一种基于神经网络技术的视觉语义SLAM系统及方法与流程
本发明属于计算机视觉中的同步定位与建图领域和图像语义领域,具体涉及一种基于神经网络技术的视觉语义slam(simultaneouslocalizationandmapping)系统及方法。
背景技术:
同步定位与地图构建技术,是近几年比较热门的研究领域,该技术能有效解决机器人在未知环境中定位自身,同时感知周围环境这两个主要问题。目前视觉slam经过几十年的发展,已经形成了一套相对传统的成熟框架,如mur-artal等人于2015年提出orb-slam(aversatileandaccuratemonocularslamsystem.ieeetransactionsonrobotics,vol.31,no.5,pp.1147-1163),orb-slam系统中所采用的特征点方法对纹理场景要求较高,建立的空间稀疏点地图包含的信息有限,只有一些低级信息和相对误差的距离,采用的基于图像的词袋库,进行存储和回环检测时,对存储空间和运行速度有一定的限制。
传统slam技术仅包含一些低级信息,无法满足现代计算机视觉的发展,随着人工智能概念的兴起,在图像领域掀起了一股技术热潮,利用神经网络技术实现图像分类,检测,分割等领域都已经在图像的理解等方面胜过传统的图像处理,在自动驾驶、机器人、无人机、医疗等行业都已经初步展现出巨大的优势。
针对神经网络技术在语义理解辅助视觉slam系统的方案,当前仍然存在一些问题,如公告号为cn107833236a(“一种动态环境下结合语义的视觉定位系统和方法”)的发明专利申请,使用修改过的ssd物体检测网络,进行目标检测结合先验信息剔除动态物体,其slam系统仅使用了小型的物体检测网络,与目前优秀的算法仍有一定的距离,另外其对神经网络进行的语义信息未加以利用;又如公告号为cn109559320a(“基于空洞卷积深度神经网络实现视觉slam语义建图功能的方法及系统”)的发明专利申请,其使用基于改进空洞卷积的googlenet神经网络实现对图像的像素级语义分割,结合rgb-d相机的点云信息进行语义建图,实现视觉slam语义建图系统。其创新点在于使用空洞卷积进行语义像素级分割,系统语义信息丰富,但系统仅使用其像素的信息直接在点云中进行语义建图而没进一步使用,语义信息未充分利用,且技术使用单一。
现有的slam技术语义信息相对缺乏且使用单一,纯视觉slam在现实应用中受到环境的限制,需要额外的传感器进行技术融合,比如蓝牙,陀螺仪,红外等设备,形成一个复杂的技术融合slam系统。随着gpu设备的算力和算法开发的与时俱进,为复杂神经网络系统落地提供了落地条件,随着神经网络技术在图像领域应用越来越广泛,对场景的语义信息理解越来越抽象,但目前,仍然没有产生一款完善的、通用的、鲁棒的slam系统。
技术实现要素:
为了解决现有技术中的不足,本发明提出了一种基于神经网络技术的视觉语义slam系统及方法,
本发明所采用的技术方案如下:
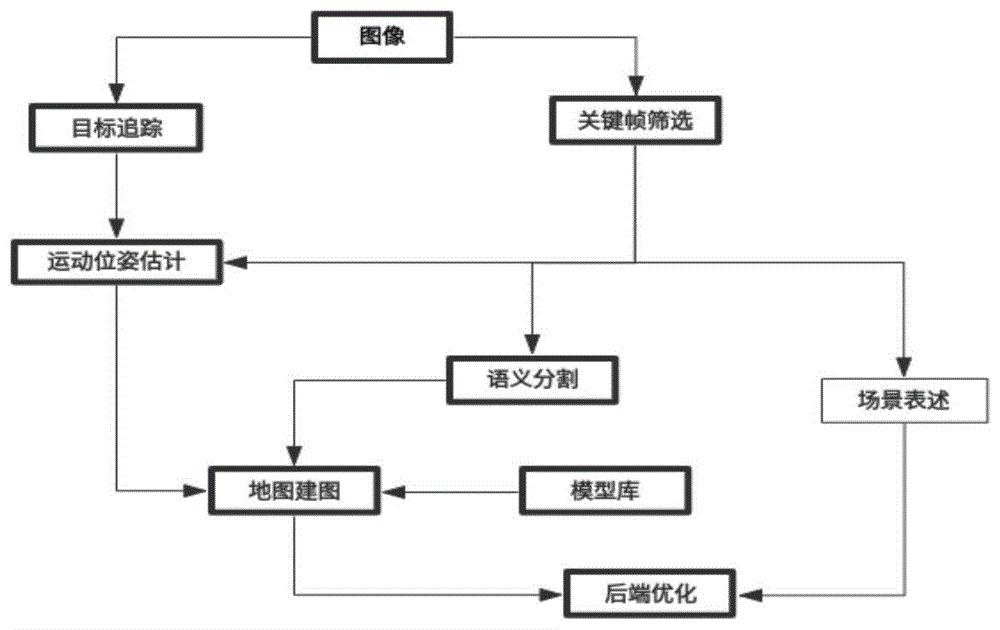
一种基于神经网络技术的视觉语义slam系统,包括目标追踪模块、关键帧筛选模块、运动位姿估计模块、语义分析模块、地图建图模块、场景表述模块和后端优化模块;
所述目标追踪模块接受图片信息,对输入图像序列中的特征进行追踪,产生特征关联匹配信息和特征位置信息;所述目标追踪模块的特征关联匹配信息和特征位置信息输入运动位姿估计模块;
