一种树型检索方法及装置与流程
本发明涉及检索技术领域,尤其涉及一种树型检索方法及装置。
背景技术:
在现今高速发展的信息化社会,如何快速,准确的进行信息检索尤为重要,是舆情分析,信息检索等要解决的难点。比如,进行一篇文章的情感分析,需要基于一个已知词库,对目标文章进行词库检索,并最终将词库的信息准确的匹配到文章上。
现有技术主要是基于词库多次循环检索文章,这样无形中在时间维度上造成过多消耗,最终无法达到令人满意的结果。
技术实现要素:
本发明的目的在于提出一种树型检索方法及装置,能够提高检索效率。
为达此目的,本发明采用以下技术方案:
第一方面,本发明提供了一种树型检索方法,包括:
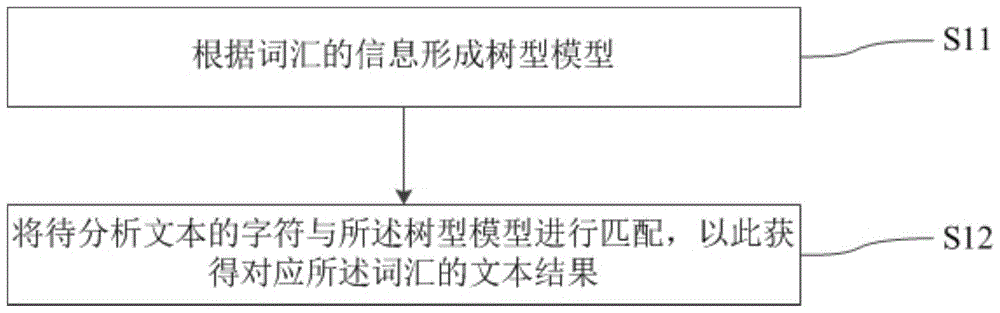
根据词汇的信息形成树型模型;
将待分析文本的字符与所述树型模型进行匹配,以此获得对应所述词汇的文本结果。
进一步的,根据词汇的信息形成树型模型包括:
分割所述词汇成字符,并赋予每个字符对应的子节点;
根据不同词汇之间的关系及所述词汇包含的字数赋予所述子节点对应的状态信息;
根据词汇的信息及所述状态信息赋予对应的子节点词汇含义。
进一步的,所述词汇含义包含标签信息和/或情感信息。
进一步的,所述状态信息为继续、停止或最长。
进一步的,将待分析文本的字符与所述树型模型进行匹配,以此获得对应所述词汇的文本结果,包括:
分割所述待分析文本成字符;
从所述树型模型的根节点的子节点开始,按照所述待分析文本的字符顺序将字符匹配到所述树型模型对应的节点;
若当前字符对应节点的状态信息为继续或停止,则下一个字符从当前字符对应节点的子节点开始匹配;
若当前字符对应节点的状态信息为最长,则将当次匹配结果更新至所述文本结果,并下一个字符重新从所述树型模型的根节点的子节点开始匹配。
进一步的,若当前字符对应节点的状态信息为继续或停止,之前还包括:
若当前字符没有匹配到对应的节点,则递归到下一个字符,并重新从所述根节点的子节点开始匹配。
进一步的,若当前字符对应节点的状态信息为继续或停止,则下一个字符从当前字符对应节点的子节点开始匹配,包括:
若当前字符对应节点的状态信息为继续,则下一个字符从当前字符对应节点的子节点开始匹配;
或若当前字符对应节点的状态信息为停止,则将当次匹配结果添加至文本结果,并下一个字符从当前字符对应节点的子节点开始匹配。
第二方面,本发明提供了一种树型检索装置,包括:
模型建立模块,用于根据词汇的信息形成树型模型;
匹配模块,用于将待分析文本的字符与所述树型模型进行匹配,以此获得对应所述词汇的文本结果。
进一步的,模型建立模块,具体用于分割所述词汇成字符,并赋予每个字符对应的子节点;
根据不同词汇之间的关系及所述词汇包含的字数赋予所述子节点对应的状态信息;
根据词汇的信息及所述状态信息赋予对应的子节点词汇含义。
进一步的,匹配模块,具体用于分割所述待分析文本成字符;
从所述树型模型的根节点的子节点开始,按照所述待分析文本的字符顺序将字符匹配到所述树型模型对应的子节点;
若当前字符对应节点的状态信息为继续或停止,则下一个字符从当前字符对应节点的子节点开始匹配;
若当前字符对应节点的状态信息为最长,则将当次匹配结果更新至所述文本结果,并下一个字符重新从所述树型模型的根节点的子节点开始匹配。
本发明的有益效果为:
本发明根据词汇形成树型模型,以便高效,准确的匹配信息,完成信息检索;并通过将待分析文本的字符与树型模型进行匹配获得文本结果,实现检索一次就将文本与所有词汇进行匹配,从而获得对应的词汇信息,减低匹配的时间。
附图说明
图1是本发明实施例一提供的一种树型检索方法的流程示意图。
图2是本发明实施例二提供的一种树型检索装置的结构示意图。
具体实施方式
为使本发明解决的技术问题、采用的技术方案和达到的技术效果更加清楚,下面将结合附图对本发明实施例的技术方案作进一步的详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
实施例一
本实施例提供了一种树型检索方法,实现检索一次就将文本与所有词汇进行匹配,从而获得对应的词汇信息,减低匹配的时间。
图1是本发明实施例一提供的一种树型检索方法的流程示意图。如图1所示,该方法具体包括如下步骤:
s11,根据词汇的信息形成树型模型。
具体的,首先分割所述词汇成字符,并赋予每个字符对应的子节点。当字符属于同一个词汇,按照在词汇中的顺序将第一个字符设置为根节点的子节点,将第二个字符设置为第一个字符对应节点的子节点,将第三个字符设置为第二个字符对应节点的子节点,如此类推。举个例子进行说明:词汇:中国,将第一个字符:“中”设置为根节点的子节点;将第二个字符:“国”设置为“中”对应节点的子节点。词汇:祖国,将第一个字符:“祖”设置为根节点的子节点;“国”设置为“祖”对应节点的子节点。
