基于DDPG-RAM算法的复杂光照条件下织物缺陷检测方法与流程
本发明涉及织物缺陷检测技术领域,具体涉及一种基于ddpg-ram算法的复杂光照条件下织物缺陷检测方法。
背景技术:
强化学习自从上世纪提出以来就广受关注,作为机器学习的一大分支,相较于监督学习和非监督学习,强化学习是在不断与环境的交互中学习状态和行为之间的映射关系从而使得数值回报达到最大化,在缺陷检测方面,强化学习针对不同缺陷种类和不同缺陷的表现形式都有着都有着学习能力,目前应用最为广泛的模型是基于q-learning、dpg和ddpg模型算法,ddpg算法是利用dqn扩展q-learning学习算法对dpg改造后得到的,针对前两种模型只能离散输出的问题,ddpg应用一种基于actor-critic框架的算法,解决了连续空间上的深度强化学习问题,相较于之前的深度学习算法在环境适应力上都有着显著的优势,另一方面,对图像的特征识别,循环注意力模型(ram)通过模仿人眼的注意力机制充分的结合cnn和rnn在缺陷识别上的优势,通常处理大规模图像特征识别。
针对织物缺陷检测的问题,传统方法是基于cnn模型构建多层网络针对织物特定的缺陷进行识别和分类的,此类模型较为复杂且当输入图像数据量较大时就有着明显的劣势了,而且当缺陷种类较多时传统模型不能自动识别。
技术实现要素:
本发明的目的就是针对上述技术的不足,提供一种能自动检测基于ddpg-ram算法的复杂光照条件下织物缺陷检测方法。
为实现上述目的,本发明所设计的基于ddpg-ram算法的复杂光照条件下织物缺陷检测方法如下:
1)采集织物缺陷图像作为训练样本;
2)对步骤1)中织物缺陷图像进行预处理,选用图像增强算法对复杂光照条件下的织物图像进行图像增强;
3)利用步骤2)中图像增强后的训练样本对ddpg-ram模型进行训练,确定训练后的网络参数
3.1)构建ddpg-ram模型,并随机初始化网络参数;
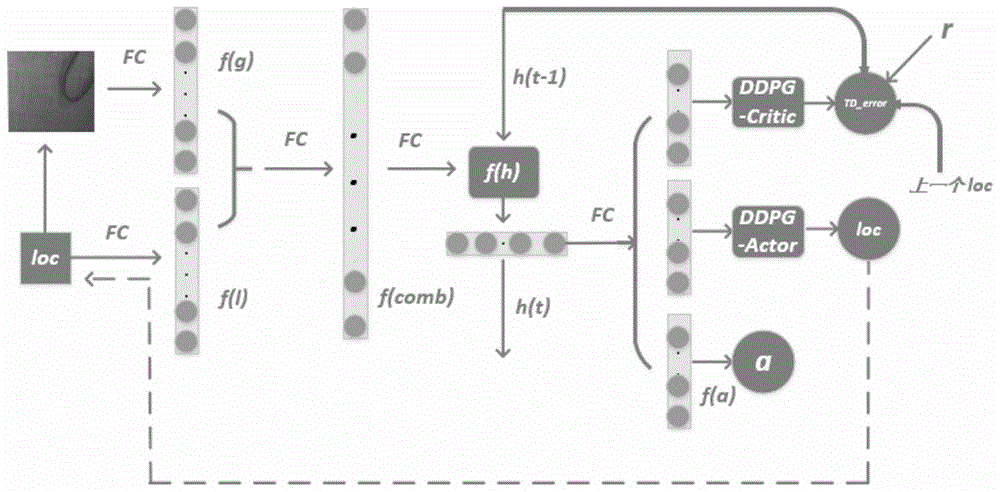
构建ddpg-ram模型,结合了深度确定性策略梯度(ddpg)算法和循环注意力模型(ram),该ddpg-ram模型包括glimpse网络,core网络,action网络,actor网络和critic网络五个部分,actor网络、critic网络又分别构建了两个结构完全相同但参数不同的eval网络和target网络,从而形成actoreval网络、actortarget网络、criticeval网络和critictarget网络共四个网络,其中,actor网络为行为网络、critic网络为评价网络、eval网络为估计网络和target网络为目标网络,actoreval网络为行为估计网络、actortarget网络为行为目标网络、criticeval网络为评价估计网络、critictarget网络为为评价目标网络;然后对该ram模型进行随机初始化,即随机初始化glimpse网络、core网络、action网络、actoreval网络、criticeval网络的参数
3.2)经验池初始化为0,大小为max_size×(2×ht_dim+2+1);
设经验池为i行、j列的二维矩阵,二维矩阵中每个元素的值初始化为0,其中i为样本容量,j为每个样本储存的信息数量,经验池大小为j=max_size×(2×ht_dim+2+1),其中ht_dim为状态的维度;公式中的数字2为动作的维度,公式中的数字1为用于在经验池中存储奖励信息的预留空间;
3.3)构造一个随机正态分布n对注意力位置施加干扰
3.4)对ddpg-ram模型进行训练
4)利用训练后的ddpg-ram模型对织物缺陷图像进行缺陷检测
进一步地,所述步骤3.3)中,初始化一个方差为var2的随机正态分布n,对注意力位置施加干扰,用于探索环境;
