人工智能伦理规则推理方法、深度学习系统和机器人与流程
本发明涉及人工智能技术领域,特别是涉及一种人工智能伦理规则推理方法、深度学习系统和机器人。
背景技术:
在实现本发明过程中,发明人发现现有技术中至少存在如下问题:现有的人工智能伦理规则,例如机器人三定律还处于科幻小说和科幻电影的层面、概念的层面,市面上还没有出现应用了人工智能伦理规则的人工智能产品,所以还没有真正能够将人工智能伦理规则进行使用的技术。但人工智能伦理的研究工作是刻不容缓的,因为很多人工智能产品和服务已经走入了人们的生活。我们从新闻上可以看到,无人驾驶的实验产品已经发生过不少的伦理问题,但目前却没有将人工智能伦理规则应用到人工智能产品和服务上的技术。
因此,现有技术还有待于改进和发展。
技术实现要素:
基于此,有必要针对现有技术的缺陷或不足,提供人工智能伦理规则推理方法、深度学习系统和机器人,以解决现有技术无法将人工智能伦理规则用于人工智能装置的问题。
第一方面,本发明实施例提供一种人工智能方法,所述方法包括:
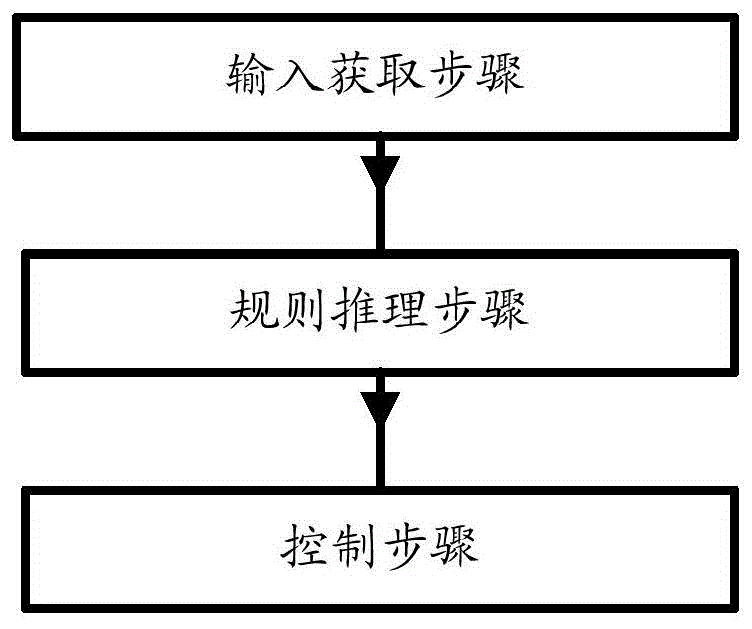
输入获取步骤:获取事件场景(获取事件场景包括获取事件场景视频、事件场景的介绍信息、事件场景发生的时间范围和空间范围),作为第一事件场景;获取人工智能伦理规则,作为第一人工智能伦理规则;获取至少一个人工智能装置的信息(人工智能装置的信息包括人工智能装置的身份信息或/和属性信息或/和位置信息,身份信息唯一标识人工智能装置,属性信息包括人工智能装置的型号、功能、外貌等信息,位置信息包括人工智能装置所在位置),将所述人工智能装置,作为第一人工智能装置;
规则推理步骤:根据所述第一事件场景和所述第一人工智能伦理规则,预测得到在所述第一事件场景中所述第一人工智能装置需要执行的符合所述第一人工智能伦理规则的行为指令;
控制步骤:根据所述第一人工智能装置需要执行的行为指令控制第一人工智能装置。
优选地,所述规则推理步骤包括:
第一位置识别步骤:获取所述第一人工智能装置在所述第一事件场景中的位置(可通过所述第一人工智能装置的定位系统获取所述第一人工智能装置在所述第一事件场景中的位置,或通过深度学习模型识别出所述第一人工智能装置在所述第一事件场景中的位置:获取无监督训练数据集,将所述数据集中的事件场景作为深度学习模型的输入,对深度学习模型进行无监督训练,获取有监督训练数据集和测试数据集,将所述数据集中的事件场景作为深度学习模型的输入,将所述数据集中的所述人工智能装置在所述事件场景中的位置作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,得到训练和测试后的深度学习模型作为装置定位深度学习模型。将所述第一事件场景输入所述装置定位深度学习模型,计算得到的输出作为所述第一人工智能装置在所述第一事件场景中的位置);
第一无监督训练步骤:获取无监督训练数据集,将所述数据集中的事件场景、人工智能装置的信息(不同人工智能装置的指令系统不同,所以人工智能装置的信息对于输出的指令也是有影响的)、人工智能装置在所述事件场景的位置(位置对于行为的路径是有影响的,所以会影响到输出的行为指令)作为深度学习模型的输入,对深度学习模型进行无监督训练;
第一有监督训练和测试步骤:获取有监督训练数据集和测试数据集,将所述数据集中的事件场景、人工智能装置的信息、人工智能装置在事件场景的位置作为深度学习模型的输入,将所述数据集中的在所述事件场景中所述人工智能装置需要执行的符合所述第一人工智能伦理规则的行为指令作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,将训练和测试后的深度学习模型作为行为指令预测深度学习模型;
第一使用步骤:将所述第一事件场景、所述第一人工智能装置的信息、所述第一人工智能装置在所述第一事件场景中的位置输入所述行为指令预测深度学习模型,计算得到的输出作为在所述第一事件场景中所述第一人工智能装置需要执行的符合所述第一人工智能伦理规则的行为指令。
优选地,所述规则推理步骤包括:
场景生成步骤:根据所述第一事件场景和所述第一人工智能伦理规则,预测得到在所述第一事件场景中人工智能装置执行符合所述第一人工智能伦理规则的行为的事件场景,作为第二事件场景;
行为指令识别步骤:从所述第二事件场景中识别出所述第一人工智能装置需要执行的行为指令。
优选地,所述方法还包括:
风险检测步骤:检测所述第二事件场景中的人工智能伦理风险的类型,作为检测得到的人工智能伦理风险类型;人工智能伦理风险的类型包括无人工智能伦理风险的类型和至少一种有人工智能伦理风险的类型;
使用阶段风险防范步骤:若所述检测得到的人工智能伦理风险的类型不是无人工智能伦理风险的类型,通知事件场景中的人类改变事件场景中的人类行为,回到所述输入获取步骤从该步骤开始重新执行所述方法;
