基于机器人过程自动化(RPA)的数据标记的制作方法
本公开总体上涉及用于计算机学习的系统和方法,该系统和方法可提供改进的计算机性能、特征和应用。更具体地,本公开涉及用于数据集生成和监督学习的系统和方法。
背景技术:
1、机器学习在众多领域都取得了巨大成功,诸如计算机视觉、自然语言处理、推荐系统等。机器学习的主要趋势是研究通过经验自动改进的计算机方法。机器学习的一个领域是处理构建在使用标记数据训练的模型上的方法,以在没有明确编程的情况下进行预测或决策。在训练中使用标记的本真数据(ground-truth data)被称为监督学习。
2、类似地,深度学习是指一大类基于人工神经网络的机器学习方法。许多深度学习方法也在很大程度上依赖于标记数据。
3、使用标记数据的机器学习方法的最大挑战之一是获得标记数据。生成标记数据集可能相当昂贵并是劳动密集型的。通常,生成标记数据集涉及检测和标记数据样本的过程。通常,这种标记过程是由人工完成的。标记过程有时可由软件执行或在软件协助下进行;但是即使在这些情况下,其通常也需要大量的人工劳动。
4、因此,所需要的是用于生成标记数据的改进系统和方法以及用于部署训练模型的改进系统和方法。
技术实现思路
1、如上所述,需要用于生成标记数据和用于部署训练模型的改进系统和方法。本文所提供的是用于执行以下方法的系统、方法以及包括执行该方法的指令的计算机可读介质。
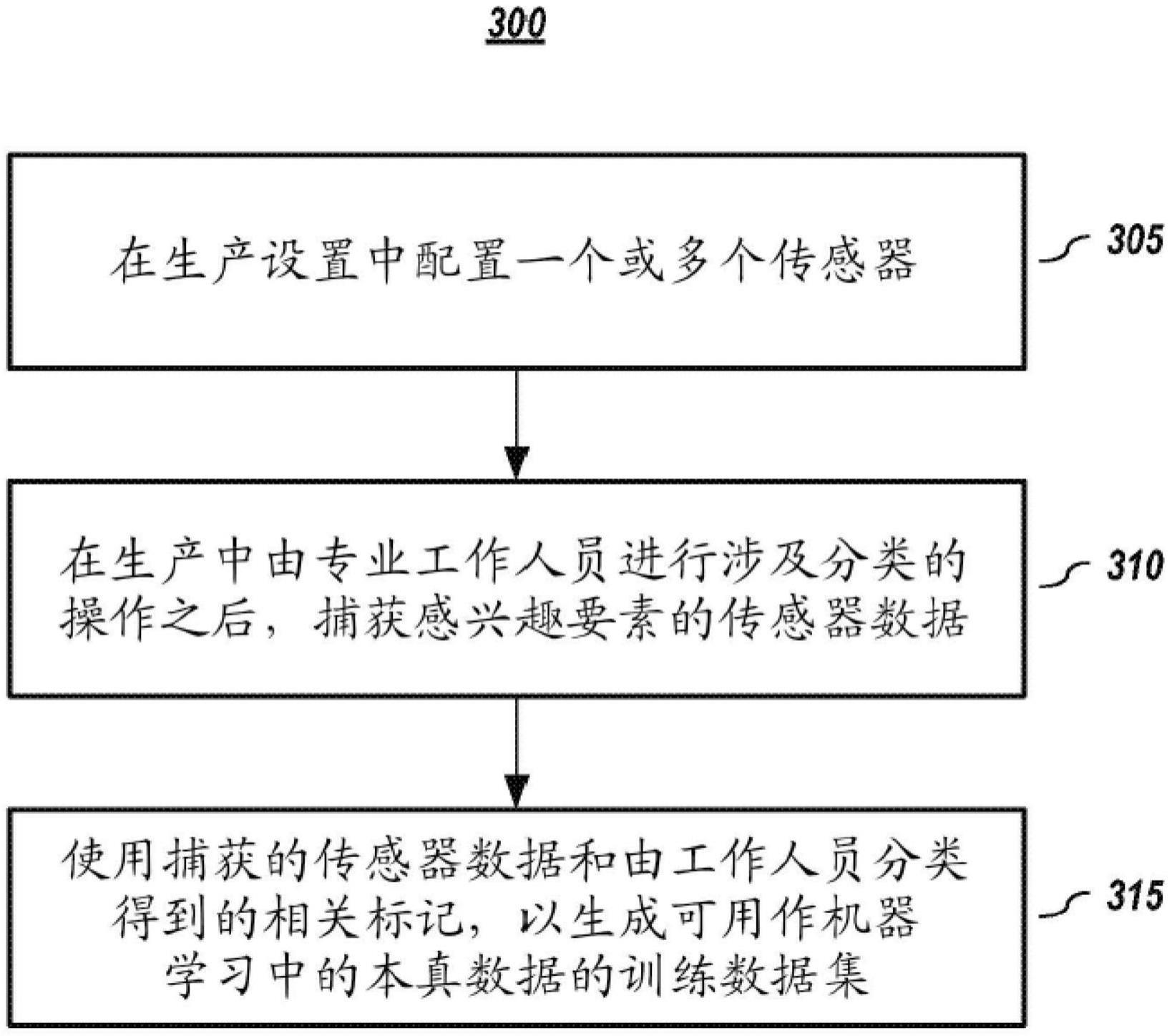
2、在一个或多个实施方式中,一种方法包括:对于多个感兴趣要素中的每个要素:使用在工作设置中配置的一个或多个传感器来捕获传感器数据,该传感器数据包括感兴趣要素的一个或多个值;以及将分类标记与感兴趣要素相关联,其中分类标记由一个或多个工作人员在一个或多个工作人员在工作设置中执行其常规职责的过程中确定。在一个或多个实施方式中,标记可与感兴趣要素或感兴趣项目相关联,传感器根据感兴趣要素或感兴趣项目来捕获关于感兴趣要素的数据。
3、可使用所捕获的传感器数据和关联标记来形成标记数据集。在一个或多个实施方式中,可使用标记数据集中的至少一些来训练机器学习模型以对感兴趣要素执行分类。在一个或多个实施方式中,可在相同或相似的工作设置中部署所训练的机器学习模型以自动分类感兴趣要素。在一个或多个实施方式中,如果在给定现有标记数据集的情况下机器学习模型未达到阈值以上的精确度,则可收集和/或使用额外标记数据以验证机器学习模型,并使用额外标记数据中的至少一些对机器学习模型执行额外训练。如果机器学习模型达到阈值以上的精确度,则可部署机器学习模型以自动分类感兴趣要素。
4、在一个或多个实施方式中,可从多个工作设置中收集数据,其中工作人员对相同类型的感兴趣要素进行操作并执行相同的分类操作。因此,可使用所捕获的传感器数据和由一个或多个工作人员分类得到的关联标记来创建多个标记数据集。在一个或多个实施方式中,对于从多个工作设置中选择的工作设置的集合中的每一个工作设置,可使用与工作设置相关联的标记数据集中的至少一些来训练机器学习模型以对感兴趣要素执行分类。
