一种对用于处理细胞图像的U-Net模型进行训练的训练方法
一种对用于处理细胞图像的u-net模型进行训练的训练方法
技术领域
1.本发明属于计算机图像处理技术领域,具体涉及一种对用于处理细胞图像的u-net模型进行训练的训练方法。
背景技术:
2.目前许多疾病的诊断非常依赖于病人血液内细胞数量的计数结果,而临床上常用的细胞计数手段基本都是基于细胞分析仪,一般根据两种计数原理:电阻抗法,当不同大小的细胞通过检测通道时,会产生不同的电压脉冲信号;光散射法,当不同波长的光照到不同细胞时,会得到不同的衍射角。但是此种仪器具有操作复杂、成本较高、耗时等缺点。
3.图像分割是根据图像的特征将图像划分成若干特定区域,是一种以像素为单位标记图像中的感兴趣区域的图像处理过程。对于单一种类的细胞分割,传统方法主要是基于二值化或者边缘特征,对于粘连细胞通常会采用分水岭算法进行处理。但是由于细胞图像拍摄的因素以及细胞生存环境的复杂性,传统图像处理算法不能完全胜任混合种类细胞的分割。
4.近年来,基于卷积神经网络的方法在计算机视觉领域被广泛应用于图像分类、目标检测、图像去噪、语义分割等任务中。不同于传统图像处理方法,深度学习可以从细胞图像中学习到不同细胞的特征,从而能够对不同的细胞进行分类。其中,全卷积神经网络可以获得较好的图像分割性能。全卷积神经网络去掉了传统卷积神经网络的全连接层,并使用上采样操作实现端到端(即像素到像素)图像分割。
5.u-net模型是一个具有编解码器结构的全卷积神经网络,该模型中的编码器模块用于特征提取,解码器模块用于恢复原始图像分辨率的特征图。u-net模型通常在小尺度图像数据集上取得较好的分割效果,由于其编解码器结构,适合于医学图像分割。u-net模型使用跳过连接将编码器模块的浅层特征图与解码器模块的深层特征图结合起来,以恢复细粒度的对象细节。但是为了训练深度学习模型,需要大量具有像素级标签的数据,然而在专家的协助下手动标记数据是一个费劲且昂贵的过程。
6.有鉴于此,如何进一步降低图像标注成本、细胞图像分割难度以及细胞计数操作复杂度,成为目前亟待解决的技术课题。
技术实现要素:
7.为克服上述现有技术中存在的缺陷和不足,本发明提供了一种对用于处理细胞图像的u-net模型进行训练的训练方法,该训练方法基于预先获得的标注细胞图像数据集对u-net模型进行训练,经过训练的u-net模型能够对细胞图像进行准确分割,分割后的轮廓边缘清晰,有效提高对细胞图像,尤其是混合种类细胞图像进行分割和/或计数的准确性。
8.u-net模型是一种常见的用于医学图像处理的深度学习模型,该模型主要有三个特点:(1)用于下采样的编码器路径,(2)用于上采样的解码器路径,(3)用于结合编码器和解码器信息的跳连接。但深度学习模型想要获得良好的训练效果,往往需要大量的人工标
注的训练集,而训练集的标注成本较高。本发明所提供的该种训练方法使用传统图像处理方法预先获得标注细胞图像数据集,并使用其对u-net模型进行训练,这样可以在有效降低成本的同时能够获得足够的训练数据来进行u-net模型的训练,优势明显,能有效解决现有技术中存在的图像标注成本高、细胞图像分割困难以及细胞计数操作复杂等难题。
9.为达上述目的,本发明所提供的该种训练方法,其具体包括以下步骤:
10.s1、获取单种类细胞图像并制作图像训练集;
11.s2、使用图像处理算法处理上述步骤s1中所制作的图像训练集中的每一张图像并得到该图像对应的标签掩膜图,最终形成图像训练集对应的标签掩膜图训练集;
12.s3、使用上述步骤s2所获得的标签掩膜图训练集对u-net模型进行训练;
13.s4、获取混合种类细胞图像并制作微调数据集;