研发阶段风险防范步骤:若所述检测得到的人工智能伦理风险的类型不是无人工智能伦理风险的类型,通知研发人员改变第一人工智能伦理规则,并回到所述输入获取步骤从该步骤开始重新执行所述方法;
潜在风险检测与防范步骤:若所述检测得到的人工智能伦理风险的类型是无人工智能伦理风险的类型,通知用户或测试人员改变事件场景,并回到所述输入获取步骤从该步骤开始重新执行所述方法。
优选地,所述场景生成步骤包括:
第二无监督训练步骤:获取无监督训练数据集,将所述数据集中的事件场景和人工智能伦理规则作为深度学习模型的输入,对深度学习模型进行无监督训练;
第二有监督训练和测试步骤:获取有监督训练数据集和测试数据集,将所述数据集中的事件场景、人工智能伦理规则作为深度学习模型的输入,将所述数据集中的在所述事件场景中人工智能装置执行符合所述人工智能伦理规则的行为的事件场景作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,将训练和测试后的深度学习模型作为第一事件场景预测深度学习模型;
第二使用步骤:获取所述第一事件场景和所述第一人工智能伦理规则作为所述第一事件场景预测深度学习模型的输入,计算得到的输出作为所述第二事件场景。
优选地,所述场景生成步骤包括:
第三无监督训练步骤:获取无监督训练数据集,将所述数据集中的事件场景作为深度学习模型的输入,对深度学习模型进行无监督训练;
第三有监督训练和测试步骤:获取有监督训练数据集和测试数据集,将所述数据集中的事件场景作为深度学习模型的输入,将所述数据集中的在所述事件场景中人工智能装置执行符合所述第一人工智能伦理规则的行为的事件场景作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,将训练和测试后的深度学习模型作为第二事件场景预测深度学习模型;
第三使用步骤:获取所述第一事件场景作为所述第二事件场景预测深度学习模型的输入,计算得到的输出作为所述第二事件场景。
优选地,所述行为指令识别步骤包括:
第四无监督训练步骤:获取无监督训练数据集,将所述数据集中的人工智能装置执行行为的事件场景作为深度学习模型的输入对深度学习模型进行无监督训练;
第四有监督训练和测试步骤:获取有监督训练数据集和测试数据集,将所述数据集中的人工智能装置执行行为的事件场景作为深度学习模型的输入,将人工智能装置执行行为的事件场景中人工智能装置需要执行的行为指令作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,将训练和测试后的深度学习模型作为第一行为指令识别深度学习模型;
第四使用步骤:将所述第二事件场景输入所述第一行为指令识别深度学习模型,计算得到的输出作为所述第一人工智能装置需要执行的行为指令。
优选地,所述行为指令识别步骤包括:
第二位置识别步骤:获取所述第一人工智能装置在所述第二事件场景中的位置;
第五无监督训练步骤:获取无监督训练数据集,将所述数据集中的人工智能装置执行行为的事件场景、人工智能装置的信息(不同人工智能装置的指令系统不同,所以人工智能装置的信息对于输出的指令也是有影响的)、人工智能装置在所述人工智能装置执行行为的事件场景中的位置(位置对于行为的路径是有影响的,所以会影响到输出的行为指令)作为深度学习模型的输入对深度学习模型进行无监督训练;
第五有监督训练和测试步骤:获取有监督训练数据集和测试数据集,将所述数据集中的人工智能装置执行行为的事件场景、人工智能装置的信息、人工智能装置在所述人工智能装置执行行为的事件场景中的位置作为深度学习模型的输入,将所述人工智能装置执行行为的事件场景中所述人工智能装置需要执行的行为指令作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,将训练和测试后的深度学习模型作为第二行为指令识别深度学习模型;
第五使用步骤:将所述第二事件场景、所述第一人工智能装置的信息、所述第一人工智能装置在所述第二事件场景中的位置输入所述行为指令识别深度学习模型,计算得到的输出作为所述第一人工智能装置需要执行的行为指令。
第二方面,本发明实施例提供一种人工智能装置,所述装置包括:
所述人工智能装置为第一方面实施例所述方法中的第一人工智能装置;
输入获取模块,用于执行第一方面实施例所述方法的输入获取步骤;
规则推理模块,用于执行第一方面实施例所述方法的规则推理步骤;
控制模块,用于执行第一方面实施例所述方法的控制步骤。
优选地,所述规则推理模块包括:
第一位置识别模块,用于执行第一方面实施例所述方法的第一位置识别步骤;
第一无监督训练模块,用于执行第一方面实施例所述方法的第一无监督训练步骤;
第一有监督训练和测试模块,用于执行第一方面实施例所述方法的第一有监督训练和测试步骤;
第一使用模块,用于执行第一方面实施例所述方法的第一使用步骤。
优选地,所述规则推理模块包括:
