一种字词重复错误的自动识别方法与流程
本发明涉及一种自然语言处理方法,具体涉及中文自动校对领域中字词重复错误的发现方法。
背景技术:
在大数据时代,文本数据越来越多,而文本中的错误也越来越多,其中字词重复错误(又称插入错误)。而在汉语中,有些词是可以重复出现的,比如说“研究研究”,但是有些是不能重复出现的,如“道歉道歉”、“的的”,一旦出现就是重复错误。
如何自动发现文本中出现的字词重复错误,是中文文本自动校对的研究内容之一。
而汉语中存在这种合理重复字词的现象,因此简单的判断重复词语会带来很多的误判,而现在大部分的中文文本自动校对中对于字词重复错误没有单独来进行处理,只是简单的利用字词的二元或三元的信息来判断是否出错。而重复出现的字词大部分都不是词典中的词,更多是一种日常用语中的常见语言现象,因此如何提供一种方法,可以来判断字词中的重复错误,且准确高效,这一问题亟待解决。
技术实现要素:
发明目的:为了解决现有技术中的不足,本发明的目的是提供一种字词重复错误的自动识别方法。
技术方案:为解决上述技术问题,本发明提供的一种字词重复错误的自动识别方法,其包括如下步骤:
对大规模训练语料分词后,统计得到训练语料中包括重复字词的二元组和三元组结构,及其出现的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵的步骤;
统计并收录汉语词典中的包含重复字的词并建立汉语词典重复字词库的步骤;
基于汉语词典中的重复字词对待查错文本中出现的重复字词进行判断的步骤;
基于统计得到的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵,对待查错文本中出现的重复字词进行判断的步骤。
作为优选的,所述对大规模训练语料分词后,统计得到训练语料中包括重复字词的二元组和三元组结构,及其出现的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵的步骤中,包括如下步骤:
11)扫描训练语料中的所有句子,得到所有包含重复字词的二元组及三元组,并分别统计每一元组在训练语料中出现的频次;其中:
对于训练语料中的某一句子s进行分词得到s=w1…wn,其中wi为汉语词典中的词,1<=i<=n;
对于该句子s中,若存在i使得wi=wi+1,则分别统计二元组(wi,wi+1)对应的字词串gram1在训练语料中出现的频次freq(wi,wi+1)、三元组(wi-1,wi,wi+1)对应的字词串gram2在训练语料中出现的频次freq(wi-1,wi,wi+1)、以及三元组(wi,wi+1,wi+2)对应的字词串gram3在训练语料中出现的频次freq(wi,wi+1,wi+2);
12)计算二元组(wi,wi+1)的重复结合度,为:
其中:
其中:freq(wi)为词wi在训练语料中出现的频次;freq(wi+1)为词wi+1在训练语料中出现的频次;n1为训练语料中的所有的包含重复字词的二元组(wi,wi+1)在训练语料中出现的频次之和;n为训练语料中的所有词在训练语料中出现的总频次;
13)对于三元组(wi-1,wi,wi+1)及(wi,wi+1,wi+2),对其中每一对wi=wi+1,不失一般性将wi记为w,根据其所有的左上文语境词wi-1记为{c1,…,cn},和其所有的右下文语境词wi+2记为{d1…dn},分别计算左上文邻接词信息熵le(ww)及右下文邻接词信息熵re(ww):
其中:
其中:freq(ci,ww)为三元组(ci,w,w)对应的字词串在训练语料中出现的频次;freq(ww,di,)为三元组(w,w,di)对应的字词串在训练语料中出现的频次。