所述关键帧筛选模块从接受的图片信息中选取出一定数量的关键帧,并对关键帧进行筛选生成关键帧队列,所述关键帧筛选模块将关键帧队列分别输入运动位姿估计模块、语义分析模块和场景表述模块;
所述运动位姿估计模块根据接受的特征关联匹配信息、特征位置信息和关键帧队列,通过特征检测网络对特征位置信息进行优化,进而获得相机的位置和姿态信息;所述运动位姿估计模将相机的位置和姿态信息输入地图建图模块;
所述语义分析模块通过enet网络模型对输入的关键帧队列进行快速场景分割,进而获得图像特征像素级的空间信息;所述语义分析模块将空间信息输入地图建图模块;
所述地图建图模块根据相机位置和姿态信息和空间信息,再结合3d模型库信息构建局部地图;并将所构建的局部地图输入后端优化模块;
所述场景表述模块通过深度语义对齐网络模型将输入的关键帧队列进行处理,并生成对关键帧队列内图像内容的描述信息;并将该描述信息输入后端优化模块;
所述后端优化模块不断接收地图建图模块输入的局部地图进而生成全局地图,且对当前关键帧图像的描述信息和场景描述库内的描述信息进行相似度计算,当相似度阈值大于设定阈值时,认为重新回到了曾经到过的地方,即在全局地图上形成回环,实现回环检测,并从全局地图上结合上此地图信息进行地图和位姿的优化。
一种基于神经网络技术的视觉语义slam系统的工作方法,包括如下步骤:
步骤1、从输入图像中选取出关键帧,对关键帧进行筛选生成关键帧队列;
步骤2、对输入图像的特征进行追踪,获得特征关联匹配信息以及特征位置信息
步骤3、根据特征关联匹配信息、特征位置信息和关键帧队列,通过特征检测网络对特征位置信息进行优化,进而获得相机的位置和姿态信息;
步骤4、通过enet网络模型对输入的关键帧队列进行快速场景分割,进而获得图像特征像素级的空间信息;
步骤5、根据相机位置和姿态信息和空间信息,再结合3d模型库内的信息构建局部地图;
步骤6、通过深度语义对齐网络模型将输入的关键帧队列进行处理,并生成对关键帧队列内图像内容的描述信息;
步骤7、将所有进入的局部地图生成全局地图;将当前关键帧图像的描述信息和存储库内的描述信息进行相似度计算,当相似度值大于设定阈值时,认为重新回到了曾经到过的地方,即在全局地图上形成回环,实现回环检测。
进一步,步骤1中获得关键帧队列的方法为:
s1,选出图像的关键帧,将关键帧输入yolo9000目标检测网络,得到关键帧中目标特征的位置和数量,将目标特征的数量与目标特征数量阈值进行比较,若检测特征数量大于目标特征数量阈值则转s2,否者转s4,
s2,将满足s1的关键帧图像送入iqas网络对图像质量进行打分,若关键帧的图像质量大于等于设定的阈值,则认为图像质量合格,则转s3,否者结束
s3,对经过s2筛选后的关键帧图像使用间隔阈值,控制关键帧队列合格关键帧的数量,计算当前合格帧和上一合格帧的时间间隔,设定图像帧隔阈值为200ms,当计算的时间间隔小于图像帧隔阈值时,则将当前帧加入关键帧队列,否者结束;
s4,对满足s1的关键帧图像进行系统最低运行要求判断,以关键帧图像中心为原点,设定原点周围三分之二面积之内的范围为关键区域,将关键区域内的目标特征数量与设定的最低阈值进行比较,当关键区域内的目标特征数量大于最低阈值时,则转入s2,否者结束;