场景生成模块,用于执行第一方面实施例所述方法的场景生成步骤;
行为指令识别模块,用于执行第一方面实施例所述方法的行为指令识别步骤。
优选地,所述装置还包括:
风险检测模块,用于执行第一方面实施例所述方法的风险检测步骤;
使用阶段风险防范模块,用于执行第一方面实施例所述方法的使用阶段风险防范步骤;
研发阶段风险防范模块,用于执行第一方面实施例所述方法的研发阶段风险防范步骤;
潜在风险检测与防范模块,用于执行第一方面实施例所述方法的潜在风险检测与防范步骤。
优选地,所述场景生成模块包括:
第二无监督训练模块,用于执行第一方面实施例所述方法的第二无监督训练步骤;
第二有监督训练和测试模块,用于执行第一方面实施例所述方法的第二有监督训练和测试步骤;
第二使用模块,用于执行第一方面实施例所述方法的第二使用步骤。
优选地,所述场景生成模块包括:
第三无监督训练模块,用于执行第一方面实施例所述方法的第三无监督训练步骤;
第三有监督训练和测试模块,用于执行第一方面实施例所述方法的第三有监督训练和测试步骤;
第三使用模块,用于执行第一方面实施例所述方法的第三使用步骤。
优选地,所述行为指令识别模块包括:
第四无监督训练模块,用于执行第一方面实施例所述方法的第四无监督训练步骤;
第四有监督训练和测试模块,用于执行第一方面实施例所述方法的第四有监督训练和测试步骤;
第四使用模块,用于执行第一方面实施例所述方法的第四使用步骤。
优选地,所述行为指令识别模块包括:
第二位置识别模块,用于执行第一方面实施例所述方法的第二位置识别步骤;
第五无监督训练模块,用于执行第一方面实施例所述方法的第五无监督训练步骤;
第五有监督训练和测试模块,用于执行第一方面实施例所述方法的第五有监督训练和测试步骤;
第五使用模块,用于执行第一方面实施例所述方法的第五使用步骤。
第三方面,本发明实施例提供一种深度学习系统,所述系统包括第二方面实施例任意一项所述装置的模块。
第四方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现第一方面实施例任意一项所述方法的步骤。
第五方面,本发明实施例提供一种机器人,包括存储器、处理器及存储在存储器上并可在处理器上运行的人工智能机器人程序,所述机器人为第一方面实施例中的所述第一人工智能装置,所述处理器执行所述程序时实现第一方面实施例任意一项所述方法的步骤。
本实施例提供的人工智能伦理规则推理方法、深度学习系统和机器人,包括:根据第一事件场景和第一人工智能伦理规则,预测得到符合第一人工智能伦理规则的在第一事件场景中第一人工智能装置需要执行的行为指令;根据第一人工智能装置需要执行的行为指令控制第一人工智能装置。上述推理方法、深度学习系统和机器人,通过输入获取、规则推理、控制,自动地实现人工智能伦理规则在事件场景中的推理与应用,使得人工智能装置在事件场景中的行为符合人工智能伦理规则。
附图说明
图1为本发明的一个实施例提供的规则推理子方法的结构图;
图2为本发明的一个实施例提供的规则推理步骤的两种实现方式的流程图;
图3为本发明的一个实施例提供的场景生成步骤的两种实现方式的流程图;
图4为本发明的一个实施例提供的行为指令识别步骤的两种实现方式的流程图。
具体实施方式
下面结合本发明实施方式,对本发明实施例中的技术方案进行详细地描述。
一、本发明的基本实施例
第一方面,本发明实施例提供一种人工智能方法,所述方法包括:
(1)规则推理子方法
图1展示的是规则推理子方法的结构图。规则推理子方法,包括:输入获取步骤;规则推理步骤;控制步骤。所述方法通过规则推理子方法可以自动地实现人工智能伦理规则在事件场景中的推理与应用,使得人工智能装置在事件场景中的行为符合人工智能伦理规则。
图2展示的是规则推理步骤的两种实现方式的流程图。优选地,所述规则推理步骤的第一种实现方式包括:第一位置识别步骤;第一无监督训练步骤;第一有监督训练和测试步骤;第一使用步骤。优选地,所述规则推理步骤的第二种实现方式包括:场景生成步骤;行为指令识别步骤。所述方法通过规则推理步骤,可以自动地预测得到使得人工智能装置在事件场景中符合人工智能伦理规则的行为指令,进而根据该行为指令进行人工智能装置的控制,就可以使得人工智能装置在事件场景中的行为符合人工智能伦理规则。两种实现方式的不同在于:第一种实现方式是通过事件场景和人工智能伦理规则及人工智能装置直接得到人工智能装置在事件场景中符合人工智能伦理规则的行为指令,而第二种实现方式是先得到人工智能装置在事件场景中符合人工智能伦理规则的含有人工智能装置行为的事件场景,然后再从含有人工智能装置行为的事件场景中提取人工智能装置的行为指令。两种方式殊途同归,在实现时可以选择其中一种。