将当前隐藏状态ht作为actoreval网络的输入,输出得到一个估计注意力位置lt',可以初始化一个方差为var2,均值为lt'的随机正态分布n,随机正态分布n对这个估计注意力位置lt'-1施加了干扰,用于探索环境,从中随机输出一个实际注意力位置lt-1,用于探索环境,其中t为当前输入隐藏状态的时刻,actoreval网络的参数为θtq。
进一步地,所述步骤3.4)具体过程如下:
3.4.1)随机初始化第一个注意力位置l0;
3.4.2)根据第一个注意力位置l0获得glimpse特征;
glimpse网络包含着glimpse感知器,glimpse感知器对步骤2)中图像增强后待处理的五大类织物缺陷图像x进行采样,围绕着第一个注意力位置l0,获得以第一个注意力位置l0为图像凝视区域中心的4个长度不同的正方形图像,然后使用最近邻插值法将它们统一变换为尺寸为32×32的一组图像,图像第一个注意力位置l0的中间区域是较高分辨率的图像,从中间区域向外的更大区域是逐渐降低的低分辨率图像;
然后glimpse感知器根据所获得的该组图像以及第一个注意力位置l0进行特征提取,通过全连接层连接,得到glimpse网络输出的特征g0;
3.4.3)将时间序列core网络的第一个隐藏状态h0初始化为0;
3.4.4)将core网络的隐藏状态h0和glimpse网络的特征g0作为core网络输入,输出得到新隐藏状态h1;
core网络实际上就是一个rnn网络,时序地将上一个时间序列core网络输出的隐藏状态h0和当前通过glimpse网络输出的特征g0这两个特征结合起来,作为core网络的输入,输出得到rnn网络中一个新的隐藏状态h1;
3.4.5)将core网络输出的新隐藏状态h1作为action网络的输入,输出得到预测分类结果a1,再进一步根据预测的分类结果a1和图像的实际标签label得到奖励函数r1,其中若分类结果a的正确,则奖励函数为r=1,否则奖励函数为r=0;
3.4.6)将core网络输出的新隐藏状态h1作为actoreval网络的输入,输出得到下一个注意力位置l1,lt~n(μ(ht,ftg|θμ),var);
3.4.7)在经验池中储存该组状态转移信息:ht-1、lt-1、rt、ht;
将上一个时间序列core网络的隐藏状态ht-1,上一个时间序列注意力位置lt-1,当前的奖励函数rt以及当前的隐藏状态ht存储在经验池中,并将一个时间序列core网络的隐藏状态ht-1,上一个时间序列注意力位置lt-1,当前的奖励函数rt以及当前的隐藏状态ht统称为状态转移信息;
3.4.8)循环步骤3.4.2)至步骤3.4.7),重复进行t次;
3.4.9)在运行过程中,当经验池储存满时,最新的状态转移信息会替代老的状态转移信息;
后续新的隐藏状态ht+1会替代老的隐藏状态ht,重复步骤3.4.7),将得到的状态转移信息存储在经验池中,直至经验池被存满,存满后每执行一次步骤3.4.7)便跳转执行一次步骤3.4.10);
3.4.10)对actor网络和critic网络进行训练
3.4.11)根据最后的分类结果at和图像的label对action网络、core网络、glimpse网络的参数进行更新;
3.4.12)对步骤3.4)重复训练m次,得到最终的网络参数。
进一步地,所述步骤3.4.10)具体过程如下:
3.4.10.1)随机从经验池取batch组状态转移信息对actoreval网络和criticeval网络进行训练,实现参数的更新;
3.4.10.2)分为i个回合,agent目标网络对随机取的batch组状态转移信息每学习一次,输出的干扰var值更新为如公式:
var=max{var×0.99995,0.1};
3.4.10.3)每间隔j回合,actoreval网络和criticeval的网络参数赋值给actortarget和critictarget网络进行更新,赋值方式如下式:θμ'=tau×θμ+(1-tau)×θμ',θq'=tau×θq+(1-tau)×θq'也就是说步骤5.3)中的此时输入的隐藏状态时刻为t',即经验池被存满后每执行一次步骤3.4.7)的时刻。
