台的建设过程中实现事故事件数据预处理表层的具体设计。
d.标签管理工具:标签工具是.py程序,在应用的过程中是逐条读取表里的数据进行标签标注.工具的输入是csv表,输出是csv表,因此数据预处理表层要设计两个csv数据接口,输出数据给标签工具,并接收来自标签数据表层的csv数据。
e.机器学习模型训练代码:训练数据回填到数据预处理表层存储,并将其喂给机器学习模型训练代码,经过训练形成预测模型。
f.预测模型:形成的预测模型即是用来进行文本分类的模型,是一个ftm文件。
g.机器学习模型应用代码:上载预测模型的代码,这个代码的输入是待预测的数据(这个数据和训练数据构成预处理数据的全集),输出的预测后的数据再回填入数据预处理表层。
h.数据呈现:数据预处理表层的数据流入数据呈现层,数据呈现层的数据直接连接bi工具或者可视化展示程序。
技术总结
本发明结合目前已有的自然语言算法设计出一种构建半自动智能文本处理系统的方法,能够实现自动的从数据源获取数据、数据预处理、使用自然语言处理算法进行分析、分析结果回写、数据可视化展示。并且系统内部提供了进行人工打标的规范化接口,当新的经由人工标注的训练样本积累到一定数量时,系统会自动的使用这些样本数据来训练新的模型。随着数据的不断积累,此系统的文本标注的效率可以稳步上升,并且大大减少了人工干预,节省了大量人力成本。
技术研发人员:徐九韵;郝壮远
受保护的技术使用者:中国石油大学(华东)
技术研发日:2019.11.13
技术公布日:2020.05.19
- 还没有人留言评论。精彩留言会获得点赞!