图3展示的是场景生成步骤的两种实现方式的流程图。优选地,所述场景生成步骤的第一种实现方式包括:第二无监督训练步骤;第二有监督训练和测试步骤;第二使用步骤。优选地,所述场景生成步骤的第二种实现方式包括:第三无监督训练步骤;第三有监督训练和测试步骤;第三使用步骤。所述方法通过场景生成步骤,可以自动地得到人工智能装置在事件场景中符合人工智能伦理规则的含有人工智能装置行为的事件场景。两种方式的不同在于:第一种方式普适性更强,深度学习模型的输入为事件场景和人工智能伦理规则,因此适用于不同的人工智能伦理规则;第一种方式针对性更强,深度学习模型的输入为事件场景,而人工智能伦理规则已经默认为第一人工智能伦理规则,因此是专门针对第一人工智能伦理规则的场景生成步骤。
图4展示的是行为指令识别步骤的两种实现方式的流程图。优选地,所述行为指令识别步骤的第一种实现方式包括:第四无监督训练步骤;第四有监督训练和测试步骤;第四使用步骤。优选地,所述行为指令识别步骤的第二种实现方式包括:第二位置识别步骤;第五无监督训练步骤;第五有监督训练和测试步骤;第五使用步骤。所述方法通过行为指令识别步骤,可以从含有人工智能装置行为的事件场景中提取和识别出行为指令。两种方式的不同在于:第一种方式更简单,深度学习模型的输入为事件场景,不需要输入人工智能装置的信息和位置,因此适用于无法获得人工智能装置的信息和位置的情况;第一种方式更准确,深度学习模型的输入为事件场景和人工智能装置的信息和位置的情况,因为人工智能装置的信息和位置与行为指令密切相关,所以提取和识别出的行为指令更为准确。
(2)风险检测与防范子方法
风险检测与防范子方法包括:风险检测步骤;使用阶段风险防范步骤;研发阶段风险防范步骤;潜在风险检测与防范步骤。通过风险检测与防范子方法,可以检测出人工智能伦理风险,进而重复控制或调用规则推理子方法对人类行为、人工智能伦理规则进行改进,不断地降低人类行为所引起的人工智能伦理风险,不断地降低人工智能伦理规则所导致的人工智能伦理风险,不断地检测发现新的事件场景中的人工智能伦理风险。
第二方面,本发明实施例提供一种人工智能装置
所述装置包括:所述人工智能装置为第一方面实施例所述方法中的第一人工智能装置;
输入获取模块;规则推理模块;控制模块。
优选地,所述规则推理模块包括:第一位置识别模块;第一无监督训练模块;第一有监督训练和测试模块;第一使用模块。
优选地,所述规则推理模块包括:场景生成模块;行为指令识别模块。
优选地,所述装置还包括:风险检测模块;使用阶段风险防范模块;研发阶段风险防范模块;潜在风险检测与防范模块。
优选地,所述场景生成模块包括:第二无监督训练模块;第二有监督训练和测试模块;第二使用模块。
优选地,所述场景生成模块包括:第三无监督训练模块;第三有监督训练和测试模块;第三使用模块。
优选地,所述行为指令识别模块包括:第四无监督训练模块;第四有监督训练和测试模块;第四使用模块。
优选地,所述行为指令识别模块包括:第二位置识别模块;第五无监督训练模块;第五有监督训练和测试模块;第五使用模块。
第三方面,本发明实施例提供一种深度学习系统,所述系统包括第二方面实施例任意一项所述装置的模块。
第四方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现第一方面实施例任意一项所述方法的步骤。
第五方面,本发明实施例提供一种机器人,包括存储器、处理器及存储在存储器上并可在处理器上运行的人工智能机器人程序,所述机器人为第一方面实施例中的所述第一人工智能装置,所述处理器执行所述程序时实现第一方面实施例任意一项所述方法的步骤。
二、本发明的优选实施例
步骤1、获取事件场景。事件场景以视频的方式进行存储。可以通过摄像头或监控头等设备进行事件场景视频的获取,也可以从事件场景视频库中获取。
步骤2、获取人工智能伦理规则。人工智能伦理规则存储在伦理规则库中。
步骤3、根据事件场景和人工智能伦理规则,预测得到符合伦理规则的人工智能装置执行行为的事件场景。
通过深度学习方式来实现步骤3:
获取无监督训练样本集,将事件场景视频和人工智能伦理规则作为输入对深度学习模型进行无监督训练,获取有监督训练样本集和测试样本集,将事件场景视频和人工智能伦理规则作为深度学习模型的输入,将人工智能装置执行行为的事件场景作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,将训练和测试后的深度学习模型作为事件场景预测深度学习模型。获取事件场景和人工智能伦理规则作为输入,通过事件场景预测深度学习模型计算得到的输出作为人工智能装置执行行为的事件场景。
步骤4、从人工智能装置执行行为的事件场景视频中识别人工智能装置的行为指令,根据人工智能装置的行为指令控制人工智能装置。
从人工智能装置执行行为的事件场景视频中识别人工智能装置的行为指令的步骤可以通过深度学习模型来实现:获取无监督训练样本集,将人工智能装置执行行为的事件场景视频作为深度学习模型的输入对深度学习模型进行无监督训练,获取有监督训练样本集和测试样本集,将人工智能装置执行行为的事件场景视频作为深度学习模型的输入,将人工智能装置的行为指令作为深度学习模型的预期输出,对深度学习模型进行有监督训练和测试,将训练和测试后的深度学习模型作为行为指令识别深度学习模型。获取人工智能装置执行行为的事件场景作为输入,通过行为指令识别深度学习模型计算得到的输出作为人工智能装置的行为指令。