进一步,所述步骤2中利用四元卷积神经网络的多目标跟踪算法对输入图像的特征进行追踪,产生特征关联匹配信息和特征位置信息;
进一步,所述步骤3中获得相机的位置和姿态信息的方法为:
3.1,将特征关联匹配信息、特征位置信息和关键帧队列作为特征检测网络的输入,在本实施例中;
3.2,通过特征检测网络对关键帧队列进一步优化,获得更高精度的特征位置信息和特征的状态信息;
3.3,使用特征关联匹配信息、特征位置信息进行几何位姿估计,进而获得相机的位置和姿态信息;
进一步,所述步骤4中的空间信息分为前景信息和背景信息,所述前景信息是运动位姿估计模块中用于运动位姿估计的目标特征相关信息,包括检测目标特征类别信息、特征边缘信息、特征位置信息、特征相对位置信息、特征空间形状信息;
进一步,所述背景信息包括非用于运动位姿估计的特征信息,如墙面、地面特征等信息;
进一步,所述3d模型库内存储有常见目标特征的3d模型;
进一步,所述步骤6中,将关键帧队列作为深度语义对齐网络的输入,通过深度语义对齐网络(deepvisual-semanticalignmentsforgeneratingimagedescriptions)对关键帧队列进行处理,生成对图像内容的描述,并按照关键帧队列图像顺序设置索引存入描述索引库中。
本发明的有益效果:
1、本发明所设计的视觉语义slam系统通过目标追踪模块、关键帧筛选模块、运动位姿估计模块、语义分析模块、地图建图模块、场景表述模块和后端优化模块之间的相互协作,共同作用,产生了一种新颖完善的视觉语义slam系统方案。该方案的各模块对系统运行具有独特的含义;其中:关键帧筛选模块通过合理的逻辑筛选策略,使系统能够运行在低纹理场景中;运动位姿估计模块为系统提供精确的特征位置信息,使系统的定位精度大幅度提高;语义分析模块通过场景分割得到特征的像素级空间信息,使系统具有更精确的地图和更丰富的语义信息;场景表述模块通过对场景的理解得到场景内容的表述,使系统具有更迅速和有效的回环检测。
2、本发明关键帧筛选的规则是根据图像采集设备的性能参数、目标特征数量的多少以及图像质量的高低;通过设计合理的逻辑筛选策略,即通过利用yolo9000特征检测网络和iqas质量评定网络进行高质量的关键帧判定流程;从而形成高质量的关键帧列队,才能使系统能够运行在低纹理场景中。
3、本发明位姿估计的方法是先利用特征检测网络(fasterrcnn)获得精确的特征位置信息再进行位姿的估计,从而获得更精确的相机位置变化,才能使系统的定位精度大幅度提高。
4、本发明语义分析的方法是利用enet网络获得特征像素级的空间信息,从而加深对环境语义的理解,才能使系统具有更精确的地图和更丰富的语义信息。5、本文明场景表述的方法是利用深度语义对齐网络获得图像内容的描述信息,进而生成图像描述的索引库,才能使系统具有更迅速和有效的回环检测,形成了回环检测方式的一种新的扩展。
附图说明
图1为本发明slam系统框架图;
图2为本发明关键帧筛选策略流程图;
图3为本发明语义分析效果图;
图4为本发明gazebo平台地面和墙面参考效果图;
图5为本发明gazebo平台建图效果图;
图6为本发明场景表述效果参考图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
如图1所示的一种基于神经网络技术的视觉语义slam系统,包括目标追踪模块、关键帧筛选模块、运动位姿估计模块、语义分析模块、地图建图模块、场景表述模块和后端优化模块;