一个词汇包含另一个词汇,相同字符共用同一个节点,不同的字符就设置为上一个字符对应节点的子节点,举个例子进行说明:词汇包括:中国,中国人,这两个词汇相同的字符为“中国”,“中”共用同一个节点,“国”共用同一个节点,不同的字符:“人”设置为上一个字符“国”对应节点的子节点。
接着根据不同词汇之间的关系及所述词汇包含的字数赋予所述子节点对应的状态信息。其中,所述状态信息为继续、停止或最长。
举个例子进行说明:词汇:中国,包含2个字符,“中国”的“中”对应节点的状态信息为继续,“国”对应节点的状态信息为“最长”;当出现词汇“中国人”,因该词汇包含另一个词汇“中国”,将原本“国”的节点的状态信息为停止,而“人”的节点的状态信息为最长。
然后根据词汇的信息及所述状态信息赋予对应的子节点词汇含义。所述词汇含义包含标签信息和/或情感信息。
s12,将待分析文本的字符与所述树型模型进行匹配,以此获得对应所述词汇的文本结果。
具体的,首先分割所述待分析文本成字符。以字符为匹配单位。
接着从所述树型模型的根节点的子节点开始,按照所述待分析文本的字符顺序将字符匹配到所述树型模型对应的子节点。
较优的,该方法还包括:若当前字符没有匹配到对应的节点,则递归到下一个字符,并重新从所述根节点的子节点开始匹配。能够把不包含词汇含义的字符排除出去,避免造成文本结果不准确。
若当前字符对应节点的状态信息为继续或停止,则下一个字符从当前字符对应节点的子节点开始匹配。
较优的,若当前字符对应节点的状态信息为继续,则下一个字符从当前字符对应节点的子节点开始匹配。
或若当前字符对应节点的状态信息为停止,则将当次匹配结果添加至文本结果,并下一个字符从当前字符对应节点的子节点开始匹配。
若当前字符对应节点的状态信息为最长,则将当次匹配结果更新至所述文本结果,并下一个字符重新从所述树型模型的根节点的子节点开始匹配。
举个例子进行说明:待分析文本为“我是中国人,我爱我的祖国。”将该文本分割出字符,将该文本分割出的第一个字符“我”从树型模型的根节点的子节点开始匹配,但没有匹配到对应的节点,则递归到下一个字符“是”,依然没有匹配到对应的节点,则递归到下一个字符“中”,当匹配到对应的节点时获取状态信息为继续,然后递归到下一个字符“国”,并在上一个字符“中”对应节点的子节点开始匹配,当匹配到对应的节点时获取状态信息为停止,然后将当次匹配结果“中国”添加至文本结果。因该节点的状态信息为停止,因此递归到下一个字符“人”继续从上一次字符“国”对应节点的子节点开始匹配,当匹配到对应节点时获取状态信息为最长,然后将当次匹配结果“中国人”更新至文本结果。
接着递归到下一个字符“我”并重新从所述树型模型的根节点的子节点开始匹配。如此递归,直至最后一个字符匹配完成。
本实施例根据词汇形成树型模型,以便高效,准确的匹配信息,完成信息检索;并通过将待分析文本的字符与树型模型进行匹配获得文本结果,实现检索一次就将文本与所有词汇进行匹配,从而获得对应的词汇信息,减低匹配的时间。
实施例二
本实施例提供了一种树型检索装置,用于执行上述实施例所述的树型检索方法,解决相同的技术问题,达到相同的技术效果。图2是本发明实施例二提供的一种树型检索装置的结构示意图。如图2所示,该装置包括:
模型建立模块10,用于根据词汇的信息形成树型模型。
进一步,具体用于先分割所述词汇成字符,并赋予每个字符对应的子节点;接着根据不同词汇之间的关系及所述词汇包含的字数赋予所述子节点对应的状态信息;然后根据词汇的信息及所述状态信息赋予对应的子节点词汇含义。
匹配模块20,用于将待分析文本的字符与所述树型模型进行匹配,以此获得对应所述词汇的文本结果。
进一步,具体用于先将分割所述待分析文本成字符;接着从所述树型模型的根节点的子节点开始,按照所述待分析文本的字符顺序将字符匹配到所述树型模型对应的子节点;
若当前字符对应节点的状态信息为继续或停止,则下一个字符从当前字符对应节点的子节点开始匹配;
若当前字符对应节点的状态信息为最长,则将当次匹配结果更新至所述文本结果,并下一个字符重新从所述树型模型的根节点的子节点开始匹配。
本实施例通过模型建立模块,提供高效,准确的匹配信息的基础;并通过模型建立模块与匹配模块的配合,实现检索一次就将文本与所有词汇进行匹配,从而获得对应的词汇信息,减低匹配的时间。
以上结合具体实施例描述了本发明的技术原理。这些描述只是为了解释本发明的原理,而不能以任何方式解释为对本发明保护范围的限制。基于此处的解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明的其它具体实施方式,这些方式都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!