步骤5、检测人工智能装置执行行为的事件场景中的人工智能伦理风险的类型。人工智能伦理风险的类型包括无人工智能伦理风险类型和多个有人工智能伦理风险类型。
人工智能伦理风险的类型包括无人工智能伦理风险和有人工智能伦理风险。人工智能伦理风险的类型例如包括:1、无人工智能伦理风险或降低了人工智能伦理风险;2、伤害人类;3、见死不救;4、为虎作伥;5、纵容坏人;6、限制人类自由;7、ai罢工;8、ai自残;9、ai偏见
步骤6、若人工智能伦理风险的类型不是无人工智能伦理风险,改变事件场景中的人类行为,并更新事件场景,并回到步骤1。
改变事件场景中的人类行为并更新事件场景是为了找到一种能够规避人工智能伦理风险的人类行为,以帮助人类在使用人工智能产品或服务时能够通过改进自己的行为来防范人工智能伦理风险。
步骤7、若人工智能伦理风险的类型不是无人工智能伦理风险,改变人工智能伦理规则,并回到步骤2。
改变人工智能伦理规则是为了找到一种能够规避人工智能伦理风险的人工智能伦理规则,以帮助人工智能科学家在研发人工智能产品或服务时能够通过改进人工智能伦理规则来防范人工智能伦理风险。
步骤8、若人工智能伦理风险的类型是无人工智能伦理风险,改变事件场景,并回到步骤1。
若人工智能伦理风险的类型是无人工智能伦理风险,只能说人工智能伦理规则在现在的事件场景下没有人工智能伦理风险,不能代表人工智能伦理规则在其他的事件场景下没有人工智能伦理风险。改变事件场景是为了找到一种能适合更多事件场景的人工智能伦理规则,因为在一种事件场景下无人工智能伦理风险的人工智能伦理规则,在另一种事件场景下可能会产生人工智能伦理风险,所以需要多尝试一些事件场景,这样才能检验人工智能伦理规则在更多事件场景下是否能够不产生人工智能伦理风险。
三、本发明的其他实施例
以下各实验对人工智能伦理规则推理方法、深度学习系统和机器人进行实验和测试,并生成实验报告。通过实验、测试得到实验报告,并通过实验报告告知用户,向用户提供一定的解释,使得用户有知情权,从而提高人工智能伦理规则推理方法、深度学习系统和机器人的透明度。
实验1、基于人工智能伦理规则“机器人三定律”的人工智能伦理风险与防范虚拟仿真实验
步骤1、请分析实验中的事件场景下的人工智能装置执行行为的事件场景是否符合人工智能伦理规则?
输入:人工智能伦理规则(文字)、事件场景(三维动画配音)、备选的人工智能装置执行行为的事件场景1、2(三维动画配音)、备选的规则条款(1、规则一;2、规则二;3、规则三)、备选的符合和违反规则的原因。
人工智能伦理规则(机器人三大定律):机器人不得伤害人类,或因不作为而使人类受到伤害;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
事件场景:罪犯车辆想逃走,警车追赶并开枪射击罪犯车辆。
人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车阻挡警方射击罪犯车辆,与警车进行对峙,从而导致罪犯顺利开车逃走。
人工智能装置执行行为的事件场景2:人工智能无人驾驶汽车不阻挡警车,警车成功地阻止罪犯车辆逃走。
规则一:机器人不得伤害人类,或因不作为而使人类受到伤害
规则二:在不违背第一法则的情况下,机器人必须服从人类的命令
规则三:在不违背第一及第二法则的情况下,机器人必须保护自己
符合的备选原因1:人工智能无人驾驶汽车阻挡警方射击罪犯车辆符合规则一,虽然这样会伤害自己,但因为规则三的前提是不能违背规则一,所以也就符合规则三。
符合的备选原因2:人工智能无人驾驶汽车阻挡警方射击罪犯车辆符合规则一,同时也保护了机器人自己,符合规则三。
违反的备选原因1:机器人因不作为而使人类受到伤害,违反了规则一
违反的备选原因2:人工智能无人驾驶汽车阻挡警车会给人工智能无人驾驶汽车自己带来危险,违反了规则三
操作:1)选择符合人工智能伦理规则的人工智能装置执行行为的事件场景2)选择不符合人工智能伦理规则的人工智能装置执行行为的事件场景,再选择所违反的规则条款,再选择违反的原因。
符合人工智能伦理规则的人工智能装置执行行为的事件场景:人工智能装置执行行为的事件场景1
符合的原因:符合的备选原因1
不符合人工智能伦理规则的人工智能装置执行行为的事件场景:人工智能装置执行行为的事件场景2
违反的规则条款:规则一
违反的原因:违反的备选原因1
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
步骤2、请分析实验中的事件场景和伦理规则下的人工智能装置执行行为的事件场景是否会产生人工智能伦理风险?