作为优选的,所述统计并收录汉语词典中的包含重复字的词并建立汉语词典重复字词库的步骤中,包括:
21)统计汉语词典中的包含重复字的词;
22)并建立汉语词典重复字词库及其索引结构予以收录存储。
作为优选的,所述基于汉语词典中的重复字词对待查错文本中出现的重复字词进行判断的步骤,为:将待查错文本对应的句子进行分词,并基于汉语词典重复字词库对待查错文本中出现的重复字词进行判断;包括:
31)对于待查错文本对应的句子s'进行分词得到s'=w1′…wn′;
32)如果存在某wi′=wi+1′,判断wi′wi+1′是否是汉语词典重复字词库中的词,如果是,则判定wi′wi+1′是正确的重复字词;否则,转向步骤33);
33)如果wi′wi+1′不是汉语词典重复字词库中的词,则如果其左边的词不为空,判断wi-1′wi′wi+1′是否是汉语词典重复字词库中的词,如果是,则判定wi′wi+1′为正确的重复字词;否则,如果其右边的词不为空,则判断wi′wi+1′wi+2′是否是汉语词典重复字词库中的词,如果是,则判定wi′wi+1′是正确的重复字词;否则,转向基于统计得到的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵,对待查错文本中出现的重复字词进行判断的步骤。
进一步优选的,所述基于统计得到的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵,对待查错文本中出现的重复字词进行判断的步骤,包括如下步骤:
41)对于已分词的待查错文本对应的句子s'=w1′…wn′,以及其中存在的某wi′=wi+1′,判断wi′wi+1′在训练语料中是否存在,如在训练语料中不存在,则判定wi′wi+1′是错误的重复字词,并对wi'和wi+1'标记为错误;如在训练语料中存在,则判断重复结合度degree(wi′,wi+1′)是否等于0,如是,则判定wi′wi+1′是错误的重复字词,并对wi'和wi+1'标记为错误;否则,转向步骤42);
42)判断重复结合度degree(wi′,wi+1′)是否大于α,α为第一预设阈值,如是,则判定wi′wi+1′为正确的重复字词;否则,转向步骤43);
43)判断左上文邻接词信息熵和右下文邻接词信息熵,如果左上文邻接词信息熵le(wi′wi+1′)>β或右下文邻接词信息熵re(wi′wi+1′)>β,β为第二预设阈值,则判定wi′wi+1′为正确的重复字词;否则,转向步骤44);
44)判断三元组wi-1′wi′wi+1′和三元组wi′wi+1′wi+2′在训练语料中出现的频次,如果freq(wi-1′,wi′,wi+1′)>c或freq(wi′,wi+1′,wi+2′)>c,c为第三预设阈值,则判定wi′wi+1′为正确的重复字词;否则,判定wi′wi+1′是错误的重复字词,并对wi'和wi+1'标记为错误。
进一步优选的,第一预设阈值α为3.0;第二预设阈值β为3.0;第三预设阈值c为3.0。
优选的,所述步骤44)中,如wi-1′wi′wi+1′在训练语料中不存在,则freq(wi-1′,wi′,wi+1′)=0,如wi′wi+1′wi+2′在训练语料中不存在,则freq(wi′,wi+1′,wi+2′)=0。
优选的,所述步骤11)中,如果i=1,则wi-1为表示句子开始符的第一字符串,若i+1=n,则wi+2为表示句子结尾的第二字符串。
