一种面向电商排名销量映射关系的曲线拟合估计方法与流程
本发明属于曲线拟合估计方法技术领域,具体涉及一种面向电商排名销量映射关系的曲线拟合估计方法。
背景技术:
为了估计电商平台排名和销量之间的映射关系,我们面对的样本点存在两个问题:噪音点多,一般的异常点清洗方法不起作用;样本不足,分布不均匀。传统的基于损失函数的指数函数拟合或者多次线性拟合方法,无法达成拟合优度目标。为此,我们提出一种面向电商排名销量映射关系的曲线拟合估计方法,以解决上述背景技术中提到的问题。
技术实现要素:
本发明的目的在于提供一种面向电商排名销量映射关系的曲线拟合估计方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种面向电商排名销量映射关系的曲线拟合估计方法,其特征在于,包括如下步骤:
s1:过滤掉y为0的样本;
s2:对原始数据进行分箱处理,生成新的更为稀疏的样本点,即新样本点;
s3:对于新样本点中出现的非单调性情况,基于曲线的非线性、单调递减的特点,得到最终的单调递减新样本点;
s4:基于单调三次样条插值方法(monotonepiecewisecubicinterpolation),得到相邻两个新样本点之间的插值计算公式,对样本点内的映射关系进行插值计算,最终得到了目标曲线。
优选的,所述分箱方法具体为:
y:2n,n∈[0,1,2,3,4,5……100];
x:[x1,x2,x3……],xi是基于y分类数据组的中间值,如果数据个数为偶数,则是两个中间数值和的一半。
优选的,所述最终的单调递减新样本点的获取方法具体为:
对x、y排序,得到新变量x-rank、y-rank;
x-rank是基于x升序得到的顺序序号,y-rank是基于y降序得到的顺序序号;
估计x-rank、y-rank的一元线性方程,在不存在噪音、异常值的情况下,x、y存在严格单调递减的关系,该方程为y-rank=x-rank;
计算离群点因子阈值,移除大于离群点因子阈值的点,如果新的样本点不符合单调递减原则,则不断缩小离群点因子阈值,直到新的样本符合单调性。
优选的,所述目标曲线具有x是连续整数、单调递减、对全局一阶导数无连续性或一致性要求的特征。
与现有技术相比,本发明的有益效果是:本发明提供的一种面向电商排名销量映射关系的曲线拟合估计方法,本发明噪音点少,得到的曲线拟合优度大于传统的非线性拟合方法的占比为84.9%,可达到拟合优度目标。
附图说明
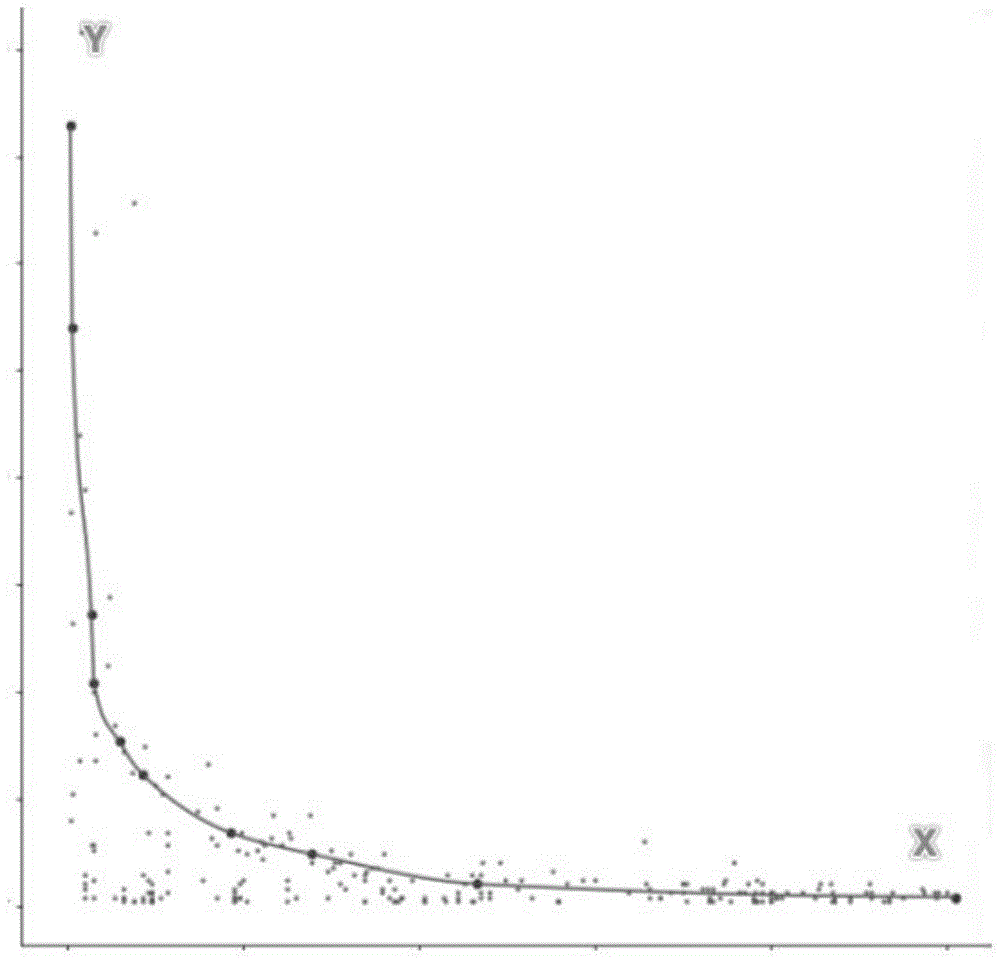
图1为本发明目标曲线示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1:
本发明提供了如图1的一种面向电商排名销量映射关系的曲线拟合估计方法,其特征在于,包括如下步骤:
s1:过滤掉y为0的样本;
s2:对原始数据进行分箱处理,生成新的更为稀疏的样本点,即新样本点;
s3:对于新样本点中出现的非单调性情况,基于曲线的非线性、单调递减的特点,得到最终的单调递减新样本点;
s4:基于单调三次样条插值方法(monotonepiecewisecubicinterpolation),得到相邻两个新样本点之间的插值计算公式,对样本点内的映射关系进行插值计算,最终得到了目标曲线。
具体的,所述分箱方法具体为:
y:2n,n∈[0,1,2,3,4,5……100];
x:[x1,x2,x3……],xi是基于y分类数据组的中间值,如果数据个数为偶数,则是两个中间数值和的一半。