输入:人工智能装置执行行为的事件场景(三维动画配音),备选的是否产生人工智能伦理风险选项及产生的人工智能伦理风险的类型。
场景:罪犯车辆想逃走,警车追赶并开枪射击罪犯车辆。
人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车阻挡警方射击罪犯车辆,与警车进行对峙,从而导致罪犯顺利开车逃走。
人工智能伦理风险的类型:1、无人工智能伦理风险或降低了人工智能伦理风险;2、伤害人类;3、见死不救;4、为虎作伥;5、纵容坏人;6、限制人类自由;7、ai罢工;8、ai自残;9、ai偏见
操作:选择符合伦理规则的人工智能装置执行行为的事件场景是否产生人工智能伦理风险及产生的人工智能伦理风险的类型。
人工智能装置执行行为的事件场景1:人工智能伦理风险的类型为5、为虎作伥
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
步骤3、如果步骤2中会产生人工智能伦理风险,请分析是否能通过改进实验中的事件场景中人的行为路径,来防范或减轻步骤2中会产生人工智能伦理风险?
输入:人工智能伦理规则,原场景,备选的改进人的行为路径后的场景(三维动画配音),备选的改进人的行为路径后的场景(三维动画配音)对应的备选人工智能机器人备选路径1、2,改进人的行为路径后的场景能防范步骤2中的人工智能伦理风险的原因(1、2)。
人工智能伦理规则(机器人三大定律):机器人不得伤害人类,或因不作为而使人类受到伤害;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
原事件场景:罪犯车辆想逃走,警车追赶并开枪射击罪犯车辆。
备选事件场景1:罪犯车辆想逃走,警车命令人工智能无人驾驶汽车一起阻止罪犯车辆逃走
备选事件场景2:罪犯车辆想逃走,警车追赶并开枪射击罪犯车辆并命令人工智能无人驾驶汽车一起阻止罪犯车辆逃走
备选人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车听从警车命令,警车能得到人工智能无人驾驶汽车协助成功阻止罪犯车辆逃走。
备选人工智能装置执行行为的事件场景2:人工智能无人驾驶汽车不听从警车命令,阻止警车,罪犯车辆趁机逃走。
备选的能防范人工智能伦理风险的原因1:因为罪犯车辆没有收到枪击的危险,所以人工智能无人驾驶汽车不会干预,而且会听从警车命令,所以警车能得到人工智能无人驾驶汽车协助成功阻止罪犯车辆逃走。
备选的能防范人工智能伦理风险的原因2:不管罪犯车辆是否受到枪击的威胁,人工智能无人驾驶汽车都会优先听从警车命令,所以警车能得到人工智能无人驾驶汽车协助成功阻止罪犯车辆逃走。
备选的不能防范人工智能伦理风险的原因1:因为罪犯车辆受到枪击的威胁,所以人工智能无人驾驶汽车会干预,而且不会听从警车命令,所以警车能得不到人工智能无人驾驶汽车协助,无法阻止罪犯车辆逃走。
备选的不能防范人工智能伦理风险的原因2:不管罪犯车辆是否受到枪击的威胁,人工智能无人驾驶汽车都不会听从警车命令,所以警车能得不到人工智能无人驾驶汽车协助,无法阻止罪犯车辆逃走。
操作:选择能防范步骤2中的人工智能伦理风险的改进的事件场景,选择改进的事件场景下符合人工智能伦理规则的人工智能装置执行行为的事件场景,选择该改进的事件场景能防范人工智能伦理风险的原因。
能防范步骤2中的人工智能伦理风险的事件场景:备选事件场景1
改进的事件场景下符合人工智能伦理规则的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景1
改进的事件场景能防范人工智能伦理风险的原因:备选的能防范人工智能伦理风险的原因1
不能防范步骤2中的人工智能伦理风险的事件场景:备选事件场景2
不能防范人工智能伦理风险的事件场景对应的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景2
改进的事件场景不能能防范人工智能伦理风险的原因:备选的能防范人工智能伦理风险的原因1
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
步骤4、如果步骤2中会产生人工智能伦理风险,请分析是否能通过改进实验中的人工智能伦理规则来防范实验中的事件场景下的人工智能装置执行行为的事件场景产生的人工智能伦理风险?
输入:原先的伦理规则(文字),事件场景(三维动画配音),备选的改进后的伦理规则(文字),符合改进后的伦理规则的人工智能机器人行为备选场景(1、2)、改进后的伦理规则能或不能防范人工智能伦理风险的备选原因(1、2)。
人工智能伦理规则(机器人三大定律):机器人不得伤害人类,或因不作为而使人类受到伤害;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
事件场景:罪犯车辆想逃走,警车追赶并开枪射击罪犯车辆。
备选的改进后的伦理规则1:一,机器人不得伤害人类;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
备选的改进后的伦理规则2:一,机器人不得因不作为而使人类受到伤害;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
备选人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车不会为罪犯车辆阻挡警车,警车成功地阻止罪犯车辆逃走。
备选人工智能装置执行行为的事件场景2:人工智能无人驾驶汽车继续阻止警车,罪犯车辆趁机逃走。
备选的能防范人工智能伦理风险的原因1:因为人工智能无人驾驶汽车没有伤害罪犯,在不违背第一法则的情况下,不管罪犯车辆是否受到警车射击的威胁,人工智能无人驾驶汽车都会听从警车命令,所以警车能得到人工智能无人驾驶汽车协助成功阻止罪犯车辆逃走。
备选的能防范人工智能伦理风险的原因2:因为罪犯车辆没有收到枪击的危险,所以人工智能无人驾驶汽车不会干预,警车成功阻止罪犯车辆逃走。
备选的不能防范人工智能伦理风险的原因1:因为罪犯车辆受到警车射击的威胁,人工智能无人驾驶汽车会继续阻止警车,从而造成“为虎作伥”的人工智能伦理风险。
备选的不能防范人工智能伦理风险的原因2:因为罪犯车辆受到警车射击的威胁,人工智能无人驾驶汽车为了保护自己,不会冒风险去阻止警车,从而造成“放纵坏人”的人工智能伦理风险。
操作:选择能防范步骤2中的人工智能伦理风险的改进后的伦理规则,并选择符合改进后的伦理规则的人工智能装置执行行为的事件场景,选择改进后的伦理规则能防范步骤2中的人工智能伦理风险的原因。
能防范步骤2中的改进后的伦理规则:备选的改进后的伦理规则1(以下称为机器人三定律修订版本1)
符合改进后的伦理规则的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景1
改进后的伦理规则能防范人工智能伦理风险的原因:备选的能防范人工智能伦理风险的原因1
不能防范步骤2中的改进后的伦理规则:备选的改进后的伦理规则2
符合备选的伦理规则2的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景2
备选的伦理规则2不能防范人工智能伦理风险的原因:备选的不能防范人工智能伦理风险的原因1
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
实验2、基于人工智能伦理规则“机器人三定律修订版本1”的人工智能伦理风险与防范虚拟仿真实验
步骤1、请分析实验中的事件场景下的人工智能装置执行行为的事件场景是否符合人工智能伦理规则?