5、在一个或多个实施方式中,可收集或获得使用不同标记数据集形成的多个机器学习模型,并且可形成组合模型的集合,该组合模型的集合包括两个或更多个机器学习模型的组合。使用评估数据以获得针对每个组合模型的精确度度量,可选择具有可接受精确度度量的组合模型并部署在一个或多个工作设置处。
6、在一个或多个实施方式中,可组合来自至少两个工作设置的标记数据以形成标记数据的超集。这种数据集可有助于提高训练机器学习模型的稳健性。
7、在一个或多个实施方式中,一种用于训练机器学习模型的方法包括:获得训练数据,该训练数据包括针对每个训练数据条目的关于要素的输入数据和用于期望输出的相应本真数据;使用训练数据训练机器学习模型,对与关于要素的数据对应的输入数据进行操作以自动获得期望输出;其中,通过执行以下步骤获得训练数据中的训练数据条目中的至少一些,该步骤包括:使用在工作设置中配置的一个或多个传感器捕获传感器数据,该传感器数据包括用于形成关于要素的输入数据的上述要素的一个或多个值;以及将本真数据与输入数据相关联,其中本真数据是由一个或多个工作人员在工作设置中执行职业任务的过程中获得的。
8、在一个或多个实施方式中,可在相同或类似的工作设置中部署训练的机器学习模型,以自动进行由一个或多个工作人员执行的职业任务。
9、在一个或多个实施方式中,响应于在给定现有标记数据集的情况下机器学习模型未达到阈值以上的精确度,可从相同或类似的工作设置中获得额外训练数据以验证机器学习模型,和/或使用额外训练数据中的至少一些对机器学习模型执行额外训练。在一个或多个实施方式中,响应于机器学习模型达到阈值以上的精确度,可在相同或相似的工作设置中部署所训练的机器学习模型以自动进行职业任务。
10、在一个或多个实施方式中,训练数据可从多个工作设置中获得,其中工作人员对相同类型的要素进行操作并执行相同的职业操作以获得多个训练数据集。
11、在一个或多个实施方式中,可获得使用不同训练数据集形成的多个机器学习模型,并且可形成组合模型的集合,该组合模型的集合包括两个或更多个机器学习模型的组合。使用评估数据以获得针对每个组合模型的精确度度量,可选择具有可接受精确度度量的组合模型,并部署在至少一个工作设置中。
12、在一个或多个实施方式中,一种系统包括用于与一个或多个传感器连接的一个或多个通信连接、一个或多个处理器、以及包括一个或多个指令集的非暂时性计算机可读介质或媒介,该一个或多个指令集在由一个或多个处理器中的至少一个执行时,使得执行包括执行上述方法中的一个或多个的步骤。
13、在本
技术实现要素:
