一种商用车车载质量检测方法与流程
1.本发明属于智能车联网和物流运输技术领域,具体地说,本发明涉及一种商用车车载质量检测方法。
背景技术:
2.商用车的整车车载质量对于能源的消耗、车辆损耗具有非常大的影响,严重超载更是具有非常大的安全隐患,在当前车辆智能化发展的情况下,整车车载质量是一些新技术应用的基础数据,如何能够实时的检测客户车辆的车载质量情况是目前各个车企面临的问题,也是国家在治超层面面临的问题。
3.目前市面上存在四种车载质量的实时监测原理方法,即应变原理、位移原理、气压原理和动力学原理,目前市场上也开始出现一些测量设备安装在车辆上进行数据采集,这种方法需要安装额外的硬件传感器,成本高,而且后续维护成本很大,对测量精度也会有影响,基于动力学原理由于精度高、可以进行动态测量、生命周期长的特点是近几年来的热点和趋势。
4.但是基于动力学原理的方法,目前现有方案均采用单一模型的预测方式,这种方法带来的问题是模型预测结果精确度很不稳定,难以适用对载重预估相对严格的场景。
技术实现要素:
5.本发明提供一种商用车车载质量检测方法,解决了上述背景技术中所提出的问题。
6.为了实现上述目的,本发明采取的技术方案为:一种商用车车载质量检测方法,包括步骤如下,
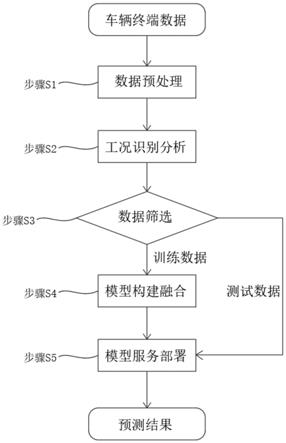
7.步骤s1,数据预处理,针对车辆原始终端数据进行数据解析,清洗以及噪声处理等操作;
8.步骤s2,工况识别分析,针对预处理之后的数据,再进行进一步的工况分析;
9.步骤s3,数据筛选,判断工况分析的数据属于测试数据或训练数据,若属于测试数据则进行步骤s5,若属于训练数据则进行步骤s4;
10.步骤s4,模型构建融合,通过步骤s2中的训练数据构建多个不同的基础模型,并通过训练和筛选,最终进行模型融合;
11.步骤s5,模型服务部署,将训练好的模型部署到云服务器上,利用训练生成的模型与模型服务化代码构建docker镜像,并推送至车联网docker镜像仓库。
12.优选的,所述步骤s1包括以下步骤,
13.步骤s11,数据解析,对车辆原始终端数据进行解析,解析出建模所需车辆的数据;
14.步骤s12,数据过滤,针对解析出来的数据进行如填充、对齐、插值数据平滑等操作,并且根据离合刹车等条件判断数据中是否符合动力学原理的数据,若是则进行步骤s13,若否则将其送回车辆原始终端;
15.步骤s13,异常检测,判断数据是否属于异常数据,若是则进行s14,若否则将其送回车辆原始终端,其中检测方法为,
16.一、基于规则的主要是根据各属性的实际意义去判断,例如转速不能为负,扭矩不能超过一定范围;
17.二、通过模型算法异常检测中常用的孤立森林模型对异常样本进行剔除以及基于中心点波峰的过滤;
18.s14,换挡检测,针对动力学公式中分析得到的对车载质量的影响因素,判断数据是否属于异常数据,若是则进行s2,若否则将其送回车辆原始终端。
19.优选的,所述步骤s2包括以下步骤,
20.步骤s21,设置工况过滤的条件,扭矩输出百分比要大于10%、发动机转速要大于怠速转速、刹车信号为0;
21.步骤s22,生成各种定义的工况的时间段,根据加速度进行筛选过滤,识别出加减速时间段,根据离合信号识别踩离合时间段;
22.步骤s23,对各种工况的时间进行组合,选取有效的工况时间,选取在工况过滤条件下的,不踩离合不睬刹车符合动力学原理的基本工况时间段,进行下一步的模型构建的初步输入数据。
23.优选的,所述步骤s4包括以下步骤,
24.步骤s41,模型创建,通过步骤s2中的训练数据构建多个不同的基础模型;
25.步骤s42,模型训练,基于准备好的模型训练样本集对所选择的基础回归模型进行训练,对模型参数进行优化选择,生成多个整车质量预测基础模型,再通过测试样本集对训练好的整车质量预测模型进行性能评估,对于载重评估模型;
26.步骤s43,模型筛选,判断得到的模型是否达到融合要求,若是则进行s44,若否则重新进行步骤s42;
27.步骤s44,模型融合,将上述得到的多个较好的模型进行模型融合。
28.优选的,所述步骤s41中构建多个不同的基础模型有以下几种方式,
29.一、通过档位过滤;
30.二、通过三角域变换数据过滤。