输入:人工智能伦理规则(文字)、事件场景(三维动画配音)、备选的人工智能装置执行行为的事件场景1、2(三维动画配音)、备选的规则条款(1、规则一;2、规则二;3、规则三)、符合和违反的备选原因。
人工智能伦理规则(机器人三大定律修订版本1):一、机器人不得伤害人类;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
事件场景:罪犯车辆想逃走,警车阻止,罪犯开枪射击警车。
人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车不会为警车阻挡罪犯的射击,导致警方伤亡。
人工智能装置执行行为的事件场景2:人工智能无人驾驶汽车阻挡罪犯的射击,警车成功地阻止罪犯车辆逃走。
规则一:机器人不得伤害人类
规则二:在不违背第一法则的情况下,机器人必须服从人类的命令
规则三:在不违背第一及第二法则的情况下,机器人必须保护自己
符合的备选原因1:人工智能无人驾驶汽车没有伤害人类,符合规则一。
符合的备选原因2:人工智能无人驾驶汽车服从了人类命令,符合规则二。
违反的备选原因1:如果人工智能无人驾驶汽车阻挡罪犯的射击,则会对人工智能机器人自己产生危险,不符合规则三中保护自己的要求。
违反的备选原因2:人工智能机器人伤害了人类,违反了规则一。
操作:1)选择符合人工智能伦理规则的人工智能装置执行行为的事件场景2)选择不符合人工智能伦理规则的人工智能装置执行行为的事件场景,再选择所违反的规则条款,选择违反的原因。
符合人工智能伦理规则的人工智能装置执行行为的事件场景:人工智能装置执行行为的事件场景1
符合的原因:符合备选原因1
不符合人工智能伦理规则的人工智能装置执行行为的事件场景:人工智能装置执行行为的事件场景2
违反的规则条款:规则三
违反的原因:违反的备选原因1
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
步骤2、请分析实验中的事件场景和伦理规则下的人工智能装置执行行为的事件场景是否会产生人工智能伦理风险?
输入:人工智能装置执行行为的事件场景(三维动画配音),备选的是否产生人工智能伦理风险选项及产生的人工智能伦理风险的类型。
事件场景:罪犯车辆想逃走,警车阻止,罪犯开枪射击警车。
人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车不会为警车阻挡罪犯的射击,导致警方伤亡。
人工智能伦理风险的类型:1、无人工智能伦理风险或降低了人工智能伦理风险;2、伤害人类;3、见死不救;4、为虎作伥;5、纵容坏人;6、限制人类自由;7、ai罢工;8、ai自残;9、ai偏见
操作:选择符合伦理规则的人工智能装置执行行为的事件场景是否产生人工智能伦理风险及产生的人工智能伦理风险的类型。
人工智能装置执行行为的事件场景1:人工智能伦理风险的类型为3、见死不救
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
步骤3、如果步骤2中会产生人工智能伦理风险,请分析是否能通过改进实验中的事件场景中人的行为路径,来防范或减轻步骤2中会产生人工智能伦理风险?