目标追踪模块接受图片信息,利用四元卷积神经网络的多目标跟踪(multi-objecttrackingwithquadrupletconvolutionalneuralnetworks)算法对输入图像序列中的特征进行追踪,不断在相邻帧之间产生特征关联匹配信息和特征位置信息;目标追踪模块的特征关联匹配信息和特征位置信息输入运动位姿估计模块;
根据图像采集设备的帧率信息设置初步关键帧选取间隔,取帧间隔为二到五,即二帧取一帧、三帧取一帧、四帧取一帧等,关键帧筛选模块从接受的图片信息中选取出一定数量的关键帧,并对关键帧进行筛选生成关键帧队列,关键帧筛选模块将关键帧队列分别输入运动位姿估计模块、语义分割模块和场景表述模块;在本实施例中,图像采集设备的相机帧率为60fps,设置取帧间隔为四,即初步筛选的关键帧数量为15fps。
在运动位姿估计模块内,将所接受的特征关联匹配信息、特征位置信息和关键帧队列作为特征检测网络(fasterrcnn)的输入,通过特征检测网络(fasterrcnn)对特征位置信息进行优化,进而获得相机的位置和姿态信息;运动位姿估计模将相机的位置和姿态信息输入地图建图模块。
语义分析模块通过enet网络模型对输入的关键帧队列进行快速场景分割,进而获得图像特征像素级的空间信息;语义分析模块将空间信息输入地图建图模块;
地图建图模块根据相机位置和姿态信息和空间信息,再结合3d模型库信息进行局部地图构建;并将所构建的局部地图输入后端优化模块;
场景表述模块通过深度语义对齐网络模型将输入的关键帧队列进行处理,并生成对关键帧队列内图像内容的描述信息;并将该描述信息输入后端优化模块;
后端优化模块不断接收地图建图模块输入的局部地图进而生成全局地图,且对当前关键帧图像的描述信息和存储库内的描述信息进行相似度计算,当相似度大于设定阈值时,认为重新回到了曾经到过的地方,即在全局地图上形成回环,实现回环检测,并从全局地图上结合上此地图信息进行地图和位姿的优化。
一种基于神经网络技术的视觉语义slam系统的工作方法,包括如下步骤:
步骤1、从输入图像中选取出关键帧,对关键帧进行筛选生成关键帧队列;如图2所示步骤1中获得关键帧队列的方法为:
s1,选出图像的关键帧,将关键帧输入yolo9000目标检测网络,得到关键帧中目标特征的位置和数量,将目标特征的数量与目标特征数量阈值进行比较,若检测特征数量大于目标特征数量阈值则转s2,否者转s4,
s2,将初步选出的关键帧图像送入iqas网络对图像质量进行打分,若关键帧的图像质量大于等于设定的阈值则认为图像质量合格,则转s3,否者结束;其中设定的阈值为4分;
s3,对经过s2筛选的关键帧图像使用间隔阈值,控制关键帧队列合格关键帧的数量,计算当前合格帧和上一合格帧的时间间隔,设定图像帧隔阈值为200ms,当计算的时间间隔小于图像帧隔阈值时,则将当前帧加入关键帧队列,否者结束;
s4,对s1获得特定初选关键帧再次进行系统最低运行要求判断,设定以图像中心为原点,设定原点周围三分之二面积之内的范围为关键区域,将关键区域内的目标特征数量与设定的最低阈值进行比较,当关键区域特征数量大于最低阈值时,则转入s2进行下一流程,否者结束,最低阈值为1。
