网络中用于假设的潜在策略分布的制作方法
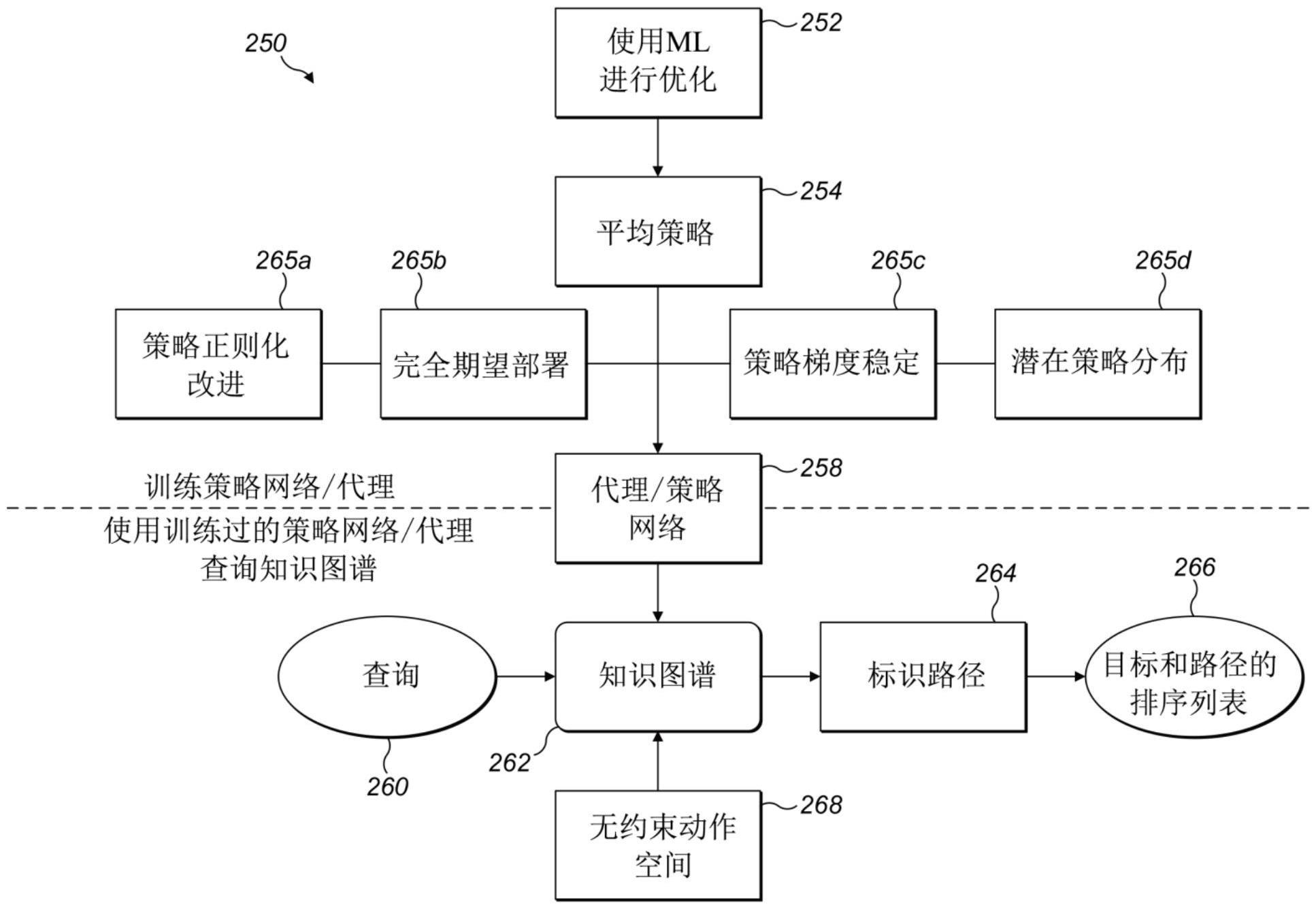
本申请涉及用于训练和应用所训练的策略网络以遍历图形结构来确定目标和关联路径的排序列表的系统、设备和方法。
背景技术:
1、使用知识图谱来推断疾病和生物机制的目标(即基因)正变得越来越普遍。一种方法是使用多跳(multi-hop)方法,其中代理(agent)在知识图谱中沿着多步路径导航,从“查询”实体遍历(traverse)到“回答”实体。当代理经过训练,从表示疾病或生物机制的查询实体导航到表示与该疾病或机制相关的目标的“回答”实体时,它可以学习(经过充分训练)预测新治疗目标的多步路径类型。这通常是通过强化学习来完成的,在这种学习中,代理因成功地从查询实体导航到“答案”实体而得到奖励。
2、现有的多跳方法存在几个问题,其中之一是从查询到目标的图中有许多可能的路径;代理可能在训练早期专注于虚假路径(即在图中存在查询和目标之间的路径,但实际上并不对应于有用或泛化(generalisable)的推理链)。先前已经通过动作退出(actiondropout)方法解决了这点,其中知识图谱中的链接被屏蔽,迫使代理探索多条路径,目的是发现更多“好”路径,表示泛化推理的路径,而不会卡在“坏”路径、虚假路径上。
3、尽管动作退出(在代理探索时随机屏蔽实体之间的链接)迫使代理探索多条路径,但它并没有激励代理探索多个目标。另一个问题是,代理只有在找到与疾病相关的已知(基准)目标时才会得到奖励,而实际上可能有更多与疾病相关但未知的目标。这先前已经通过使用奖励塑造(reward shaping)来解决,其中使用预训练的图张量分解模型来确定给基准外目标的奖励。张量分解模型提供了基准外目标实际上与疾病相关的估计;这提高了代理在找到已知基准目标时在罕见实例之外学习的能力,并避免了因合理预测而过度惩罚代理。这样做的一个问题是,该模型偏向于做出与预训练的张量分解模型相同的预测,而不是以独立和互补的方式使用数据(以做出被张量分解方法遗漏的有效预测)。作为一个工程问题,由于内存限制,多跳算法通常还需要将代理的可能动作空间截断为当前实体的n个邻居,其中n个邻居被选择为连接最紧密的那些。例如,如果一个实体在图中连接到10000个邻居,并且n=200,那么代理被限制只考虑连接程度最高的200个邻居来遍历。这限制了算法可以学习的数据,并使代理倾向于在高度连接的实体中移动。
4、由于上述原因,希望开发一种方法、系统、介质和/或设备,统称为dolphin(distributions over latent policies for hypothesising in networks,网络中用于假设的潜在策略分布),至少可以解决上述问题,并产生更高质量的路径,并在数据丰富的疾病上表现良好。
5、下面描述的实施例不限于解决上述已知方法的任何或所有缺点的实现。
技术实现思路
1、本
技术实现要素:
旨在以简化形式介绍概念的选择,下文具体实施方式将进一步描述这些概念。本发明内容不旨在识别所要求保护的主题的关键特征或基本特征,也不旨在用于确定所要求保护的主题的范围;有助于本发明工作和/或有助于实现实质上类似技术效果的变体和替代特征应被视为落入本文公开的本发明的范围。