部分中大致地描述了本发明实施方式的一些特征和优点;然而,本文还呈现了其它特征、优点和实施方式,或者对本领域的普通技术人员而言,基于本文的附图、说明书和权利要求书,其它的这些特征、优点和实施方式将是显而易见的。因此,应理解,本发明的范围不应受限于在本发明内容部分中公开的特定实施方式。
技术特征:
1.一种方法,包括:
2.根据权利要求1所述的方法,还包括:
3.根据权利要求2所述的方法,还包括:
4.根据权利要求2所述的方法,还包括:
5.根据权利要求1所述的方法,还包括:
6.根据权利要求5所述的方法,还包括:
7.根据权利要求6所述的方法,还包括:
8.根据权利要求6所述的方法,还包括:
9.一种用于训练机器学习模型的方法,所述方法包括:
10.根据权利要求9所述的方法,还包括:
11.根据权利要求10所述的方法,还包括:
12.根据权利要求10所述的方法,其中,从多个工作设置中获得所述训练数据,其中工作人员对相同类型的要素进行操作并执行相同的职业操作以获得多个训练数据集。
13.根据权利要求12所述的方法,还包括:
14.根据权利要求13所述的方法,还包括:
15.根据权利要求12所述的方法,还包括:
16.一种系统,包括:
17.根据权利要求16所述的系统,还包括:
18.根据权利要求16所述的系统,其中,所述标记数据是从多个工作设置中获得的,其中工作人员对相同类型的要素进行操作并执行相同的职业操作以获得多个训练数据集。
19.根据权利要求16所述的系统,其中,所述一个或多个非暂时性计算机可读介质或媒介还包括一个或多个指令集,所述一个或多个指令集在由至少一个处理器执行时使得执行以下步骤,所述步骤包括:
20.根据权利要求19所述的系统,其中,所述一个或多个非暂时性计算机可读介质或媒介还包括一个或多个指令集,所述一个或多个指令集在由至少一个处理器执行时使得执行以下步骤,所述步骤包括:
21.一种存储有可执行计算机程序的非暂时性计算机可读存储介质,所述可执行计算机程序使处理器执行根据权利要求1-8中任一项所述的方法。
22.一种计算机程序产品,包括存储在计算机可读存储介质上的程序,所述程序包括可执行程序指令,所述可执行程序指令使处理器执行根据权利要求1-8中任一项所述的方法。
技术总结
深度学习方法和标记数据的一种应用用于工业生产或工作应用。对于用机器学习应用实施的这种应用,需要大量数据来训练、验证和/或调整模型以更好地符合要求。然而,获得这样的数据通常是昂贵且困难的。自适应过程提供用于工作设置的数据标记方法。所述方法利用工作或生产过程之便来标记和收集数据,这节省了时间和金钱并提高了精确度。所述方法防止或减少了工作人员培训成本的需求和人为错误触发的数据标记问题。实施方式还提高了数据标记质量并加速了开发周期。
技术研发人员:郑惠猛,寇浩锋
受保护的技术使用者:百度时代网络技术(北京)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!