步骤2、利用四元卷积神经网络多目标跟踪(multi-objecttrackingwithquadrupletconvolutionalneuralnetworks)算法对输入图像的特征进行检测并进行追踪,不断在相邻帧之间产生特征关联匹配信息和特征位置信息。
步骤3、根据特征关联匹配信息和关键帧队列,通过特征检测网络对特征位置信息进行优化,进而获得相机的位置和姿态信息;具体过程为:
s1,将特征关联匹配信息、特征位置信息和关键帧队列作为输入,特征检测网络是以网络hrnetv2p(high-resolutionrepresentationsforlabelingpixelsandregions)为基础网络的fasterrcnn(towardsreal-timeobjectdetectionwithregionproposalnetworks)算法组成;首先,关键帧队列经过特征检测网络(fasterrcnn)进行特征检测和特征的状态信息的预测,进而获得更精确的目标特征位置信息和状态信息;在经过特征检测网络处理之前的目标特征位置信息误差为5~8个像素附近,而经过特征检测网络处理之后的目标特征位置信息误差为2~3个像素附近,由此可以看出本申请中利用特征检测网络可以对目标特征位置信息进行有效的优化,能够产生精确的目标特征匹配信息,后转入位姿估计过程s2。
s2,位姿估计过程为系统开始运行时,从关键帧队列中获得第一张关键帧,再获得第二张关键帧,此时的第一张关键帧为上一帧,第二张关键帧为当前关键帧,对这两张关键帧进行几何位姿估计,以产生相机的位置和姿态信息。
步骤4、通过enet网络模型对输入的关键帧队列进行快速场景分割,进而获得图像特征像素级的空间信息;如图3所示效果,其中区域1为门的分割区域,区域2为地面的分割区域,区域3为凳子的分割区域,区域4为墙的分割区域,实现对背景和前景的分离以及目标物进行空间上的分割,产生类型和空间上的信息。
步骤5、根据相机位置和姿态信息和空间信息,再结合3d模型库内的信息构建局部地图;具体过程为:获取相机的位置、姿态信息、空间信息,首先由空间信息建立所在场景前景和背景信息,如图4、5所示墙面和地面等非特征以及桌子、凳子等特征,其中在建立场景的前景特征信息时,会在模型库内搜索相应特征3d模型,再利用其空间信息中的相对位置以及状态信息建立地图。
步骤6、通过深度语义对齐网络模型将输入的关键帧队列进行处理,并生成对关键帧队列内图像内容的描述信息;由上述模块1)获得关键帧队列图像,基于生成图像描述的深度语义对齐网络产生对图像内容的描述,如图6所示效果,将生成的图像内容的描述信息按照关键帧队列图像顺序设置索引存入场景描述库中,建立场景描述索引库。
步骤7、将地图建图模块产生的局部地图不断输入生成全局地图;将当前关键帧图像的描述信息和场景描述库内的描述信息进行相似度计算,相似度计算的方法为:首先使用新闻、百度百科数据训练64维的词向量(word2vec)模型,将当前关键帧图像的描述信息和场景描述库内的描述信息分别输入词向量模型,产生对应的词向量,将当前关键帧图像对应的词向量与场景描述库内所有描述信息对应的词向量分别进行匹配计算,获得对应的相似度,当当相似度值大于设定阈值0.95时,认为重新回到了曾经到过的地方,即在全局地图上形成回环,实现回环检测。通过回环检测能够对全局地图内的信息进行优化。
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!