14.s5、使用上述步骤s4所制作的微调数据集对经上述步骤s3训练过的u-net模型进行微调式训练。
15.在本发明的一个具体实施例中,上述步骤s1可包括以下步骤:
16.s11、使用成像设备获取所需的单种类细胞图像;
17.s12、将上述步骤s11中所获取的单种类细胞图像切割成若干固定大小的图像,最终汇集成图像训练集。
18.本领域技术人员可以理解的是,上述步骤s11中使用的成像设备可以是任何适用的现有成像设备,例如可连接到显微镜上的高清摄像机、高清摄像头等。
19.在本发明的一较佳实施例中,上述步骤s12中,可以将图像切割成固定的通行大小512
×
512
×
3。
20.本领域技术人员可以理解的是,上述步骤s2中所使用的图像处理算法可以是任何适用的现有图像处理算法,例如可以包括高斯滤波、自适应阈值算法、铃木轮廓检测算法、形态学腐蚀膨胀操作等。
21.有鉴于此,在本发明的一个具体实施例中,上述步骤s2可包括以下步骤:
22.s21、使用高斯滤波处理上述步骤s1中所制作的图像训练集中的每一张图像,去除图像中的噪音;
23.s22、使用自适应阈值算法处理经上述步骤s21处理过的图像训练集中的每一张图像,得到图像二值化的标签;
24.s23、使用铃木轮廓追踪算法对经上述步骤s22处理过的图像训练集中的每一张图像进行图像边缘检测;
25.s24、对经上述步骤s23处理过的图像训练集中的每一张图像的图像边缘轮廓进行填充,得到该图像对应的标签掩膜图,最终汇集成图像训练集对应的标签掩膜图训练集。
26.本领域技术人员可以理解的是,上述步骤21中所去除的噪音可以是图像捕获过程中产生的各类噪音。
27.在本发明的一较佳实施例中,为提高精度,上述步骤24中,在对图像边缘轮廓进行填充之前可以移除面积较小的轮廓。
28.在本发明的一较佳实施例中,上述步骤24中所获得的标签掩膜图大小仍然保持为512
×
512
×
3。
29.在本发明的一较佳实施例中,为提高精度,对于体积较大的细胞来说,例如巨噬细
胞,上述步骤24中在获得图像对应的标签掩膜图之前对图像追加形态学腐蚀膨胀操作,优选地,可以先进行腐蚀操作,然后再进行膨胀操作,如此反复进行2次。但本领域技术人员也能理解的是,前述形态学腐蚀膨胀操作不是必须的。
30.在本发明的一个具体实施例中,上述步骤s3可包括以下步骤:
31.s31、设置卷积核大小为3
×
3、步长和填充为1的卷积层;
32.s32、设置卷积核大小为2
×
2和4
×
4两种步长为2的池化层;
33.s33、设置2倍和4倍的最近邻插值层;
34.s34、设置卷积核大小为1
×
1的卷积层;
35.s35、将上述步骤s2获得的标签掩膜图训练集输出送入u-net模型,对标签掩膜图训练集中的每一张图像进行四次下采样;
36.s36、将上述步骤s2获得的标签掩膜图训练集输出送入u-net模型,对标签掩膜图训练集中的每一张图像进行四次上采样,并结合上述步骤35获得的下采样图像将对应层中大小相同的输出进行拼接;
37.s37、对经过上述步骤36处理过的上采样图像进行1
×
1的卷积操作,使用激活函数得到标签掩膜图训练集中的每一张图像的最终预测图;
38.s38、使用上述步骤37中所获得的最终预测图与其所对应图像的真实值之间的差异作为损失,基于该损失进一步更新u-net模型,实现对u-net模型的训练。
39.本领域技术人员可以理解的是,上述步骤s3中,对u-net模型的训练可经过多次迭代以使u-net模型达到理想性能,迭代次数越多,u-net模型所能达到的性能越理想,但这也会导致成本的升高,训练时的学习率和具体迭代次数可以由本领域技术人员根据实际情况进行设置。