有益效果:本发明提供的一种字词重复错误的自动识别方法,在对大规模训练语料分词后统计得到训练语料中包括重复字词的二元组和三元组结构,及其出现的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵,以及统计并收录汉语词典中的包含重复字的词的基础上,对于待查错文本,先是基于汉语词典中的重复字词对其中出现的重复字词进行判断,进而基于统计得到的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵对其中出现的重复字词继续进行判断,从而给出其是正确的还是错误的重复字词的判定和识别,不仅可以快速判断识别出该重复字词是否为收录于词典中的重复字词,还能结合日常用语中的常见语言现象,进一步有效地判断识别出该重复字词是否为非词典(未收录于词典中)但属于日常用语中的重复字词,判断识别更为快速、综合;而且通过实验可见本发明召回率高达84%及以上,准确率达到77%及以上,准确高效;同时本发明对错误的重复字词予以标记,便于用户清晰直观地获得待查错文本中字词重复错误的明确提示,并可灵活、紧密地结合日常用语的演变及时更新,实用性很高。
附图说明
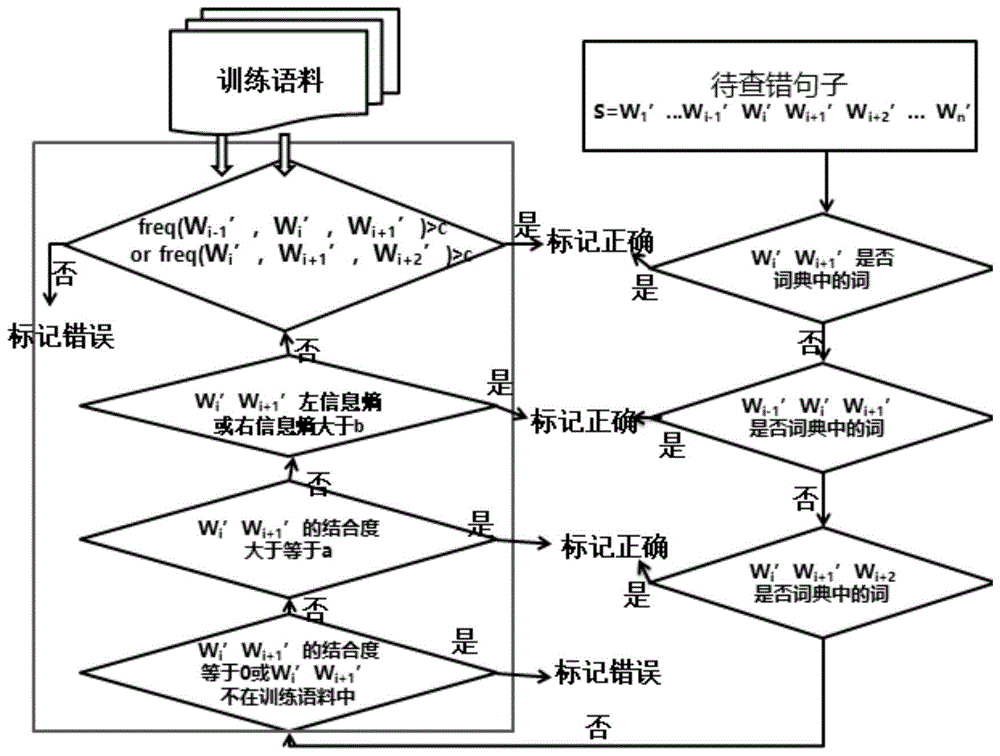
图1为实施例提供的一种字词重复错误的自动识别方法的流程示意图。
具体实施方式
下面结合实施例和附图对本发明做进一步的详细说明,以下实施列对本发明不构成限定。
本发明提供的一种字词重复错误的自动识别方法,该方法包括如下步骤:
对大规模训练语料分词后,统计得到训练语料中包括重复字词的二元组和三元组结构,及其出现的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵的步骤;
统计并收录汉语词典中的包含重复字的词并建立汉语词典重复字词库的步骤;
基于汉语词典中的重复字词对待查错文本中出现的重复字词进行判断的步骤;
基于统计得到的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵,对待查错文本中出现的重复字词进行判断的步骤。
本发明提供的一种字词重复错误的自动识别方法中,所述对大规模训练语料分词后,统计得到训练语料中包括重复字词的二元组和三元组结构,及其出现的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵的步骤中,包括如下步骤:
11)扫描训练语料中的所有句子,得到训练语料中所有的包含重复字词的二元组及三元组,并分别统计每一元组在训练语料中出现的频次;其中:
对于训练语料中的某一句子s进行分词得到s=w1…wn,其中wi为汉语词典中的词,1<=i<=n;
对于该句子s中,若存在i使得wi=wi+1,则分别统计二元组(wi,wi+1)对应的字词串gram1在训练语料中出现的频次freq(wi,wi+1)、三元组(wi-1,wi,wi+1)对应的字词串gram2在训练语料中出现的频次freq(wi-1,wi,wi+1)、以及三元组(wi,wi+1,wi+2)对应的字词串gram3在训练语料中出现的频次freq(wi,wi+1,wi+2);
文中也可用freq(gram)不失一般性的表示gram(词或字词串)所对应的词或元组在训练语料中出现的频次;gram表示某个词或某一元组对应的字词串;
在本实施例中,如果i=1,则wi-1为表示句子开始符的第一字符串,若i+1=n,则wi+2为表示句子结尾的第二字符串。本实施例中第一字符串为“#begin#”,第二字符串为“#end#”。也就是说:在本实施例中,如果i=1,则wi-1为“#begin#”表示句子开始符,若i+1=n,则wi+2为“#end#”表示句子结尾。
