本公开涉及一种包括在视频编码或解码装置中的基于可变系数深度学习的帧间预测方法。
背景技术:
1、下面的描述仅提供与本公开相关的背景信息,不构成现有技术。
2、由于视频数据与音频数据或静止图像数据相比具有大的数据量,因此需要包括存储器的大量硬件资源,以存储或发送视频数据而不进行压缩处理。
3、因此,通常在存储或发送视频数据时使用编码器来压缩视频数据并存储或发送,并且解码器接收压缩后的视频数据,对接收的压缩视频数据进行解压,并播放解压缩后的视频数据。视频压缩技术包括h.264/avc、高效视频编码(hevc)和多功能视频编码(vvc),与hevc相比,vvc的编码效率提高了约30%以上。
4、然而,由于图像大小、分辨率和帧速率逐渐增加,因此需要编码的数据量也增加。因此,需要一种提供比现有压缩技术更高的编码效率和改进的图像增强效果的新压缩技术。
5、最近,一种基于深度学习的视频处理技术被应用于现有的编码元件技术。基于深度学习的视频处理技术被应用于现有编码技术中的诸如帧间预测(inter prediction)、帧内预测(intra prediction)、环内滤波或变换等压缩技术。因此可以提高编码效率。代表性的应用示例包括基于根据深度学习模型生成的虚拟参考帧的帧间预测,以及基于图像修复模型的环内滤波(见非专利文献1)。因此,在视频编码或解码中,有必要考虑持续应用基于深度学习的视频处理技术,以提高编码效率。
6、[现有技术]
7、(非专利文献)
8、非专利文献1:lee等人,hevc中基于深度视频预测网络的帧间编码(deep videoprediction network based inter-frame coding in hevc),ieee access 2020。
技术实现思路
1、[技术问题]
2、本公开的目的是提供一种帧间预测方法,用于使可变系数深度学习模型自适应地学习视频的特征,将学习生成的可变系数深度学习模型的参数从视频编码装置发送到视频解码装置,以及参考由可变系数深度学习模型生成的虚拟参考帧。
3、[技术方案]
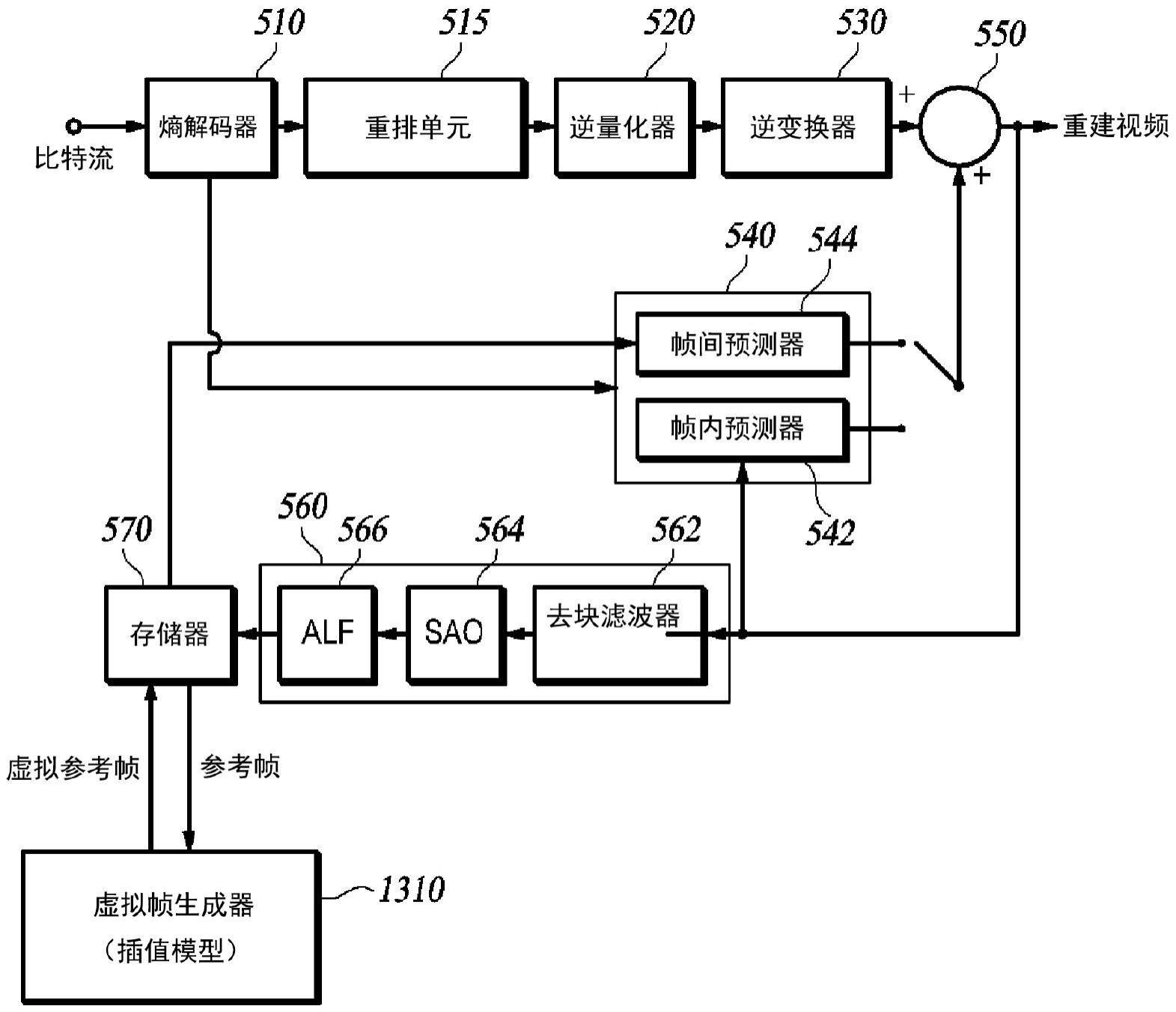
4、根据本公开的实施例,一种由视频解码装置执行的视频解码方法包括:从比特流中解码可变系数值、仿射预测标志和编码模式,所述仿射预测标志指示是否对当前块应用仿射运动预测,所述编码模式是所述当前块的运动信息的编码模式并指示合并模式或高级运动矢量预测(amvp)模式;通过利用插值模型,基于参考帧生成虚拟参考帧,其中,通过所述可变系数值设置包括在所述插值模型中的可变系数网络;以及当所述编码模式为所述合并模式时,基于所述虚拟参考帧和所述参考帧生成所述当前块的合并候选。
5、根据本公开的另一实施例,一种由视频编码装置执行的视频编码方法包括:获取先前生成的可变系数值和预设编码模式,其中,所述编码模式是当前块的运动信息的编码模式并指示合并模式或高级运动矢量预测(amvp)模式;通过利用插值模型,从参考帧生成虚拟参考帧,其中,通过所述可变系数值设置包括在所述插值模型中的可变系数网络;以及当所述编码模式为所述合并模式时,基于所述虚拟参考帧和所述参考帧生成所述当前块的合并候选。