40.其中,上述步骤s35中,前三次下采样中的每一次均先经过两次3
×
3的卷积,其中每次卷积后都使用激活函数进行激活,然后再经过一次2
×
2的池化操作,第四次下采样仅经过一次4
×
4的池化操作;上述步骤s36中,第一次上采样经过两次3
×
3的卷积,其中卷积后使用激活函数进行激活,然后再经过4倍的最近邻插值操作,后三次上采样中的每一次均经过2倍的最近邻插值操作。
41.本领域技术人员可以理解的是,上述步骤s35和s36中使用的激活函数可以是任何适用的现有激活函数,例如relu激活函数。
42.本领域技术人员可以理解的是,上述步骤s37中使用的激活函数可以是任何适用的现有激活函数,例如softmax激活函数。
43.在本发明的一较佳实施例中,上述步骤s37中得到的最终预测图大小是512
×
512
×
3,与上述步骤s2中获得的标签掩膜图大小相同。
44.在本发明的一个具体实施例中,上述步骤s4可包括以下步骤:
45.s41、使用成像设备获取所需的混合种类细胞图像;
46.s42、将上述步骤s41中获取的混合种类细胞图像切割成若干固定大小的图像;
47.s43、对上述步骤s42中切割后获得的每一张图像进行人工标注,并汇集成微调数据集。
48.本领域技术人员可以理解的是,上述步骤s41中使用的成像设备可以是任何适用的现有成像设备,例如可连接到显微镜上的高清摄像机、高清摄像头等。
49.在本发明的一较佳实施例中,上述步骤s42中,可以将图像切割成固定的通行大小512
×
512
×
3。
50.本领域技术人员可以理解的是,上述步骤s43中,可以使用任何适用的现有图像标注工具进行人工标注,例如深度学习图像标注工具labelme。
51.本领域技术人员可以理解的是,上述步骤s43中,制作的微调数据集中图像的张数越多,用其对u-net模型进行微调训练的效果就越好,但这也会导致成本的升高,具体张数可以由本领域技术人员根据实际情况进行设置。
52.在本发明的一个具体实施例中,上述步骤s5中,使用上述步骤s4所制作的微调数据集对经上述步骤s3训练过的u-net模型进行微调式训练,微调式训练时的学习率和迭代次数可以由本领域技术人员根据实际情况进行设置。
53.本领域技术人员可以理解的是,这里的“微调式训练”具体是指使用步骤s4中由混合种类细胞图像生成的微调数据集进一步训练步骤s3中训练过的u-net模型,以期望进一步提升其性能。
54.进一步地,本发明继而提供一种细胞图像的处理方法,该处理方法使用经训练的上述u-net模型对细胞图像进行分割和/或计数。
55.本领域技术人员可以理解的是,上述处理方法在处理混合细胞图像时尤其有效。
56.在本发明的一个具体实施例中,为提高准确度,优选地,上述处理方法中,计数时需要根据分割区域的面积进行判断,如果面积过小则不计数,面积过大则需要将其计数两次。
57.与先用技术相比,本发明具有以下有益的效果:
58.本发明所提供的该种u-net模型的训练方法,能有效利用传统图像处理算法高效自动的特点对细胞图像进行自动标注,实现了数据集的自动标注,极大地节省了人工成本;基于u-net模型实现了对混合种类细胞图像的有效分割和/或计数,可大大减少临床中细胞计数的成本。
附图说明
59.本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解。在附图中,除非另外规定,否则贯穿多个附图相同的附图标记表示相同或相似的部件或元素。这些附图不一定是按照比例绘制的。应该理解,这些附图仅描绘了根据本发明公开的一些实施方式,用来提供对本发明的进一步理解,构成本技术的一部分,而不应将其视为是对本发明范围的限制。其中:
