一种用于人机融合客服系统的自动地址纠偏方法与流程
本发明涉及人机融合技术领域,具体是一种用于人机融合客服系统的自动地址纠偏方法。
背景技术:
传统人机融合方案,受限于早期深度学习技术的发展瓶颈,基本停滞于基于规则的文本语义知识库辅助层面,机器人辅助坐席的手段和能力非常有限。实际应用中,对于类似高精度实时转写推送、实时高精度话术提醒、实时高精度地址纠偏、实时工单总结等智能辅助场景具有迫切需求,亟需一套完整的坐席辅助平台以支撑相关场景的能力输出。
以实时高精度地址纠偏为例,在坐席人人对话场景中,涉及坐席针对用户地址说法做详细确认的业务非常多。传统方式主要靠坐席人工监听后,到第三方地图系统中人工搜索,并经多轮对话才能够最终确认完整地址信息;相对智能的方式也只有基于规则的地址纠偏,效果不佳。
现有的地址纠偏技术,对于呼叫中心而言,存在坐席工作效率较低,用户等待时间长,地址检索出错率高,整体体验较差的问题。
技术实现要素:
针对现有地址纠偏技术存在的技术缺陷,本发明提供一种用于人机融合客服系统的自动地址纠偏方法,能够有效提升坐席在地址确认环节的工作效率,同时降低出错率,降低用户等待时间,提升用户体验。
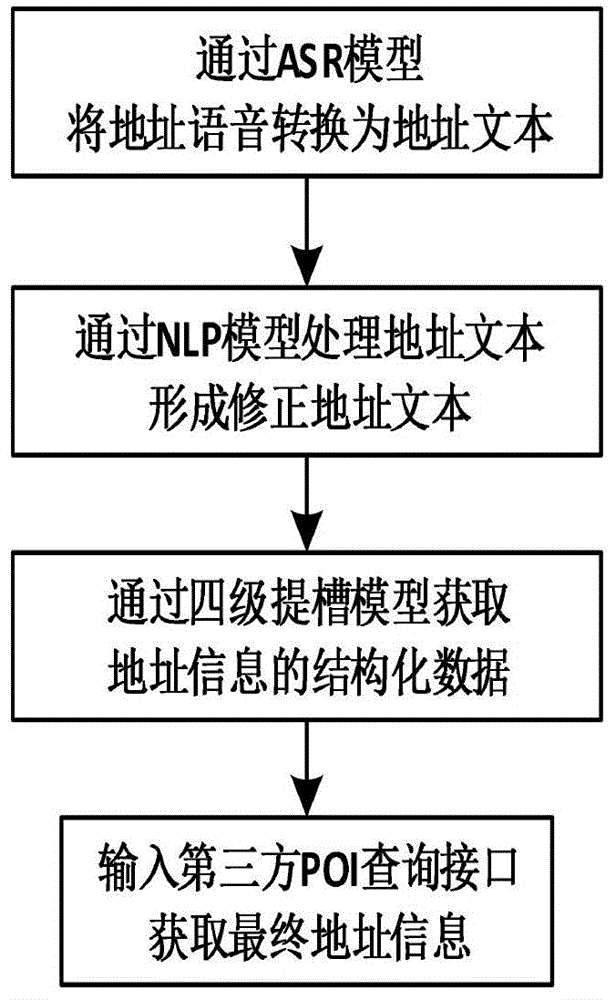
一种用于人机融合客服系统的自动地址纠偏方法,先通过asr模型将地址语音转换为地址文本,再通过nlp模型处理地址文本形成修正地址文本,再获取地址信息的结构化数据,最后输入第三方地图供应商的poi查询接口获取最终地址信息;
对用于nlp模型训练的数据集中的每一个输入样本进行拼音编码,并按照常见语音错误对其进行混淆处理,形成该输入样本的混淆集,将输入样本连同其混淆集一起作为扩增输入样本,对nlp模型进行训练。
进一步的,地址信息的结构化数据通过四级提槽模型获取,四级提槽模型输入数据为修正地址文本,输出数据为分别对应于省字段、市字段、区字段、详细地址字段的具体信息。
进一步的,将地址信息的结构化数据输入第三方地图供应商的poi查询接口获取最终地址信息,包括以下步骤:
步骤1,对详细地址字段的具体信息进行拼音编码,并按照常见语音错误对其进行混淆处理,形成验证混淆集;
步骤2,结合省字段、市字段、区字段与详细地址字段,输入第三方地图供应商的poi查询接口,在该省市区范围内查找该详细地址,得到第三方地图供应商按照相关性返回的最相近地址;
步骤3,对第三方地图供应商返回的最相近地址进行拼音编码,并按照常见语音错误对其进行混淆处理,形成结果混淆集;
步骤4,对比结果混淆集和验证混淆集中的字符串,若仅存在常见语音错误,则判定该结果混淆集对应的地址可靠,返回该地址,否则丢弃该地址,返回空地址。
进一步的,若第三方地图供应商仅有1个行政区槽位,则先结合区字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息;
若返回为空地址,则再结合市字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息;
若返回仍为空地址,则再结合省字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息。
进一步的,常见语音错误包括但不限于前鼻音与后鼻音的混淆、平舌音与翘舌音的混淆。
本发明针对地址语音存在的常见语音错误,利用输入样本的拼音编码及其混淆集对nlp模型的训练数据进行扩增,具备辨别常见语音错误的能力,在自然语言处理这一步实现初步纠偏;通过地址信息结构化,以及具有拼音容错功能的地址匹配算法,大大提升了第三方地图供应商返回地址的准确率,大大降低了坐席人工干预处理的工作量。
附图说明
图1为自动地址纠偏方法主要流程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显而易见的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
实施例1
一种用于人机融合客服系统的自动地址纠偏方法,如图1所示,先通过asr模型将地址语音转换为地址文本,再通过nlp模型处理地址文本形成修正地址文本,再获取地址信息的结构化数据,最后输入第三方地图供应商的poi查询接口获取最终地址信息。nlp模型可采用自然语言处理常用的transformer模型。
客服在工作过程中,会遇到不同口音的人,例如部分地区居民无法区分前鼻音与后鼻音,或者无法区分平舌音与翘舌音。为此,对用于nlp模型训练的数据集中的每一个输入样本进行拼音编码,并按照常见语音错误对其进行混淆处理,形成该输入样本的混淆集,将输入样本连同其混淆集一起作为扩增输入样本,对nlp模型进行训练,使得训练好的nlp模型具备辨别常见语音错误的能力。当然,本实施例中的常见语音错误并不局限于前鼻音与后鼻音的混淆、平舌音与翘舌音的混淆,其他形式的常见语音错误,也可以加入混淆集,用于nlp模型的训练,提升nlp模型辨别常见语音错误的能力。
