基于GCN-LSTM的个体位置预测方法与流程
基于gcn-lstm的个体位置预测方法
技术领域
[0001]
本发明属于空间信息技术领域,具体涉及一种基于gcn-lstm的个体位置预测 方法。
背景技术:
[0002]
目前,我国正在经历快速城镇化过程,人口在城市中的大量聚集对城市资源 配置提出了更高的要求,而相对滞后的城市发展水平带来了一系列的城市问题(如 交通拥堵、人群踩踏等公共安全事件)。人的移动模式与城市资源分布息息相关, 理解人的移动规律,预测个体未来活动位置,能够支撑城市资源的合理配置,从 而更科学地应对有关城市问题。
技术实现要素:
[0003]
有鉴于此,本发明的目的在于提供一种基于gcn-lstm的个体位置预测方法, 能够有效地提高个体位置预测的正确率。
[0004]
为实现上述目的,本发明采用如下技术方案:
[0005]
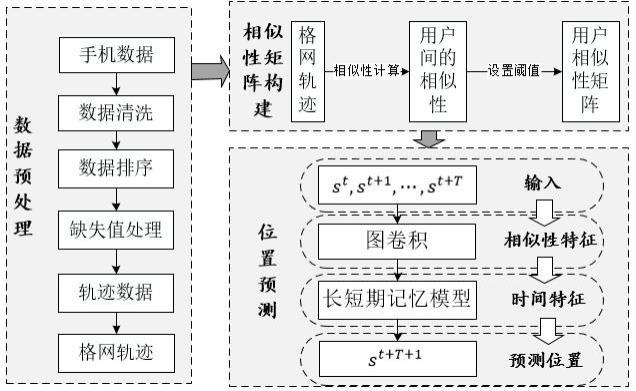
一种基于gcn-lstm的个体位置预测方法,包括以下步骤:
[0006]
步骤s1:采集用户的轨迹数据;
[0007]
步骤s2:度量用户轨迹的相似性;
[0008]
步骤s3:根据得到的用户轨迹的相似性,利用图卷积网络提取用户的相似性特征;
[0009]
步骤s4:构建改进的gcn-lstm模型;
[0010]
步骤s5:基于相似性特征,采用改进的gcn-lstm模型提取用户轨迹的时间特征, 得到预测结果。
[0011]
进一步的,所述步骤s2具体为:
[0012]
步骤s21:对用户的轨迹数据进行预处理,去除异常值和缺失值;
[0013]
步骤s22:设定格网单元在垂直方向和水平方向的尺寸,分别以研究区域左侧边 界和下侧边界为起始,向右和向上将研究区域进行网格划分,并对网格进行编码;
[0014]
步骤s23:根据用户的位置信息,计算对应的格网单元,用网格编号替换位置坐 标序列,将原始的用户轨迹转化为格网轨迹;
[0015]
步骤s24:计算两个用户在相同时刻位于相同格网的数量,然后计算该数量占总 时刻数的比值作为两个用户间的相似性。
[0016]
进一步的,所述步骤s24采用基于轨迹点相似性度量,计算方法如下:
[0017][0018]
[0019][0020]
其中,r,s分别表示两个用户的格网轨迹,r
t
和s
t
分别表示t时刻的格网位置编 码,记录点数均为n,dist(r
t
,s
t
)表示如果两个用户在t时刻在同一格网中记为1,否 则记为0;eu(r,s)为两个用户在相同时刻位于相同格网的总个数,sim(r,s)表示两 者的相似性度量。
[0021]
进一步的,所述步骤s3具体为:
[0022]
步骤s31:利用用户间的相似性构建的相似性图矩阵;
[0023]
步骤s32:根据得到的相似性图矩阵,采用图卷积网络对相似性特征建模来提取用 户的相似性特征。
[0024]
进一步的,所述步骤s31具体为:筛选出与要预测用户相似性超过设定阈值δ的 用户,然后计算这些用户之间的相似性,并进一步构建相似性图矩阵
[0025][0026]
式中,sim
r,s
表示用户r和用户s之间的相似性。
[0027]
进一步的,所述图卷积模型具体为:
[0028][0029][0030]
relu(x)=max(0,x)
ꢀꢀꢀ
(7)
[0031]
式中,x表示当前时刻要预测用户和与其相似性超过阈值的用户的位置构成 的矩阵,a为用户的相似性图矩阵,为度矩阵,relu为激活函数,max为取最 大值函数,w为权重矩阵。
[0032]
进一步的,改进的gcn-lstm模型具体为:设置阈值α,基于该阈值,对于待预 测的用户,如果在数据集中能找到与之相似程度超过该阈值的用户时,采用 gcn-lstm进行提取轨迹的时间特征,否则采用lstm提取轨迹的时间特征。
[0033]
进一步的,所述采用lstm提取轨迹的时间特征,具体如下:
[0034]
(a)输入t时刻的用户位置x
t
,利用t-1时刻的输出h
t-1
和当前t时刻的输入x
t
计 算遗忘门f