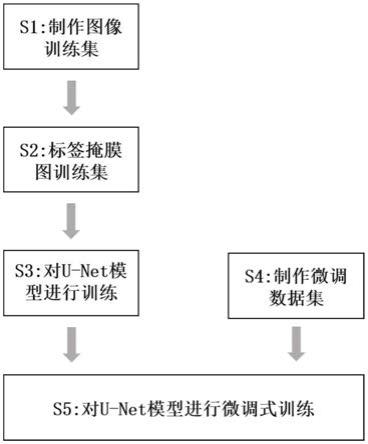
60.图1为本发明提供的训练方法的流程示意图;
61.图2为本发明的训练方法所使用的一种单种类细胞图像,其中,(a)为原始的红细胞图像,(b)为处理后得到的红细胞的标签掩膜图;
62.图3为本发明的训练方法所使用的另一种单种类细胞图像,其中,(a)为原始的巨噬细胞图像,(b)为处理后得到的巨噬细胞的标签掩膜图;
63.图4为使用本发明提供的训练方法训练后的u-net模型的结构示意图;
64.图5为使用u-net模型对混合种类细胞图像进行分割和/或计数的结果示意图,其中,(a)为原始的混合种类细胞图像,(b)为使用仅经单种类细胞图像数据训练的u-net模型
的处理结果,(c)为使用本发明的训练方法所训练的u-net模型的处理结果,(d)为基于(c)中的处理结果最终获得的识别并计数的结果。
具体实施方式
65.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及具体实施例,对本发明做进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,而不能理解为对本发明的限制。
66.为了提升深度学习模型在细胞图像处理方面的性能,本发明提供一种对用于处理细胞图像的u-net模型进行训练的训练方法,下面参考附图1-4描述该训练方法。其中,图1示出了该训练方法的具体流程,如图1所示,该训练方法具体包括以下步骤:
67.s1、获取单种类细胞图像并制作图像训练集;
68.s2、使用图像处理算法处理上述步骤s1中所制作的图像训练集中的每一张图像并得到该图像对应的标签掩膜图,最终形成图像训练集对应的标签掩膜图训练集;
69.s3、使用上述步骤s2所获得的标签掩膜图训练集对u-net模型进行训练;
70.s4、获取混合种类细胞图像并制作微调数据集;
71.s5、使用上述步骤s4所制作的微调数据集对经上述步骤s3训练过的u-net模型进行微调式训练。
72.在本实施例中,上述步骤s1包括步骤:s11、使用连接到显微镜上的高清摄像机获取所需的单种类细胞图像;s12、将步骤s11中所获取的单种类细胞图像切割成若干固定大小为512
×
512
×
3的图像,最终汇集成图像训练集。
73.这里,步骤s11中所获取的单种类细胞图像具体为红细胞图像或巨噬细胞图像,其中,图2中的(a)示出了获取的原始的红细胞图像,图3中的(a)示出了获取的原始的巨噬细胞图像。
74.在本实施例中,上述步骤s2包括步骤:s21、使用高斯滤波处理上述步骤s1中所制作的图像训练集中的每一张图像,去除图像中的噪音;其中,高斯滤波核的尺寸设定为3
×
3,行与列的方向上的标准偏差设置为0.8;s22、使用自适应阈值算法处理经上述步骤s21处理过的图像训练集中的每一张图像,得到图像二值化的标签;其中,进行区域自适应阈值处理时的滑动窗口的尺寸设定为3
×
3;s23、使用铃木轮廓追踪算法对经上述步骤s22处理过的图像训练集中的每一张图像进行图像边缘检测;s24、对经上述步骤s23处理过的图像训练集中的每一张图像的图像边缘轮廓进行填充,得到该图像对应的大小为512
×
512
×
3的标签掩膜图,最终汇集成图像训练集对应的标签掩膜图训练集。
75.优选地,为提高精度,上述步骤24中,在对图像边缘轮廓进行填充之前移除面积较小的轮廓。
76.优选地,为提高精度,针对巨噬细胞图像,上述步骤24中在获得图像对应的标签掩膜图之前对图像追加形态学腐蚀膨胀操作,具体为,先进行腐蚀操作,然后再进行膨胀操作,如此反复进行2次。