为了降低地址文本中无用的干扰信息,通过四级提槽模型获取地址信息的结构化数据,四级提槽模型输入数据为修正地址文本,输出数据为分别对应于省字段、市字段、区字段、详细地址字段的具体信息。四级提槽模型通过行业地址库数据训练得到。
将地址信息的结构化数据输入第三方地图供应商的poi查询接口获取最终地址信息,包括以下步骤:
步骤1,对详细地址字段的具体信息进行拼音编码,并按照常见语音错误对其进行混淆处理,形成验证混淆集;
步骤2,结合省字段、市字段、区字段与详细地址字段,输入第三方地图供应商的poi查询接口,在该省市区范围内查找该详细地址,得到第三方地图供应商按照相关性返回的最相近地址;
步骤3,对第三方地图供应商返回的最相近地址进行拼音编码,并按照常见语音错误对其进行混淆处理,形成结果混淆集;
步骤4,对比结果混淆集和验证混淆集中的字符串,若仅存在常见语音错误,则判定该结果混淆集对应的地址可靠,返回该地址,否则丢弃该地址,返回空地址。
若第三方地图供应商(例如高德)仅有1个行政区槽位,则先结合区字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息;
若返回为空地址,则再结合市字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息;
若返回仍为空地址,则再结合省字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息。
显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域及相关领域的普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
技术特征:
1.一种用于人机融合客服系统的自动地址纠偏方法,其特征在于,先通过asr模型将地址语音转换为地址文本,再通过nlp模型处理地址文本形成修正地址文本,再获取地址信息的结构化数据,最后输入第三方地图供应商的poi查询接口获取最终地址信息;
对用于nlp模型训练的数据集中的每一个输入样本进行拼音编码,并按照常见语音错误对其进行混淆处理,形成该输入样本的混淆集,将输入样本连同其混淆集一起作为扩增输入样本,对nlp模型进行训练。
2.根据权利要求1所述的用于人机融合客服系统的自动地址纠偏方法,其特征在于,地址信息的结构化数据通过四级提槽模型获取,四级提槽模型输入数据为修正地址文本,输出数据为分别对应于省字段、市字段、区字段、详细地址字段的具体信息。
3.根据权利要求2所述的用于人机融合客服系统的自动地址纠偏方法,其特征在于,将地址信息的结构化数据输入第三方地图供应商的poi查询接口获取最终地址信息,包括以下步骤:
步骤1,对详细地址字段的具体信息进行拼音编码,并按照常见语音错误对其进行混淆处理,形成验证混淆集;
步骤2,结合省字段、市字段、区字段与详细地址字段,输入第三方地图供应商的poi查询接口,在该省市区范围内查找该详细地址,得到第三方地图供应商按照相关性返回的最相近地址;
步骤3,对第三方地图供应商返回的最相近地址进行拼音编码,并按照常见语音错误对其进行混淆处理,形成结果混淆集;
步骤4,对比结果混淆集和验证混淆集中的字符串,若仅存在常见语音错误,则判定该结果混淆集对应的地址可靠,返回该地址,否则丢弃该地址,返回空地址。
4.根据权利要求3所述的用于人机融合客服系统的自动地址纠偏方法,其特征在于,若第三方地图供应商仅有1个行政区槽位,则先结合区字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息;
若返回为空地址,则再结合市字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息;
若返回仍为空地址,则再结合省字段与详细地址字段,输入第三方地图供应商的poi查询接口获取地址信息。
5.根据权利要求1-4任意一项所述的用于人机融合客服系统的自动地址纠偏方法,其特征在于,常见语音错误包括但不限于前鼻音与后鼻音的混淆、平舌音与翘舌音的混淆。
技术总结
本发明公开了一种用于人机融合客服系统的自动地址纠偏方法,先通过ASR模型将地址语音转换为地址文本,再通过NLP模型处理地址文本形成修正地址文本,再获取地址信息的结构化数据,最后输入第三方地图供应商的POI查询接口获取最终地址信息;对用于NLP模型训练的数据集中的每一个输入样本进行拼音编码,并按照常见语音错误对其进行混淆处理,形成该输入样本的混淆集,将输入样本连同其混淆集一起作为扩增输入样本,对NLP模型进行训练。本发明针对地址语音存在的常见语音错误,利用输入样本的拼音编码及其混淆集对NLP模型的训练数据进行扩增,具备辨别常见语音错误的能力,在自然语言处理这一步实现初步纠偏。
技术研发人员:卫海智;吴天栋;杜科;廖奇;蔡劲松
受保护的技术使用者:科讯嘉联信息技术有限公司
技术研发日:2020.12.25
技术公布日:2021.05.28
- 还没有人留言评论。精彩留言会获得点赞!