2、本公开提供了一种方法、系统、介质和/或装置,其描述了dolphin(网络中用于假设的潜在策略分布)。dolphin适应经过训练的策略网络,其可用于通过代理在图结构上的节点实体之间导航。从输入查询,dolphin提供输出,该输出对目标(节点)和关联路径的集合进行排序。响应于输入的查询,策略网络的代理根据训练过的策略网络遍历图结构来识别目标集。训练过的策略网络或策略集决定了代理在图结构上的移动。集合中的每个策略都可以通过训练进行优化,以增加通过图结构导航到适合在策略集上建立概率分布的训练目标或对象实体的似然性(likelihood)。
3、第一方面,本公开提供了一种计算机实现方法,用于从图结构的查询中确定一个或多个目标节点和关联路径,包括:接收对图结构的查询,其中查询包括至少一个查询节点的数据表示;基于策略网络,响应于查询来识别一个或多个目标节点,其中策略网络被配置为根据与策略网络相关联的潜在策略分布来确定一个或多个目标节点;通过与策略网络相关的搜索来遍历图结构,其中搜索被配置为从查询节点导航到一个或多个被识别出的目标节点以确定关联路径;以及输出对于查询的一个或多个目标节点和关联路径的列表,其中列表根据潜在策略分布进行排序。
4、第二方面,本公开提供一种从图结构生成策略网络的计算机实现方法,用于前述任一项权利要求所述的计算机实现方法,所述计算机实现方法包括:接收第一策略,其中第一策略包括策略集,每个策略以相对于图结构的训练三元组为条件;通过最小化第一策略的策略集之间的熵差来优化第一策略以生成第二策略;以及基于生成的与潜在策略分布相关的第二策略建立策略网络。
5、第三方面,本公开提供了一种用于确定目标和关联路径的排序列表的装置,该装置包括:输入组件,配置为接收对图结构的查询,其中查询包括至少一个查询节点的数据表示;处理组件,配置为基于策略网络,响应于查询来识别一个或多个目标节点,其中策略网络被配置为根据与策略网络相关联的潜在策略分布来确定一个或多个目标节点;反应组件,配置为通过与策略网络相关的搜索遍历图结构,其中搜索被配置为从查询节点导航到一个或多个被识别出的目标节点以确定关联路径;以及输出组件,配置为输出对于查询的一个或多个目标节点和关联路径的列表,其中列表根据潜在策略分布进行排序。
6、本文描述的方法可以通过在有形存储介质上以机器可读形式的软件来执行,例如,以包括计算机程序代码的计算机程序的形式执行,当该程序在计算机上运行时并且计算机程序可以具体化在计算机可读介质上适于执行本文描述的任何方法的所有步骤的。有形(或非瞬态)存储介质的例子包括磁盘、拇指驱动器(thumb drive)、存储卡等,但不包括传播信号。该软件能够适用于在并行处理器或串行处理器上执行,以便方法步骤可以以任何适当的顺序或同时执行。
7、本申请承认固件和软件可以是有价值的、分开交易的商品。它旨在包含这样的软件:其在“简易的”或标准硬件上运行或控制“简易的”或标准硬件,以实现所需的功能。它还旨在包含这样的软件:其“描述”或定义硬件的配置,如hdl(hardware descriptionlanguage,硬件描述语言)软件,用于设计硅芯片,或配置通用可编程芯片,以实现所需的功能。