77.其中,图2中的(b)示出了处理后得到的红细胞的标签掩膜图,图3中的(b)示出了处理后得到的巨噬细胞的标签掩膜图。
78.在本实施例中,上述步骤s3包括步骤:s31、设置卷积核大小为3
×
3、步长和填充为
1的卷积层;s32、设置卷积核大小为2
×
2和4
×
4两种步长为2的池化层;s33、设置2倍和4倍的最近邻插值层;s34、设置卷积核大小为1
×
1的卷积层;s35、将上述步骤s2获得的标签掩膜图训练集输出送入u-net模型,对标签掩膜图训练集中的每一张图像进行四次下采样;s36、将上述步骤s2获得的标签掩膜图训练集输出送入u-net模型,对标签掩膜图训练集中的每一张图像进行四次上采样,并结合上述步骤35获得的下采样图像将对应层中大小相同的输出进行拼接;s37、对经过上述步骤36处理过的上采样图像进行1
×
1的卷积操作,使用softmax激活函数得到标签掩膜图训练集中的每一张图像的最终预测图,该最终预测图的大小为512
×
512
×
3;s38、使用上述步骤37中所获得的最终预测图与其所对应图像的真实值之间的差异作为损失,基于该损失进一步更新u-net模型,实现对u-net模型的训练。
79.为使u-net模型达到理想的性能,上述步骤s3中,对u-net模型的训练需经过多次迭代完成,将训练时的学习率设定为0.001,迭代次数为200,根据实践经验,200代后损失基本稳定。
80.其中,上述步骤s35中,前三次下采样中的每一次均先经过两次3
×
3的卷积,其中每次卷积后都使用relu激活函数进行激活,然后再经过一次2
×
2的池化操作,第四次下采样仅经过一次4
×
4的池化操作;上述步骤s36中,第一次上采样经过两次3
×
3的卷积,其中卷积后使用relu激活函数进行激活,然后再经过4倍的最近邻插值操作,后三次上采样中的每一次均经过2倍的最近邻插值操作。
81.在本实施例中,上述步骤s4包括步骤:s41、使用连接到显微镜上的高清摄像机获取所需的混合种类细胞图像;s42、将上述步骤s41中获取的混合种类细胞图像切割成50张固定大小为512
×
512
×
3的图像;s43、对上述步骤s42中切割后获得的50张图像中的每一张使用深度学习图像标注工具labelme进行人工标注,并汇集成微调数据集。
82.这里,步骤s41中所获取的混合类细胞图像具体为红细胞和巨噬细胞的图像。
83.在本实施例中,上述步骤s5具体为,将微调式训练时的学习率设定为0.0005,迭代次数为100,使用上述步骤s4所制作的微调数据集对经上述步骤s3训练过的u-net模型进行微调式训练。其中,图4示出了训练后的u-net模型的具体结构。
84.进一步地,本发明继而提供一种细胞图像的处理方法,该处理方法使用经训练的上述u-net模型对包含有红细胞和巨噬细胞的混合种类细胞图像进行分割和/或计数。
85.最后,对直接初步训练过的u-net模型和微调式训练过的u-net模型的处理效果进行对比,并从分割结果的准确性、细节信息的完整性和边缘轮廓的清晰性进行评价。其中,图5中的(a)示出了原始的混合种类细胞图像,图像中包含有红细胞和巨噬细胞;(b)示出了使用仅经单种类细胞图像数据训练的u-net模型的处理结果;(c)则示出了使用本发明的训练方法所训练的u-net模型的处理结果,从图中可以看到,分割效果识别准确,边缘清晰,细节信息完整;(d)则示出了基于(c)中的处理结果最终获得的识别并计数的结果,可见,混合种类细胞图像中的每个细胞均被清晰地识别出来,据此可以获得准确的细胞群数量。
86.尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1