异构计算硬件能耗和性能优化方法、系统和存储介质与流程
1.本发明涉及嵌入式系统, 具体涉及异构计算硬件的能耗和性能优化方法。
背景技术:
2.在嵌入式系统中,优化功耗的常规策略是通过降低处理器的运行速度来降低功耗。高效节能的计算平台需要更高的功耗与性能效率,而不仅仅只是节能。单纯的降低功耗通常会影响性能效率,并且由于性能下降,完成任务需要更多时间。传统的动态电压频率缩放(dvfs)和自适应电压缩放(avs)技术侧重于arm硬件的处理系统(ps)和现场可编程门阵列(fpga)的可编程逻辑(pl)的协同架构,通常依赖于反馈控制。当前,很多异构计算的硬件已经可以执行多个计算密集型操作,这要求更高的性能和功率效率。因此,如何在不影响性能的情况下控制能耗,对于嵌入式系统的有效性能至关重要。
3.arm硬件的处理系统(ps)和现场可编程门阵列(fpga)的可编程逻辑(pl)都有非常独特的架构,使得在不影响整个嵌入式异构计算系统性能的情况下优化功耗成为可能。与ps端不同,pl端允许用户描述他们的体系结构。在fpga (pl端)正常运行时,总功耗由器件的静态功耗、动态功耗和i/o功耗组成。数字逻辑计算并不消耗大量的静态功率。节能将主要集中在动态能耗上。通过不同的pl工作状态来满足不同的工作负载,可以减少内部电路翻转的功耗,从而实现了动态功耗的节能。
技术实现要素:
4.为了实现嵌入式异构计算系统动态功耗的节能,本发明具体采用如下技术方案:一种通过强化学习实现异构计算硬件能耗和性能优化的方法,其特征在于包括如下步骤:步骤1、获取嵌入式处理系统和可编程逻辑当前运行信息;步骤2、根据所述当前运行信息,将嵌入式处理系统和可编程逻辑当前运行状态与预设的32种运行状态进行匹配;所述预设的32种运行状态为嵌入式处理系统和可编程逻辑的协同工作状态,包含嵌入式处理系统和可编程逻辑不同运行状态的组合;步骤3、基于强化学习算法,分析嵌入式处理系统频率和可编程逻辑计算模块的最优开启与关闭时间,获得嵌入式处理系统和可编程逻辑最优运行状态反馈给电源管理系统;步骤4、电源管理系统对嵌入式处理系统和可编程逻辑进行控制, 匹配最佳的工作负载与功耗。
5.本发明公开了一种通过强化学习实现异构计算硬件能耗和性能优化的方法,通过将异构计算硬件平台当前运行状态与预设的32种运行状态进行匹配,基于强化学习算法分析嵌入式处理系统频率和可编程逻辑计算模块的开启与关闭时间,获得嵌入式处理系统和可编程逻辑最优运行状态,反馈给电源管理工具实现硬件控制。采用本发明方法,可以动态地调整异构平台的资源利用率,从而最大程度地降低功耗。强化学习算法用于分析和优化
现场可编程门阵列控制状态功能的资源利用率,作为硬件控制算法,可以精确调节pl功耗, 保证任何工作负载下都能满足功耗需求,获得最优的功耗与性能。
附图说明
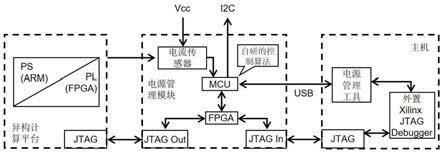
6.图1为本发明实施例1应用的硬件框架结构。
7.图2为本发明实施例1强化学习算法的主要程序代码。
具体实施方式
8.下面结合附图及实施例对本发明做进一步说明。
9.实施例1本实施例提供一种通过强化学习实现异构计算硬件能耗和性能优化的方法。如图1所示,该方法应用的硬件框架结构主要包括:ps: 处理系统(processing system),基于arm核的soc的部分。
10.pl: 可编程逻辑 (progarmmable logic),fpga部分。
11.mcu: 微控制器处理单元microcontroller unit。
12.ps和pl共同组成异构计算平台, 即此异构平台包含arm和fpga计算硬件。
13.图1左侧部件:是目标异构计算平台,即需要进行功耗优化的硬件。在本发明实施例中,这是一个包含arm(ps端)和fpga(pl端)的硬件。