8、如对技术人员来说是显而易见的,优选特征可以适当地结合起来,并可以与发明的任何方面结合起来。
技术特征:
1.一种计算机实现方法,用于从图结构的查询中确定一个或多个目标节点和关联路径,包括:
2.根据权利要求1所述的计算机实现方法,其中所述策略网络根据潜在策略分布在所述图结构上提供在一个时间步上采取一个或多个动作的概率。
3.根据权利要求1或2所述的计算机实现方法,其中所述策略网络相对于从查询节点到一个或多个目标节点的关联路径上的时间步上所有可用动作的均匀分布而被正则化。
4.根据前述任一项权利要求所述的计算机实现方法,其中所述策略网络通过考虑期望奖励的基线估计和最后时间步所有可用动作的期望而被稳定。
5.根据前述任一项权利要求所述的计算机实现方法,其中所述策略网络控制动作空间,所述动作空间包括存储为一个或多个可变长度张量的时间步的每个动作。
6.根据前述任一项权利要求3所述的计算机实现方法,其中遍历所述图结构的高度连接部分的关联路径相对于正则化的策略网络而被惩罚。
7.根据前述任一项权利要求所述的计算机实现方法,其中输出对于查询的一个或多个目标节点和关联路径的列表进一步包括:基于一个或多个预先确定的标准来选择关联路径。
8.根据前述任一项权利要求所述的计算机实现方法,其中所述搜索包括定向搜索。
9.根据前述任一项权利要求所述的计算机实现方法,进一步包括:随查询接收第二输入,其中第二输入在训练时被定义;其中,第二输入包括多个时间步中的至少一个、向量嵌入维度,或其组合;其中,在生成一个或多个目标节点时使用第二输入。
10.一种从图结构生成策略网络的计算机实现方法,用于前述任一项权利要求所述的计算机实现方法中,所述计算机实现方法包括:
11.根据权利要求10所述的计算机实现方法,其中第一策略对应于生成模型。
12.根据权利要求11所述的计算机实现方法,其中所述生成模型包括变分自动编码器的编码器。
13.根据权利要求11或12所述的计算机实现方法,其中第一策略包含潜变量,潜变量呈现从开始节点到目标节点遍历图结构的路径的时间步。
14.根据权利要求13中所述的计算机实现方法,其中路径的时间步受第一策略控制。
15.根据权利要求10至14中任一项所述的计算机实现方法,其中第一策略被配置为使从查询开始遍历图结构到达至少一个训练目标的概率最大化。
16.根据权利要求15所述的计算机实现方法,其中到达至少一个训练目标的概率为零,使得在有限数量的时间步后,没有关联路径到达训练样本,通过用从图结构的目标中均匀采样的一个或多个不同目标替换至少一个训练目标来进行平滑化。
17.根据权利要求15或16所述的计算机实现方法,其中通过使用一个或多个机器学习模型来实现遍历图结构到达至少一个训练目标的概率。
18.根据权利要求15至17所述的计算机实现方法,其中一个或多个机器学习模型包括基于策略的强化学习模型。
19.根据权利要求10至18中任一项所述的计算机实现方法,其中使用kullback-leibler散度导出最小化第一策略的策略集之间的熵差。