t
[0035]
f
t
=σ(w
f
·
[h
t-1
,x
t
]+b
f
)
ꢀꢀꢀ
(8)
[0036][0037]
式中,h
t-1
表示t-1时刻的输出,x
t
表示t时刻的预测用户的位置信息,f
t
表示t 时刻忘记门函数,w
f
为输入层的权重矩阵,b
f
为输入层偏执项,通过模型训练获得 最优值,σ为sigmoid函数;
[0038]
(b)利用t-1时刻的输出h
t-1
和当前t时刻的输入x
t
计算输入门i
t
,利用t-1时刻的 输出h
t-1
和当前t时刻的输入x
t
生成一个候选向量
[0039]
i
t
=σ(w
i
·
[h
t-1
,x
t
]+b
i
)
ꢀꢀꢀ
(10)
[0040][0041][0042]
式中,w
i
、w
c
分别表示输入和状态更新层中的权重矩阵,而b
i
、b
c
为则为对应 的偏执项,tanh为激活函数;
[0043]
(c)更新细胞状态,即将c
t-1
更新为c
t
。将遗忘门的值f
t
与存储历史位置信息 的旧的细胞状态c
t-1
相乘,遗忘部分历史位置信息,然后将输入门值i
t
与候选向量 相乘,存储当前时刻的部分位置信息,最后将两个结果相加,确定新的细胞状 态
[0044][0045]
(d)利用t-1时刻的输出h
t-1
和当前t时刻的输入x
t
计算输出门o
t
,然后利用tanh 函数对细胞状态c
t
处理,并将处理后的值与输出门值o
t
相乘得到输出值
[0046]
o
t
=σ(w
o
·
[h
t-1
,x
t
]+b
o
)
ꢀꢀꢀ
(14)
[0047]
h
t
=o
t
*tanh(c
t
)
ꢀꢀꢀ
(15)
[0048]
式中w
o
和b
o
分别为输入出层的权重矩阵和偏执项,通过模型训练获得最优值。
[0049]
进一步的,采用gcn-lstm进行提取轨迹的时间特征,具体如下:
[0050]
(a)输入要预测用户和其相似性用户的位置信息x
t
∈r
v
[0051]
其中,v代表要预测用户和其相似性用户的总数
[0052]
(b)通过gcn模型提取用户的相似性特征得到矩阵x
′
t
∈r
v
;
[0053]
(c)从矩阵x
′
t
取出要预测用户的值x
′
t
作为lstm模型的输入,然后将t-1时刻的隐藏 层h
t-1
和x
′
t
放入lstm模型提取时间特征,最终得到预测结果
[0054]
x
′
t
→
x
′
t
=f(a,x
t
)
ꢀꢀꢀ
(16)
[0055]
y
t
=lstm(x
′
t
)
ꢀꢀꢀ
(17)
[0056]
本发明与现有技术相比具有以下有益效果:
[0057]
1、本发明顾及了用户轨迹相似度,利用图卷积模型对用户轨迹的相似性特征 建模,有效地提取了用户间的相似性特征,更好地利用用户相似性提高个体位置 预测的正确率;
[0058]
2、本发明在构建用户相似性特征矩阵时设置阈值,保留大于阈值的相似性值, 有效地减小了模型的计算量;
[0059]
3、本发明提出了确定用户相似性对个人位置预测有帮助的阈值的方法,并基 于此改进了gcn-lstm模型,有效的提升了正确率。
附图说明
[0060]
图1是本发明一实施例中个人位置预测示意图;
[0061]
图2是本发明原理示意图;
[0062]
图3是本发明一实施例中用户轨迹投影;
[0063]
图4是本发明一实施例中卷积模型提取用户相似性过程图;
[0064]
图5是本发明一实施例中长短期记忆模型;
[0065]
图6是本发明一实施例中gcn-lstm模型;
[0066]
图7是本发明一实施例中改进的gcn-lstm模型。
具体实施方式
[0067]
下面结合附图及实施例对本发明做进一步说明。
[0068]
请参照图2,本发明提供一种基于gcn-lstm的个体位置预测方法,包括以下 步骤:
[0069]
步骤s1:采集用户的轨迹数据;
[0070]
步骤s2:度量用户轨迹的相似性;
[0071]
步骤s3:根据得到的用户轨迹的相似性,利用图卷积网络提取用户的相似性特征;