31.优选的,所述档位过滤设计如下,
32.1)统计车速转速比分布密度;
33.2)利用分布密度图进行峰值检测,峰值所在的位置就是档位车速转速比所在的中心点位置;
34.3)在进行峰值检测的同时输出峰值宽度,得到峰值宽度的上下边界,即各档位车速转速比上下边界;
35.4)根据车速转速比上下边界过滤数据,上下界范围内的数据被保留,不在上下界范围内的数据被过滤。
36.优选的,所述三角域变换数据过滤设计如下,
37.1)计算力矩与加速度之间的比值,然后求解其反正切函数;
38.2)统计核密度分布;
39.3)理论上载重所对应的计算比值系数必定分布密度较高,故使用峰值检测检测峰
值点和峰值宽度;
40.4)利用峰值宽度的上限边界进行数据过滤。
41.优选的,所述步骤s43中的模型筛选方法如下,
42.1)对于载重相关的特征力矩以及加速度进行斜率的计算得到系数c;
43.2)利用该系数c进行坐标轴旋转;
44.3)对新生成的坐标x、y分别求单变量一倍标准差,并将y的一倍标准差与x一倍标准差相除得到xyscore。
45.优选的,所述xyscore的具体实现算法
46.1)对于每个构建的基础模型的输入数据(df0,df20)去计算中间系数coef。
47.2)利用该系数coef进行新坐标轴计算,计算公式如下:
48.x=cos(arctan(coef))*df0+sin(arctan(coef))*df20;
49.y=cos(arctan(coef))*df20-sin(arctan(coef))*df0;
50.3)对新的生成的坐标x,y分别求单变量一倍标准差,并将y的一倍标准差与x一倍标准差相除得到xyscore。
51.优选的,本方案所涉及到的原理基础是基于动力学公式:
52.f
t
=ff+fw+fi+fj53.其中f
t
代表牵引力,ff代表滚动阻力,fw代表空气阻力,fi代表坡度阻力,fj代表惯性力,公式可以近似展开为:
[0054][0055]
其中f为滚动阻力系数,g重力加速度,cd为空气阻力系数,a为迎风面积,ρ空气密度,m为车载质量,t
tq
为发动机扭矩,i为传动比,n为发动机转速,av为加速度,iw为转动惯量,if为飞轮的转动惯性,η效率,t为常量。
[0056]
公式可以近似整理表达如下得到建模的参考原理方程:
[0057][0058]
这里的a,b,c,d,e都是为常量,其中速度、扭矩、加速度可以由原始数据以及衍生得到。
[0059]
采用以上技术方案的有益效果是:本发明依托车联网大数据平台的优势,基于动力学原理,设计实现了一种多ai算法模型筛选融合方法,此外本方案提出了一种新的模型选择算法来选择优质模型进行融合,以及通过对海量历史数据进行分析构建模型,实现了在不增加额外硬件的条件下,可以对商用车车载质量的实时监测,既保证了结果的准确性又降低了模型由于统计数据的随机性因素带来的结果不稳定性。
附图说明
[0060]
图1是本发明提供车载质量检测方法的流程图;
[0061]
图2是数据预处理的流程图;
[0062]
图3是工况识别分析的装配图;
[0063]
图4是模型构建融合的流程图;
具体实施方式
[0064]
下面对照附图,通过对实施例的描述,对本发明的具体实施方式作进一步详细的说明,目的是帮助本领域的技术人员对本发明的构思、技术方案有更完整、准确和深入的理解,并有助于其实施。
[0065]
实施例1,如图1所示:
[0066]
本发明基于动力学原理,设计实现了一种多ai算法模型筛选融合方法,此外本方案提出了一种新的模型选择算法来选择优质模型进行融合,以及通过对海量历史数据进行分析构建模型,实现了在不增加额外硬件的条件下,可以对商用车车载质量的实时监测,既保证了结果的准确性又降低了模型由于统计数据的随机性因素带来的结果不稳定性。
[0067]
实施例2,如图2所示:
[0068]