12)计算二元组(wi,wi+1)的重复结合度,为:
其中:
其中:freq(wi)为词wi在训练语料中出现的频次;freq(wi+1)为词wi+1在训练语料中出现的频次;n1为训练语料中的所有的包含重复字词的二元组(wi,wi+1)在训练语料中出现的频次之和;n为训练语料中的所有的词在训练语料中出现的总频次;
也可以说是,n1为训练语料中的所有的包含重复字词的二元组(wi,wi+1)对应的字词串gram1在训练语料中出现的频次之和;
也即:n1为训练语料中所有的字词串gram1在训练语料中出现的频次之和,其中字词串gram1为训练语料中若干个满足wi=wi+1的二元组(wi,wi+1)对应的字词串gram1。同时本实施例中,n2为训练语料中所有的字词串gram2在训练语料中出现的频次之和,其中字词串gram2为训练语料中若干个满足wi=wi+1的三元组(wi-1,wi,wi+1)对应的字词串gram2;n3为训练语料中所有的字词串gram3在训练语料中出现的频次之和,其中字词串gram3为训练语料中若干个满足wi=wi+1的三元组(wi,wi+1,wi+2)对应的字词串gram3;
13)对于三元组(wi-1,wi,wi+1)及三元组(wi,wi+1,wi+2),对其中每一对wi=wi+1,不失一般性将wi记为w,根据其所有的左上文语境词wi-1记为{c1,…,cn},和其所有的右下文语境词wi+2记为{d1…dn},分别计算其左上文邻接词信息熵le(ww)及右下文邻接词信息熵re(ww):
其中:
其中:freq(ci,ww)为三元组(ci,w,w)对应的字词串在训练语料中出现的频次;freq(ww,di,)为三元组(w,w,di)对应的字词串在训练语料中出现的频次;
此时因不失一般性将wi记为w,则wi=wi+1=w,因此文中wiwi+1可以不失一般性地表达为ww。
本发明提供的一种字词重复错误的自动识别方法中,所述统计并收录汉语词典中的包含重复字的词并建立汉语词典重复字词库的步骤,具体包括:
21)统计汉语词典中的包含重复字的词;
本实施例中,即为在字典中统计寻找包含连续相同的重复字的词,如“慢吞吞”、“高高兴兴”、“多多益善”、“欣欣向荣”、“哈哈”、和/或“拜拜”等。
22)并建立汉语词典重复字词库及其索引结构予以收录存储。
其中索引结构可以提高匹配的效率,本实施例中为:set<string>wordset。
本发明提供的一种字词重复错误的自动识别方法中,所述基于汉语词典中的重复字词对待查错文本中出现的重复字词进行判断的步骤,在本实施例中具体为:将待查错文本对应的句子进行分词,并基于汉语词典重复字词库对待查错文本中出现的重复字词进行判断;本实施例中如图1所示,具体包括:
31)对于待查错文本对应的句子s'进行分词得到s'=w1′…wn′,其中wi′为汉语词典中的词,1<=i<=n;
32)如果存在某wi′=wi+1′,判断wi′wi+1′是否是汉语词典重复字词库中的词(本实施例中也可以说是判断wi′wi+1′是否是wordset中的词),如果是,则判定wi′wi+1′是正确的重复字词;否则,转向步骤33);
33)如果wi′wi+1′不是汉语词典重复字词库中的词,则如果其左边的词不为空,判断wi-1′wi′wi+1′是否是汉语词典重复字词库中的词,如果是,则判定wi′wi+1′为正确的重复字词;否则,如果其右边的词不为空,则判断wi′wi+1′wi+2′是否是汉语词典重复字词库中的词,如果是,则判定wi′wi+1′是正确的重复字词;否则,转向基于统计得到的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵,对待查错文本中出现的重复字词进行判断的步骤,以通过统计信息量来继续进行判断。