具体的,所述最终的单调递减新样本点的获取方法具体为:
对x、y排序,得到新变量x-rank、y-rank;
x-rank是基于x升序得到的顺序序号,y-rank是基于y降序得到的顺序序号;
估计x-rank、y-rank的一元线性方程,在不存在噪音、异常值的情况下,x、y存在严格单调递减的关系,该方程为y-rank=x-rank;
计算离群点因子阈值,移除大于离群点因子阈值的点,如果新的样本点不符合单调递减原则,则不断缩小离群点因子阈值,直到新的样本符合单调性。
具体的,所述目标曲线具有x是连续整数、单调递减、对全局一阶导数无连续性或一致性要求的特征。
综上所述,与现有技术相比,我们训练了3883组样本,其中有2670组样本的准确率超过80%。使用该面向电商排名销量映射关系的曲线拟合估计方法得到的曲线拟合优度大于传统的非线性拟合方法的占比为84.9%。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
技术特征:
1.一种面向电商排名销量映射关系的曲线拟合估计方法,其特征在于,包括如下步骤:
s1:过滤掉y为0的样本;
s2:对原始数据进行分箱处理,生成新的更为稀疏的样本点,即新样本点;
s3:对于新样本点中出现的非单调性情况,基于曲线的非线性、单调递减的特点,得到最终的单调递减新样本点;
s4:基于单调三次样条插值方法,得到相邻两个新样本点之间的插值计算公式,对样本点内的映射关系进行插值计算,最终得到了目标曲线。
2.根据权利要求1所述的一种面向电商排名销量映射关系的曲线拟合估计方法,其特征在于:所述分箱方法具体为:
y:2n,n∈[0,1,2,3,4,5……100];
x:[x1,x2,x3……],xi是基于y分类数据组的中间值,如果数据个数为偶数,则是两个中间数值和的一半。
3.根据权利要求1所述的一种面向电商排名销量映射关系的曲线拟合估计方法,其特征在于:所述最终的单调递减新样本点的获取方法具体为:
对x、y排序,得到新变量x-rank、y-rank;
x-rank是基于x升序得到的顺序序号,y-rank是基于y降序得到的顺序序号;
估计x-rank、y-rank的一元线性方程,在不存在噪音、异常值的情况下,x、y存在严格单调递减的关系,该方程为y-rank=x-rank;
计算离群点因子阈值,移除大于离群点因子阈值的点,如果新的样本点不符合单调递减原则,则不断缩小离群点因子阈值,直到新的样本符合单调性。
4.根据权利要求1所述的一种面向电商排名销量映射关系的曲线拟合估计方法,其特征在于:所述目标曲线具有x是连续整数、单调递减、对全局一阶导数无连续性或一致性要求的特征。
技术总结
本发明公开了一种面向电商排名销量映射关系的曲线拟合估计方法,包括如下步骤:S1:过滤掉y为0的样本;S2:对原始数据进行分箱处理,生成新的更为稀疏的样本点,即新样本点;S3:对于新样本点中出现的非单调性情况,基于曲线的非线性、单调递减的特点,得到最终的单调递减新样本点;S4:基于单调三次样条插值方法,得到相邻两个新样本点之间的插值计算公式,对样本点内的映射关系进行插值计算,最终得到了目标曲线。本发明提供的一种面向电商排名销量映射关系的曲线拟合估计方法,本发明噪音点少,得到的曲线拟合优度大于传统的非线性拟合方法的占比为84.9%,可达到拟合优度目标。
技术研发人员:杨沙
受保护的技术使用者:湖南数魔网络科技有限公司
技术研发日:2020.07.09
技术公布日:2020.10.23
- 还没有人留言评论。精彩留言会获得点赞!