在实施例1的基础上,由于数据是由车载终端发出来的原始报文数据,需要对报文数据进行解析,解析出建模所需车辆的数据,针对解析出来的数据进行如填充、对齐、插值数据平滑等操作,并且根据离合刹车等条件初步过滤掉不符合动力学原理的数据,针对数据异常点,设计了一个识别和过滤模块,这个模块主要运用两种方式,一种是基于规则的主要是根据各属性的实际意义去判断,例如转速不能为负,扭矩不能超过一定范围,另一种是模型算法异常检测中常用的孤立森林模型对异常样本进行剔除以及基于中心点波峰的过滤,二者分别从单属性维度和整体样本维度上做了数据的异常过滤,然后针对动力学公式中分析得到的对车载质量的影响因素,进行特征值的衍生操作,生成用于建模所需要的字段,由于换挡操作对于数据有很大的影响,因此针对换挡操作进行了识别去除。
[0069]
实施例3,如图3所示:
[0070]
在实施例1的基础上,基础模型的选择,线性回归是最常见的学习算法,线性模型的许多优点是众所周知的,拟合这些模型所涉及的计算成本通常是适度的,并且总是可预测的,通常需要最少的调优,其表达形式自然有助于解释,因此本方案中采用了sklearn工具箱中的回归算法实现基础算法模型,包括linearregression、ransacregressor、ridge、huber、theilsen。
[0071]
基础模型选择完成之后针对各个基础模型进行建模,将训练数据采用不同的处理划分方式,主要是针对经过档位过滤的驾驶数据、档位叠加工况过滤后的数据、档位叠加三角域变换过滤后的数据、档位叠加工况叠加三角域变换过滤后的数据、以及各个不同工况的划分数据,分别构建训练不同的基础模型。
[0072]
实施例4,如图4所示:
[0073]
在实施例1的基础上,本方案中的数据划分为5种,分别去构建5种已经选择好的基础模型,然后进入到下一步的模型训练中,具体构建基础模型方式如下:
[0074]
模型一:输入数据:进行档位过滤之后的数据(df0,df20),基础模型:linearregression;
[0075]
模型二:输入数据:进行档位过滤以及工况过滤后的数据(df0,df20),基础模型:ransacregressor;
[0076]
模型三:输入数据:档位过滤加三角阈变换过滤之后的数据(df0,df20,基础模型:ridge;
[0077]
模型四:输入数据:档位过滤加工况过滤加三角域变换过滤后的数据(df0,df20),
基础模型:theilsen;
[0078]
模型五:输入数据:三角阈变换过滤之后的数据(df0,df20),基础模型:huber。
[0079]
实施例5,如图4所示:
[0080]
在实施例4的基础上,将构建好的五种基础模型,分别进行训练,以及参数的调优,训练阶段要具有真实载重(load)的数据,对于每一个基础模型进行训练,训练步骤如下:
[0081]
1.将按照上步不同过滤条件过滤之后的数据(df0,df20)输入到回归模型ransacregressor,来拟合df0与df20之间的关系,得到中间系数coef;
[0082]
2.然后将中间系数coef与真实载重的数据(coef,load)整合对应,生成输入到基础模型的数据,进行训练上一步选择好的每个基础模型;
[0083]
3.在模型的训练过程中,对模型参数进行优化选择,生成预测基础模型;再通过测试样本集对训练好的整车质量预测模型进行性能评估,对于载重评估模型,由于模型的输出为一个数值,即常见的回归问题,所以可以使用机器学习回归模型常用的一些指标,如mape,mae,r2,在这里本方案采用mape来作为主要评价标准,不断的通过评价指标指导模型的迭代训练,直至模型训练完成;
[0084]
4.训练完成之后输出载重预测模型,可以进行未知数据的预测,输出预测载重值。
[0085]
最后基于xyscore算法可以从多模型中筛选比较好的模型进行最终模型融合,其中评级机制xyscore分数越大,模型性能越好。
[0086]
对计算过程中产生的多个基础模型,利用xyscore进行筛选,评分越大代表模型性能越好,选择出其中的top-n,进行最终模型的融合,本方案设定n=2。
[0087]
以上结合附图对本发明进行了示例性描述,显然,本发明具体实现并不受上述方式的限制,只要是采用了本发明的方法构思和技术方案进行的各种非实质性的改进;或未经改进,将本发明的上述构思和技术方案直接应用于其它场合的,均在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1