与现有技术相比,本发明具有以下优点:本发明基于ddpg-ram算法的复杂光照条件下织物缺陷检测方法,实现了织物缺陷的自动检测,且运行速度快,具有更高的准确性,效果更好。
附图说明
图1是本发明ddpg-ram算法的模型示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的详细说明。
基于ddpg-ram算法的复杂光照条件下织物缺陷检测方法,具体方法如下:
1)采集破洞、纱疵、褶皱、异物和油渍五大类织物缺陷图像作为训练样本;
2)对步骤1)中五大类织物缺陷图像进行预处理,选用图像增强(retinex)算法对复杂光照条件下的织物图像进行图像增强;
图像增强是对训练样本图片局部或者整体进行处理,削弱或去除图像中无用的信息,突出有用的信息,以满足要求。多尺度retinex算法具有较好的鲁棒性,采用多尺度retinex算法对复杂光照条件下步骤1)中的五大类织物缺陷图像进行预处理,可以获得合适的局部细节,也能够在一定程度上抑制光照变化对处理图像造成影响,对织物缺陷图像进行了图像增强;
3)利用步骤2)中图像增强后的训练样本对ddpg-ram模型进行训练,确定训练后的网络参数
3.1)构建ddpg-ram模型,并随机初始化网络参数;
构建ddpg-ram模型,如图1所示,该ddpg-ram模型包括glimpse网络,core网络,action网络,actor网络和critic网络五个部分,actor网络、critic网络又分别构建了两个结构完全相同但参数不同的eval网络和target网络,从而形成actoreval网络、actortarget网络、criticeval网络和critictarget网络共四个网络,其中,actor网络为行为网络、critic网络为评价网络、eval网络为估计网络和target网络为目标网络,actoreval网络为行为估计网络、actortarget网络为行为目标网络、criticeval网络为评价估计网络、critictarget网络为为评价目标网络;然后对该ram模型进行随机初始化,即随机初始化glimpse网络、core网络、action网络、actoreval网络、criticeval网络的参数
3.2)经验池初始化为0,大小为max_size×(2×ht_dim+2+1);
设经验池为i行、j列的二维矩阵,二维矩阵中每个元素的值初始化为0,其中i为样本容量,j为每个样本储存的信息数量,经验池大小为j=max_size×(2×ht_dim+2+1),其中ht_dim为状态的维度;公式中的数字2为动作的维度,公式中的数字1为用于在经验池中存储奖励信息的预留空间;
3.3)构造一个随机正态分布n对注意力位置施加干扰
初始化一个方差为var2(取var=0.22)的随机正态分布n,对注意力位置施加干扰,用于探索环境;
将当前隐藏状态ht作为actoreval网络的输入,输出得到一个估计注意力位置lt',可以初始化一个方差为var2,均值为l′t的随机正态分布n,随机正态分布n对这个估计注意力位置l′t-1施加了干扰,用于探索环境,从中随机输出一个实际注意力位置lt-1,用于探索环境,其中t为当前输入隐藏状态的时刻,actoreval网络的参数为
3.4)对ddpg-ram模型进行训练
3.4.1)随机初始化第一个注意力位置l0;
3.4.2)根据第一个注意力位置l0获得glimpse特征;
glimpse网络包含着glimpse感知器,glimpse感知器对步骤2)中图像增强后待处理的五大类织物缺陷图像x进行采样,围绕着第一个注意力位置l0,获得以第一个注意力位置l0为图像凝视区域中心的4个长度不同的正方形图像,然后使用最近邻插值法将它们统一变换为尺寸为32×32的一组图像,图像第一个注意力位置l0的中间区域是较高分辨率的图像,从中间区域向外的更大区域是逐渐降低的低分辨率图像;
进一步地,glimpse感知器根据所获得的该组图像以及第一个注意力位置l0进行特征提取,通过全连接层连接,得到glimpse网络输出的特征g0;