14.图1中间部件:电源管理模块,是一个与主机相连的硬件模块,主要包括传感器和mcu微处理器,可以抓取目标硬件的电流和电压信息,并处理反馈优化策略。
15.图1右侧部件:主机,主要用于运行电源管理工具,把优化策略通过jtag端口输入目标硬件,最终保证硬件运行在最优的性能功耗下。电源管理工具是主机端运行的一套电源管理程序,功耗优化算法就集成到电源管理工具里面。电源管理工具会读取电源管理模块上面抓取到的目标硬件的电流和电压信息,进而控制目标硬件的运行策略。
16.整体工作流程:如图1,通过电流传感器获取异构平台的功耗信息传入mcu微控制器,利用强化学习算法(本发明设计的硬件控制算法)对功耗信息进行处理, 反馈当前最优的硬件控制,即arm频率和fpga计算模块最优的开启与关闭时间,通过usb传输给主机的电源管理工具,电源管理工具通过jtag端口对arm和fpga进行硬件控制,包括arm的频率上升与下降的控制、 fpga计算模块的开启和关闭的控制。
17.强化学习算法运行在电源管理模块中,通过硬件自有的mcu微处理器运行,算法通过读取当前的运行信息,并与设计好的32种运行状态进行匹配分析后输入到强化学习中学习最优的硬件工作负载和功耗需求,最后反馈出控制硬件状态的最优选择。
18.本实施例的通过强化学习实现异构计算硬件能耗和性能优化的方法具体包括如下步骤:步骤1、通过异构计算平台内置的传感器和嵌入式系统的功耗监控函数获取嵌入式处理系统和可编程逻辑当前运行信息,具体包括:嵌入式处理系统的功率状态信息: 功率上升/功率下降/高平滑功耗/低平滑功耗可编程逻辑的功率状态信息: 功率上升/功率下降/高平滑功耗/低平滑功耗
可编程逻辑计算模块的动作状态信息: 开启/关闭。
19.其中,传感器采集系统的电流和电压数据,功耗监控函数利用传感器采集的数据计算出当前系统运行的功耗。
20.步骤2、根据嵌入式处理系统和可编程逻辑当前运行信息,将嵌入式处理系统和可编程逻辑当前运行状态与预设的32种运行状态进行匹配。
21.预设的32种运行状态为嵌入式处理系统和可编程逻辑的协同工作状态,包含嵌入式处理系统和可编程逻辑不同运行状态的组合,即包括嵌入式处理系统的4种功率状态信息、可编程逻辑4种功率状态信息和可编程逻辑计算模块开启与关闭2个动作状态信息的任意组合,总计4 x 4 x 2 = 32种不同组合。
22.步骤3、基于强化学习算法,分析嵌入式处理系统频率和可编程逻辑计算模块的最优开启与关闭时间,获得嵌入式处理系统和可编程逻辑最优运行状态反馈给电源管理系统。
23.强化学习是需要假设的,在给定的策略下迭代更新价值函数,随后,在当前策略基础上,贪婪地选取行为,使得后继状态价值增加最多(即奖励最多)。这是一个从最开始随机选择状态,演变到后面越来越贴合最优运行状态的过程(因为每一次选择都必须要能比之前的选择好,才能让算法获得奖励)。强化学习的目的是训练代理(agent),使代理能够自主获得实现某一目的的策略。为实现这一目的,代理需要不断的向环境做出动作,环境根据代理所做的动作带来的结果评价该动作的好坏,并反馈给代理奖励,奖励有积极奖励和消极奖励,分别表示在该状态下执行该动作的结果的好和坏,执行该动作后代理会到达下一个状态。
24.本发明强化学习算法采用q
‑
learning算法。在q
‑
learning算法中,代理的经验存储在q表中,q即为q(s,a),就是在某一个时刻的state(缩写为s)状态下,采取动作action(缩写为a)能够获得收益的期望,环境根据agent的动作反馈相应的reward奖赏,所以算法的主要思想就是将state和action构建成一张q表来存储q值,然后根据q值来选取能够获得最大收益的动作。
25.本发明基于强化学习算法,针对目标硬件上运行的应用搭建一个仿真环境,利用训练程序在环境中对计算模块的动作状态进行学习,从而获取正确的计算模块的开启或者关闭的状态。
