一种适用于中国公民姓名的智能提取算法的制作方法
1.本发明涉及审计行业,具体是一种适用于中国公民姓名的智能提取算法。
背景技术:
2.审计工作中会遇到很多需要关注人员姓名的内容,如:投标书中承诺的技术人员姓名、会议纪要或公示中人员姓名等。但在海量资料中精确、全面的提取所有人员姓名,人工提取时的耗时性,遗漏性问题便突出显示,这些都是目前迫切需要解决的问题。
3.随着审计行业需求量不断扩大,审计人员对相关资料文件中人名重复的关注度也越来越高,不同文件中出现相同名字便可作为审计疑点提供审计人员的进一步确认,大量资料文件的不断累积,造成审计人员人工提取人员姓名也就更加困难。
技术实现要素:
4.本发明的目的在于提供一种适用于中国公民姓名的智能提取算法,以解决上述背景技术中提出的问题。
5.为实现上述目的,本发明提供如下技术方案:
6.一种适用于中国公民姓名的智能提取算法,所述算法包括如下步骤:
7.s1、将特殊字符基础表中的特殊字符以及排除词组中的排除词组查询出来;
8.s2、将文件中文字提取出来并替换特殊字符以及排除词组为*,标识该替换后的文字;
9.s3、将姓氏基础表的姓氏查出来;
10.s4、将姓氏在替换后的文字的位置截取后1位到后6位作为提取后的姓名;
11.s5、入库提取后的姓名。
12.作为本发明进一步的方案:所述算法中后台使用spring+springmvc+mybatise框架,前台使用html展示数据,交互方式为ajax,交互数据类型为json,数据库为sqlserver,解析文件提取数据需要利用到java中poi包。
13.作为本发明进一步的方案:所述特殊字符基础表为常见特殊字符数据,用于替换文字,减少人名提取的误差。
14.作为本发明进一步的方案:所述姓氏基础表为姓氏的数据,用于人名的截取。
15.作为本发明进一步的方案:所述排除词组基础表为非人名数据,用于替换文字,减少人名提取的误差。
16.与现有技术相比,本发明的有益效果是:
17.本发明按照程序设计好的算法,将资料文件中的人名提取出来,可以提供审计人员对不同文件重复姓名的预警提示,提高对审计风险的管控。
18.本发明人名提取快捷、方便,可支持大文件人名提取,避免了人工提取的劳动力的浪费,极大节省了人财等资源消耗。
附图说明
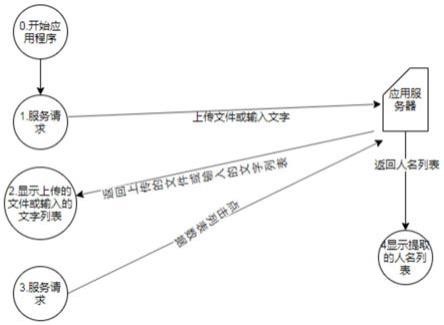
19.图1为一种适用于中国公民姓名的智能提取算法的流程图。
具体实施方式
20.下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
21.请参阅图1,一种适用于中国公民姓名的智能提取算法,后台使用spring+springmvc+mybatise框架,前台使用html展示数据,交互方式为ajax,交互数据类型为json,数据库为sqlserver,解析文件提取数据需要利用到java中poi包,所述算法包括如下步骤:
22.s1、将特殊字符基础表中的特殊字符以及排除词组中的排除词组查询出来;
23.s2、将文件中文字提取出来并替换特殊字符以及排除词组为*,标识该替换后的文字;
24.s3、将姓氏基础表的姓氏查出来;
25.s4、将姓氏在替换后的文字的位置截取后1位到后6位作为提取后的姓名;
26.s5、入库提取后的姓名。
27.其中,基础表解释:
28.(1)特殊字符基础表为常见特殊字符数据,便于替换文字,减少人名提取的误差;
29.(2)姓氏基础表为姓氏的数据,便于人名的截取;
30.(3)排除词组基础表主要是地名,工程名词等非人名数据,该数据主要从200标书中由程序逻辑将词组提取出来,再根据人工筛选提取出来的数据,耗费时长较多,便于替换文字,减少人名提取的误差;
31.使用流程为:
32.1.姓名提取记录列表展示;
33.2.文本类型提取;
34.3.文件上传提取;
35.4.文件进行识别提示;
36.5.姓名提取结果;
37.上面对本专利的较佳实施方式作了详细说明,但是本专利并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本专利宗旨的前提下做出各种变化。
技术特征:
1.一种适用于中国公民姓名的智能提取算法,其特征在于,所述算法包括如下步骤:s1、将特殊字符基础表中的特殊字符以及排除词组中的排除词组查询出来;s2、将文件中文字提取出来并替换特殊字符以及排除词组为*,标识该替换后的文字;s3、将姓氏基础表的姓氏查出来;s4、将姓氏在替换后的文字的位置截取后1位到后6位作为提取后的姓名;s5、入库提取后的姓名。2.根据权利要求1所述的一种适用于中国公民姓名的智能提取算法,其特征在于,所述算法中后台使用spring+springmvc+mybatise框架,前台使用html展示数据,交互方式为ajax,交互数据类型为json,数据库为sqlserver,解析文件提取数据需要利用到java中poi包。3.根据权利要求1所述的一种适用于中国公民姓名的智能提取算法,其特征在于,所述特殊字符基础表为常见特殊字符数据,用于替换文字,减少人名提取的误差。4.根据权利要求1所述的一种适用于中国公民姓名的智能提取算法,其特征在于,所述姓氏基础表为姓氏的数据,用于人名的截取。5.根据权利要求1所述的一种适用于中国公民姓名的智能提取算法,其特征在于,所述排除词组基础表为非人名数据,用于替换文字,减少人名提取的误差。
技术总结
本发明提供了一种适用于中国公民姓名的智能提取算法,包括如下步骤:将特殊字符基础表中的特殊字符以及排除词组中的排除词组查询出来;将文件中文字提取出来并替换特殊字符以及排除词组为*,标识该替换后的文字;将姓氏基础表的姓氏查出来;将姓氏在替换后的文字的位置截取后1位到后6位作为提取后的姓名;入库提取后的姓名;本发明人名提取快捷、方便,可支持大文件人名提取,避免了人工提取的劳动力的浪费,极大节省了人财等资源消耗。极大节省了人财等资源消耗。极大节省了人财等资源消耗。
技术研发人员:权利要求书1页说明书2页附图1页
受保护的技术使用者:廊坊市审计局
技术研发日:2021.09.29
技术公布日:2021/12/30
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1