6、根据本公开的另一实施例,一种视频解码装置包括:熵解码器,从比特流中解码可变系数值和编码模式,其中,所述编码模式是当前块的运动信息的编码模式并指示合并模式或高级运动矢量预测(amvp)模式;虚拟帧生成器,利用插值模型,从参考帧生成虚拟参考帧,其中,通过所述可变系数值设置包括在所述插值模型中的可变系数网络;以及帧间预测器,当所述编码模式为所述合并模式时,基于所述虚拟参考帧和所述参考帧生成所述当前块的合并候选。
7、[有益效果]
8、如上所述,根据本实施例,通过提供参考由可变系数深度学习模型生成的虚拟参考帧的帧间预测方法,可以增加帧间预测的效果并提高编码效率。
技术特征:1.一种由视频解码装置执行的视频解码方法,包括:
2.根据权利要求1所述的视频解码方法,其中,所述插值模型是下列模型中的一种:
3.根据权利要求1所述的视频解码方法,其中,所述视频编码装置利用基于由所述插值模型生成的推断帧和原始帧之间的差值的损失函数来更新所述插值模型的所述可变系数网络以生成所述可变系数值。
4.根据权利要求1所述的视频解码方法,其中,所述插值模型进一步包括固定系数网络,并且所述固定系数网络的固定系数值经过基于整个原始参考帧的预训练生成并根据预定的协议设置。
5.根据权利要求4所述的视频解码方法,其中,所述插值模型的所述可变系数网络连接到所述固定系数网络的后端。
6.根据权利要求1所述的视频解码方法,其中,按帧单位或至少一个图片组(gop)单位对所述可变系数值进行解码。
7.根据权利要求1所述的视频解码方法,其中,生成所述合并候选包括:
8.根据权利要求7所述的视频解码方法,其中,当所述时间合并候选的参考帧和存在与所述当前块相同位置的块的图片都是虚拟参考帧时,将零运动矢量设置为所述合并候选。
9.根据权利要求1所述的视频解码方法,进一步包括:
10.根据权利要求9所述的视频解码方法,其中,添加所述继承的仿射amvp候选包括,当所述继承的仿射amvp候选的参考图片和所述当前块的参考图片为相同的参考图片时并且当所述相同的参考图片为所述虚拟参考帧时,添加零运动矢量作为所述仿射amvp候选。
11.根据权利要求9所述的视频解码方法,其中,添加所述构建的仿射amvp候选包括,当所述构建的仿射amvp候选的所有控制点运动矢量的参考图片和所述当前块的参考图片为相同的参考图片时并且当所述相同的参考图片为所述虚拟参考帧时,添加零运动矢量作为参考图片。
12.一种由视频编码装置执行的视频编码方法,包括:
13.根据权利要求12所述的视频编码方法,其中,利用基于由所述插值模型生成的推断帧和原始帧之间的差值的损失函数来更新所述插值模型的所述可变系数网络以生成所述可变系数值。
14.根据权利要求12所述的视频编码方法,其中,所述插值模型进一步包括固定系数网络,并且所述固定系数网络的固定系数值经过基于整个原始参考帧的预训练生成并根据预定的协议设置。
15.根据权利要求12所述的视频编码方法,其中,按帧单位或至少一个图片组(gop)单位对所述可变系数值进行编码。
16.一种视频解码装置,包括:
技术总结本实施例提供一种帧间预测方法,该方法:使可变系数深度学习模型自适应地学习视频的特征;将学习生成的可变系数深度学习模型参数从视频编码装置发送到视频解码装置;以及参考由可变系数深度学习模型生成的虚拟参考帧。
技术研发人员:姜制远,金挪茔,李订炅,朴胜煜,林和平
受保护的技术使用者:现代自动车株式会社
技术研发日:技术公布日:2024/1/12