3.4.3)将时间序列core网络的第一个隐藏状态h0初始化为0;
3.4.4)将core网络的隐藏状态h0和glimpse网络的特征g0作为core网络输入,输出得到新隐藏状态h1;
core网络实际上就是一个rnn网络,时序地将上一个时间序列core网络输出的隐藏状态h0和当前通过glimpse网络输出的特征g0这两个特征结合起来,作为core网络的输入,输出得到rnn网络中一个新的隐藏状态h1;
3.4.5)将core网络输出的新隐藏状态h1作为action网络的输入,输出得到预测分类结果a1,再进一步根据预测的分类结果a1和图像的实际标签label得到奖励函数r1,其中若分类结果a的正确,则奖励函数为r=1,否则奖励函数为r=0;
3.4.6)将core网络输出的新隐藏状态h1作为actoreval网络的输入,输出得到下一个注意力位置l1,lt~n(μ(ht,ftg|θμ),var);
3.4.7)在经验池中储存该组状态转移信息:ht-1、lt-1、rt、ht;
将上一个时间序列core网络的隐藏状态ht-1,上一个时间序列注意力位置lt-1,当前的奖励函数rt以及当前的隐藏状态ht存储在经验池中,并将一个时间序列core网络的隐藏状态ht-1,上一个时间序列注意力位置lt-1,当前的奖励函数rt以及当前的隐藏状态ht统称为状态转移信息;
3.4.8)循环步骤3.4.2)至步骤3.4.7),重复进行t次;
3.4.9)在运行过程中,当经验池储存满时,最新的状态转移信息会替代老的状态转移信息;
后续新的隐藏状态ht+1会替代老的隐藏状态ht,重复步骤3.4.7),将得到的状态转移信息存储在经验池中,直至经验池被存满,存满后每执行一次步骤3.4.7)便跳转执行一次步骤3.4.10);
3.4.10)对actor网络和critic网络进行训练
3.4.10.1)随机从经验池取batch组状态转移信息对actoreval网络和criticeval网络进行训练,实现参数的更新;
3.4.10.2)分为i个回合,agent目标网络对随机取的batch组状态转移信息每学习一次,输出的干扰var值更新为如公式:
var=max{var×0.99995,0.1};
3.4.10.3)每间隔j回合,actoreval网络和criticeval的网络参数赋值给actortarget和critictarget网络进行更新,赋值方式如下式:θμ'=tau×θμ+(1-tau)×θμ',θq'=tau×θq+(1-tau)×θq'也就是说步骤5.3)中的此时输入的隐藏状态时刻为t',即经验池被存满后每执行一次步骤3.4.7)的时刻;
3.4.11)根据最后的分类结果at和图像的label对action网络、core网络、glimpse网络的参数进行更新;
3.4.12)对步骤3.4)重复训练m次,得到最终的网络参数;
4)可利用训练后的ddpg-ram算法对复杂光照条件下织物缺陷图像进行缺陷检测。
实验数据:
实验数据是从tilda数据库中图像按照排除缺陷在边缘图像—旋转、翻转操作—改变图像尺寸—数据扩张的顺序筛选,最终选取了破洞、纱疵、褶皱、异物和油渍五类,数量尺寸12万张左右,尺寸大小从768×512变换为128×128的复杂光照下缺陷织物图像作为训练样本;实验中参数:ddpg-ram模型训练次数m为60000次,t为7次,batch为256组,经验池大小j为3500,方差var为0.22,每隔回合j为10,实验结果如下表:
根据表1中几个不同模型进行训练对比实验,通过将本文提出的ddpg-ram算法同卷积神经网络(cnn)以及ram模型相比,实验结果表明cnn网络在光照变化情况下对织物缺陷图像分类检测能力较差,而ram对光照变化的干扰有一定的鲁棒性,实验效果比较好,ddpg-ram算法在复杂光照条件下的织物缺陷检测运行速度快,具有更高的准确性,效果会更好。
- 还没有人留言评论。精彩留言会获得点赞!