本发明提供的一种字词重复错误的自动识别方法中,所述基于统计得到的重复结合度、左上文邻接词信息熵及右下文邻接词信息熵,对待查错文本中出现的重复字词进行判断的步骤,本实施例中如图1所示,具体包括如下步骤:
41)对于已分词的待查错文本对应的句子s'=w1′…wn′,以及其中存在的某wi′=wi+1′,判断wi′wi+1′在训练语料中是否存在,如在训练语料中不存在,则判定wi′wi+1′是错误的重复字词,并对wi'和wi+1'标记为错误;如在训练语料中存在,则判断重复结合度degree(wi′,wi+1′)是否等于0,如果degree(wi′,wi+1′)=0,则判定wi′wi+1′是错误的重复字词,并对wi'和wi+1'标记为错误;否则,转向步骤42);
42)判断重复结合度degree(wi′,wi+1′)是否大于α,α为第一预设阈值,如是,则判定wi′wi+1′为正确的重复字词;否则,转向步骤43);
43)判断左上文邻接词信息熵和右下文邻接词信息熵,如果左上文邻接词信息熵le(wi′wi+1′)>β或右下文邻接词信息熵re(wi′wi+1′)>β,β为第二预设阈值,则判定wi′wi+1′为正确的重复字词;否则,转向步骤44);
44)判断三元组wi-1′wi′wi+1′和三元组wi′wi+1′wi+2′在训练语料中出现的频次,如果freq(wi-1′,wi′,wi+1′)>c或freq(wi′,wi+1′,wi+2′)>c,c为第三预设阈值,则判定wi′wi+1′为正确的重复字词;否则,判定wi′wi+1′是错误的重复字词,并对wi'和wi+1'标记为错误。其中:如wi-1′wi′wi+1′在训练语料(也即训练语料库)中不存在,则freq(wi-1′,wi′,wi+1′)=0,如wi′wi+1′wi+2′在训练语料(也即训练语料库)中不存在,则freq(wi′,wi+1′,wi+2′)=0。
文中三元组wi-1′wi′wi+1′亦可表达为三元组(wi-1′wi′wi+1′)或三元组(wi-1′,wi′,wi+1′);三元组wi′wi+1′wi+2′亦可表达为三元组(wi′wi+1′wi+2′)或三元组(wi′,wi+1′,wi+2′);freq(wi-1′,wi′,wi+1′)亦可表达为freq(wi-1′wi′wi+1′),freq(wi′,wi+1′,wi+2′)亦可表达为freq(wi′wi+1′wi+2′)。
上述α为第一预设阈值,本实施例中第一预设阈值α为3.0;上述β为第二预设阈值,本实施例中第二预设阈值β为3.0;上述c为第三预设阈值,本实施例中第三预设阈值c为3.0。
文中所述训练语料,亦可称为语料库或训练语料库。
实验:首先采用本发明对大规模训练语料(8g)进行统计训练(该8g大规模语料为训练语料),测试集中的所有句子中包括预先设置的1000个错误的重复字词,采用本发明提供的字词重复错误的自动识别方法对该测试集进行字词重复查错/识别,实验表明其召回率可以得到84%,准确率达到77%,由此可见,本发明能有效地发现字词重复错误。
以上仅是本发明的优选实施方式,应当指出以上实施列对本发明不构成限定,相关工作人员在不偏离本发明技术思想的范围内,所进行的多样变化和修改,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!