20.根据权利要求10至19中任一项所述的计算机实现方法,其中与策略网络相关联的第二策略是部分固定的,以实现一种形式的正则化。
21.根据前述任一项权利要求所述的计算机实现方法,其中图结构是与知识库相关联的知识图谱。
22.根据前述任一项权利要求所述的计算机实现方法,其中查询或训练三元组包括主体实体、关系实体、对象实体及其实体组合中的至少两个。
23.根据前述任一项权利要求所述的计算机实现方法,其中查询或训练三元组是基于疾病-目标的查询,包括疾病主体实体、目标对象实体和表示它们之间关系的关系实体。
24.一种策略网络,其源自以至少一个主体实体和关系实体为条件的知识图谱,以从根据权利要求10至23中任一项所述的计算机实现方法生成一个或多个对象实体。
25.根据权利要求24所述的策略网络,其中策略网络包括潜在策略分布,使得代理基于收到的对知识图谱的查询在从实体导航到关联实体时,通过最大化所接收到的期望奖励来遍历知识图谱,以确定一个或多个对象实体。
26.根据前述任一项权利要求所述的计算机实现方法或策略网络,其中所述图结构或知识图谱包括表示至少一组实体的多个节点,其中所述多个节点中的每个节点通过关系边而连接到所述多个节点中的一个或多个其他节点,两个节点之间的每个关系边表示一种关系。
27.根据前述任一项权利要求所述的计算机实现方法或策略网络,其中所述策略网络被训练成从表示疾病或生物机制的查询实体导航到表示与所述疾病或机制相关目标的结果实体的知识图谱。
28.根据前述任一项权利要求所述的计算机实现方法或策略网络,所述图结构的实体进一步包含或表示与来自以下群组的实体类型相关联的实体数据:基因、疾病、化合物/药物;蛋白质、化学、器官、生物;目标;或与生物信息学或化学信息学等相关联的任何其他实体类型。
29.一种计算机可读介质,包括存储在其上的计算机可读代码或指令,当所述计算机可读代码或指令在处理器上执行时,使处理器实现根据前述权利要求1至28中任一项所述的计算机实现方法。
30.一种装置,包括处理器、存储器和通信接口,所述处理器连接到所述存储器和通信接口,其中所述装置适于或配置为实现根据权利要求1至28中任一项所述的计算机实现方法。
31.一种用于确定目标和关联路径的排序列表的装置,所述装置包括:
32.根据权利要求31所述的装置,进一步配置为实现根据权利要求1至28中任一项所述的计算机实现方法。
技术总结
本公开的实施例提供了用于从图结构的查询确定一个或多个目标节点和关联路径的系统、装置和方法。该方法接收对图结构的查询,其中查询包括至少一个查询节点的数据表示。该方法基于策略网络,响应于查询来识别一个或多个目标节点,其中策略网络被配置为根据与策略网络相关联的潜在策略分布确定一个或多个目标节点。该方法通过与策略网络相关的搜索遍历图结构,其中搜索被配置为从查询节点导航到一个或多个被识别出的目标节点,以确定关联路径。该方法输出对于查询的一个或多个目标节点和关联路径的列表,其中列表根据潜在策略分布进行排序。
技术研发人员:D·L·尼尔,D·S·科内尔
受保护的技术使用者:伯耐沃伦人工智能科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!