26.基于强化学习算法分析嵌入式处理系统频率和可编程逻辑计算模块的开启与关闭时间包括如下步骤:配置强化学习算法的q表,并清零;通过传感器获得当前的运行状态并输入算法;将当前运行状态与预设的32种运行状态匹配,获得对应的运行状态;设置可编程逻辑计算模块对应动作 (此时设置为对应模块的开启与关闭);建立奖励机制,设置贪心算法,强化学习目标的最大奖励为最优运行状态;根据每一次的奖励更新q表,随着奖励的增加, 实现越来越贴合最优运行状态的动作选择;最终强化学习学到了最优的硬件工作负载和功耗需求. 通过学习到的q表反馈出控制硬件状态的最优选择动作
最终获得最优运行状态。
27.每个 q 表包含前述32 种运行状态,在算法决策阶段,算法处理的信息不是独立分布的,是ps和pl工作状态的组合序列。
28.步骤4、电源管理系统对嵌入式处理系统和可编程逻辑进行控制, 匹配最佳的工作负载与功耗。
29.步骤3涉及的主要程序代码如图2所示:1:将表 q(s, a) 的 q 值初始化为全零矩阵。(备注: 配置强化学习的q表, 并清零)2:观察当前状态s。(备注: 通过传感器获得当前的状态)要求: :3:状态 s = (s1, s2..., s32) (备注: 把观察到的状态s 与预设的32种状态匹配, 获得1/32对应的状态.)4:动作a=a1和a2(pl时钟开始和停止)(备注: 设置硬件配置动作, 此时应该是对应pl端fpga的时钟开启和关闭两个动作)5:奖励函数:s*a
→
r (备注: 算法建立奖励机制)6:设置 greedy = 0.1,learningrate : α ∈[0, 1](通常 α = 0.1),rewarddiscountfunction γ ∈ [0, 1](通常γ = 0.9)(备注: 设置贪心算法)7:用奖励更新q值。(备注: 根据每一次的奖励来更新q表的值)8:为接下来的 n 步状态找到最大奖励。(备注: 设置强化学习目标的最大奖励为最优运行状态)9:贝尔曼方程:q(s, a)
ꢀ←ꢀ
q(s, a) + α [ r + γ maxα * q(s', a')
–
q(s, a)] (备注: 从这到最下面, 都是更新强化学习的q表的值. 状态价值函数在当前状态的动作是不确定的, 所以它必须考虑到所用动作的情况然后取其奖励期望)10:模型[s][a].r = r;11:模型[s][a].s_ = s;12: 无符号 s2, a2, s_2 , 浮点 r213:对于 n=0; n < 4; + + n 做14: q(s2, a2)
ꢀ←ꢀ
q(s2, a2) + α [ r2 + γ maxα * q(s2', a2')
–
q(s2, a2);15:s2 = s_2; a2 = get_action_sate(s_2);16: a = get_action_sate(s_);17:s = s_;18:结束19:返回动作;(备注: 最终强化学习学到了最优的硬件工作负载和功耗需求,反馈出控制硬件状态的最优选择)20:设置状态为新状态,直到s终止。 (备注: 把反馈的选择更新为现在的状态, 循环往复的控制硬件一直处于最优运行状态)实施例2
本实施例提供一种嵌入式系统,包括存储器、处理器、存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现实施例1所述的通过强化学习实现异构计算硬件能耗和性能优化的方法的步骤。
[0030]
实施例3本实施例提供一种存储介质,所述存储介质存储有至少一个程序,所述至少一个程序可被至少一个处理器执行,以实现实施例1所述的通过强化学习实现异构计算硬件能耗和性能优化的方法的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1