[0072]
步骤s4:构建改进的gcn-lstm模型;
[0073]
步骤s5:基于相似性特征,采用改进的gcn-lstm模型提取用户轨迹的时间特征, 得到预测结果。
[0074]
参考图3,在本实施例中,所述步骤s2具体为,所述步骤s2具体为:
[0075]
步骤s21:对用户的轨迹数据进行预处理,去除异常值和缺失值;
[0076]
步骤s22:设定格网单元在垂直方向和水平方向的尺寸,分别以研究区域左侧边 界和下侧边界为起始,向右和向上将研究区域进行网格划分,并对网格进行编码;
[0077]
步骤s23:根据用户的位置信息,计算对应的格网单元,用网格编号替换位置坐 标序列,将原始的用户轨迹转化为格网轨迹;
[0078]
步骤s24:计算两个用户在相同时刻位于相同格网的数量,然后计算该数量占总 时刻数的比值作为两个用户间的相似性。
[0079]
优选的,采用基于轨迹点相似性度量,计算方法如下:
[0080][0081][0082][0083]
其中,r,s分别表示两个用户的格网轨迹,r
t
和s
t
分别表示t时刻的格网位置编 码,记录点数均为n,dist(r
t
,s
t
)表示如果两个用户在t时刻在同一格网中记为1,否 则记为0;eu(r,s)为两个用户在相同时刻位于相同格网的总个数,sim(r,s)表示两 者的相似性度量。
[0084]
在本实施例中,用图结构对用户间的相似性建模,构建用户间的相似性图g
s
= (v,a),v代表用户的集合,a∈r
v*v
代表图矩阵,具体步骤如下:
[0085]
步骤s31:筛选出与要预测用户相似性超过设定阈值δ的用户,然后计算这 些用户
输出h
t-1
和当前t时刻的输入x
t
生成一个候选向量
[0104]
i
t
=σ(w
i
·
[h
t-1
,x
t
]+b
i
)
ꢀꢀꢀ
(10)
[0105][0106][0107]
式中w
i
、w
c
分别表示输入和状态更新层中的权重矩阵,而b
i
、b
c
为则为对应 的偏执项,均通过模型训练获得最优值,tanh为激活函数,计算方法如公式(12)。
[0108]
(c)更新细胞状态,即将c
t-1
更新为c
t
。将遗忘门的值f
t
与存储历史位置信息 的旧的细胞状态c
t-1
相乘,遗忘部分历史位置信息,然后将输入门值i
t
与候选向量 相乘,存储当前时刻的部分位置信息,最后将两个结果相加,确定新的细胞状 态
[0109][0110]
(d)利用t-1时刻的输出h
t-1
和当前t时刻的输入x
t
计算输出门o
t
,然后利用tanh 函数对细胞状态c
t
处理,并将处理后的值与输出门值o
t
相乘得到输出值
[0111]
o
t
=σ(w
o
·
[h
t-1
,x
t
]+b
o
)
ꢀꢀꢀ
(14)
[0112]
h
t
=o
t
*tanh(c
t
)
ꢀꢀꢀ
(15)
[0113]
式中w
o
和b
o
分别为输入出层的权重矩阵和偏执项,通过模型训练获得最优值。
[0114]
参考图6,在本实施例中,采用gcn-lstm进行提取轨迹的时间特征,具体如下:
[0115]
(a)输入要预测用户和其相似性用户的位置信息x
t
∈r
v
[0116]
其中,v代表要预测用户和其相似性用户的总数
[0117]
(b)通过gcn模型提取用户的相似性特征得到矩阵x
′
t
∈r
v
;
[0118]
(c)从矩阵x
′
t
取出要预测用户的值x
′
t
作为lstm模型的输入,然后将t-1时刻的隐藏 层h
t-1
和x
′
t
放入lstm模型提取时间特征,最终得到预测结果
[0119]
x
′
t
→
x
′
t
=f(a,x
t
)
ꢀꢀꢀ
(16)
[0120]
y
t
=lstm(x
′
t
)
ꢀꢀꢀ
(17)。
[0121][0122]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变 化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1