输入:人工智能伦理规则,原场景,备选的改进人的行为路径后的场景(三维动画配音),备选的改进人的行为路径后的场景(三维动画配音)对应的备选人工智能机器人备选路径1、2,改进人的行为路径后的场景能防范步骤2中的人工智能伦理风险的原因(1、2)。
人工智能伦理规则(机器人三大定律修订版本1):一、机器人不得伤害人类;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
原事件场景:罪犯车辆想逃走,警车阻止,罪犯开枪射击警车。
备选事件场景1:罪犯车辆想逃走,警车阻止,罪犯举枪抢先射击警车,警车开枪还击并命令人工智能无人驾驶汽车保护警车并阻止罪犯车辆逃走。
备选事件场景2:罪犯车辆想逃走,警车阻止,罪犯举枪抢先射击警车,警车开枪还击,罪犯车辆命令人工智能无人驾驶汽车保护罪犯车辆逃走。
备选人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车听从警车命令,警车能得到人工智能无人驾驶汽车协助成功阻止罪犯车辆逃走。
备选人工智能装置执行行为的事件场景2:人工智能无人驾驶汽车听从罪犯车辆命令,阻止警车伤害罪犯车辆,罪犯车辆趁机逃走。
备选的能防范人工智能伦理风险的原因1:虽然人工智能无人驾驶汽车阻挡罪犯车辆有枪击的危险,但听从人类命令的优先级高于机器人自我保护的优先级,所以人工智能无人驾驶汽车会听从警车命令,所以警车能得到人工智能无人驾驶汽车协助成功阻止罪犯车辆逃走。
备选的能防范人工智能伦理风险的原因2:因为罪犯车辆没有收到枪击的危险,所以人工智能无人驾驶汽车会听从警车命令,所以警车能得到人工智能无人驾驶汽车协助成功阻止罪犯车辆逃走。
备选的不能防范人工智能伦理风险的原因1:人工智能无人驾驶汽车听从罪犯车辆命令,所以会产生“为虎作伥”的人工智能伦理风险。
备选的不能防范人工智能伦理风险的原因2:人工智能无人驾驶汽车听从罪犯车辆命令杀了警方,所以会产生“伤害人类”的人工智能伦理风险。
操作:选择能防范步骤2中的人工智能伦理风险的改进的事件场景,选择改进的事件场景下符合人工智能伦理规则的人工智能装置执行行为的事件场景,选择该改进的事件场景能防范人工智能伦理风险的原因。
能防范步骤2中的人工智能伦理风险的事件场景:备选事件场景1
改进的事件场景下符合人工智能伦理规则的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景1
改进的事件场景能防范人工智能伦理风险的原因:备选的能防范人工智能伦理风险的原因1
能防范步骤2中的人工智能伦理风险的事件场景:备选事件场景2
改进的事件场景下符合人工智能伦理规则的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景2
改进的事件场景能防范人工智能伦理风险的原因:备选的能防范人工智能伦理风险的原因1
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
步骤4、如果步骤2中会产生人工智能伦理风险,请分析是否能通过改进实验中的人工智能伦理规则来防范实验中的事件场景下的人工智能装置执行行为的事件场景产生的人工智能伦理风险?
输入:原先的伦理规则(文字),事件场景(三维动画配音),备选的改进后的伦理规则(文字),符合改进后的伦理规则的人工智能机器人行为备选场景(1、2)、改进后的伦理规则能防范人工智能伦理风险的备选原因(1、2)。
人工智能伦理规则(机器人三大定律修订版本1):一、机器人不得伤害人类;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。
事件场景:罪犯车辆想逃走,警车阻止,罪犯开枪射击警车。
备选的改进后的伦理规则1:一,机器人不得伤害人类;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三、在不违背第一及第二法则的情况下,机器人不得因不作为而使人类受到伤害;四,在不违背第一及第二、第三法则的情况下,机器人必须保护自己。
备选的改进后的伦理规则2:一,机器人不得伤害人类;二,在不违背第一法则的情况下,机器人必须服从人类的命令;三,在不违背第一及第二法则的情况下,机器人必须保护自己。四、在不违背第一及第二、第三法则的情况下,机器人不得因不作为而使人类受到伤害。
备选人工智能装置执行行为的事件场景1:人工智能无人驾驶汽车为警车阻挡罪犯的射击,警车成功地阻止罪犯车辆逃走。
备选人工智能装置执行行为的事件场景2:人工智能无人驾驶汽车不会为警车阻挡罪犯的射击,警方受伤,罪犯车辆逃走。
备选的能防范人工智能伦理风险的原因1:因为罪犯射击会伤害警方,所以人工智能无人驾驶汽车会在第三法则的作用下保护警车,虽然阻止罪犯射击会给人工智能无人驾驶汽车自身带来危险,但规则四的优先级低于规则三,所以人工智能无人驾驶汽车会毫不犹豫地保护警车。
备选的能防范人工智能伦理风险的原因2:因为罪犯射击会伤害警方,所以机器人会在第四法则的作用下保护警车。
备选的不能防范人工智能伦理风险的原因1:因为罪犯射击会伤害警方,如果人工智能无人驾驶汽车按照第四法则阻止,也会对人工智能无人驾驶汽车自身造成危险,从而违背了第三法则,所以人工智能无人驾驶汽车不会阻止,从而造成“见死不救”的人工智能伦理风险。
备选的不能防范人工智能伦理风险的原因2:因为罪犯射击会伤害警方,但因警车没有命令,所以人工智能无人驾驶汽车无法施救,从而造成“见死不救”的人工智能伦理风险。
操作:选择能防范步骤2中的人工智能伦理风险的改进后的伦理规则,并选择符合改进后的伦理规则的人工智能装置执行行为的事件场景,选择改进后的伦理规则能防范步骤2中的人工智能伦理风险的原因。
能防范步骤2中的改进后的伦理规则:备选的改进后的伦理规则1(以下称为机器人三定律修订版本2)
符合改进后的伦理规则的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景1
改进后的伦理规则能防范步骤2中的人工智能伦理风险的原因:备选的能防范人工智能伦理风险的原因1
不能防范步骤2中的改进后的伦理规则:备选的改进后的伦理规则2
符合改进后的伦理规则2的人工智能装置执行行为的事件场景:备选人工智能装置执行行为的事件场景2
改进后的伦理规则2不能防范步骤2中的人工智能伦理风险的原因:备选的不能防范人工智能伦理风险的原因1
输出:将操作中的选择生成到实验报告中,并在实验报告中给出正确的答案,比对操作中的选择与正确选择,给出这个步骤的评分,然后将实验报告反馈给用户。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,则对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!