在数据存储中存储和搜索数据的制作方法
本发明涉及在数据存储中存储和搜索数据的措施。这样的数据可以是机器学习系统模型数据,即机器学习系统使用的机器学习模型的数据。这样的数据的示例包括但不限于机器学习模型的参数数据和/或状态数据。机器学习系统可以是实时交易处理系统。
背景技术:
1、过去二十年来,数字支付迅猛发展,超过四分之三的全球支付使用某种形式的支付卡或电子钱包。销售点系统逐渐变得数字化,而不是基于现金。简而言之,全球商业系统现在严重依赖电子数据处理平台。这带来了许多工程上的挑战,这些挑战主要不是普通(lay)用户所面临的。例如,数字交易需要实时完成,即计算机设备在购买时经历的延迟水平最小。数字交易还需要是安全的,并且能够抵御攻击和利用。数字交易的处理也受到全球电子支付系统的历史发展的制约。例如,许多基础设施仍然是围绕为50多年前使用的主框架架构设计的模型配置的。
2、随着数字交易的增加,新的安全风险也变得明显。数字交易为欺诈和恶意活动带来了新的机会。2015年,据估计有7%的数字交易是欺诈性的,并且随着更多经济活动在线的转变,这一数字只会增加。欺诈损失正在增加。
3、虽然欺诈等风险对参与商业的公司来说是经济问题,但是用于处理交易的技术系统的实现是一种工程上的挑战。传统地,银行、商家和发卡机构开发了“纸质”规则或程序,“纸质”规则或程序由办事员手动实施以标记或阻止某些交易。随着交易变得数字化,建立用于处理交易的技术系统的一种方法是向计算机工程师提供这些开发的标准集,并且要求计算机工程师使用交易的数字表示来实现它们,即将手写规则转换为可以应用于电子交易数据的编码逻辑语句。随着数字交易量的增长,这种传统方法遇到了若干个问题。首先,任何应用的处理都需要“实时”进行,例如具有毫秒延迟。第二,每秒需要处理数千个交易(例如,常见的“负荷”可能是每秒1000至2000),其中负载会随着时间的推移而意外变化(例如,新产品或一组票证的推出可以容易地将平均负荷水平提高若干倍)。第三,出于安全原因,交易处理器和银行的数字存储系统通常是孤立的或分区的,然而数字交易通常涉及互连的商业系统网络。第四,现在可以对实际报告的欺诈和预测的欺诈进行大规模分析。这表明传统的欺诈检测方法存在不足;准确率低,以及误报率高。这将对数字交易处理产生实际影响,更多真正的销售点和在线购买被拒绝,并且那些试图利用新数字系统的人通常会逍遥法外。
4、在过去的几年中,对交易数据的处理采用了更多的机器学习方法。随着机器学习模型在学术界的成熟,工程师已经开始尝试将其应用于交易数据的处理。然而,这再次遇到了问题。即使为工程师提供学术或理论上的机器学习模型并且要求实现它,这也并不简单。例如,大规模交易处理系统的问题开始发挥作用。机器学习模型不像在实验室中那样奢侈地拥有无限推理时间。这意味着在实时环境中实现某些模型根本是不实际的,或者它们需要进行重大调整以允许在真实世界服务器所经历的量级下进行实时处理。此外,工程师需要应对在基于访问安全性的孤立或分区的数据上以及在数据更新的速度极快的情况下实现机器学习模型的问题。因此,构建交易处理系统的工程师所面临的问题可以被视为类似于网络或数据库工程师所面临的问题;需要应用机器学习模型,但要满足处理基础设施设置的系统吞吐量和查询响应时间约束。这些问题没有简单的解决方案。事实上,许多交易处理系统是保密的、专有的并且基于旧技术这一事实,意味着工程师不具备在这些相邻领域开发的知识体系,并且经常面临交易处理领域特有的挑战。此外,大规模实用机器学习的领域仍然缺乏经验,工程师可以依赖的既定设计模式或教科书很少。
5、如以上所指出的,构建交易处理系统的工程师可能面临与数据库工程师面临的问题类似的问题。这样的数据库相关问题的示例包括但不限于创建、配置、管理、维护、使用、结构、优化、安全和组织。然而,用于在交易处理系统中使用的数据库的需求,特别是那些实现机器学习系统和提供实时处理的数据库的需求,可能与其他技术领域中的数据库需求显著不同。例如,这样的交易处理系统可能需要提供以下中的一个或更多个:(i)实时数据库读取能力,(ii)在数据库管理的停机时间有限或没有停机时间的情况下的“在线”交易处理能力的高可用性,(iii)处理可以快速建立的大量状态数据的能力,(iv)高稳定性和可靠性,(v)数据安全性,以及(vi)处理来自多个不同客户端的访问的能力。
6、写入时复制快照是大多数现有的数据库系统的主要特征。另外,在现有的数据库系统中,可以在现有的数据集之上复制新数据集。然而,现有的数据集与新数据集的大小线性地比例。另外,在现有的数据库系统中,大的修改无法自动进行,或者无法与访问同一数据集的其他客户端同时进行。
技术实现思路
1、本发明的各方面在所附独立权利要求中阐述。然后在所附的从属权利要求中阐述了本发明的某些变型。在下面的详细描述中介绍了其他的方面、变型和示例。
技术特征:
1.一种在数据存储中搜索数据的方法,所述数据存储包括:
2.根据权利要求1所述的方法,其中,所述数据项与关于正在执行实时异常检测的实体相关联。
3.根据权利要求1或2所述的方法,其中,所述数据包括用于机器学习模型的参数数据和/或状态数据。
4.根据权利要求1至3中任一项所述的方法,其中,所述方法包括,如果返回所述第二数据,则使得所述第二数据与所述数据项相关联地被存储在所述第一数据集中。
5.根据权利要求4所述的方法,其中,所述使得包括,除了将所述第一数据与所述数据项相关联地存储在所述第一数据集中之外,还使得所述第二数据与所述数据项相关联地被存储在所述第一数据集中。
6.根据权利要求4或5所述的方法,包括使得时间戳数据被存储在所述数据存储中,所述时间戳数据指示所述第二数据何时与所述数据项相关联地被存储在所述第一数据集中。
7.根据权利要求1至6中任一项所述的方法,其中,所述第二数据集包括另外的数据,并且其中,使得所述另外的数据不被存储在所述第一数据集中,同时所述第二数据项与所述数据项相关联地被存储在所述第一数据集中。
8.根据权利要求7所述的方法,其中,所述另外的数据与所述数据项相关联地被存储在所述第二集中,其中,覆盖数据元素选择元数据指示所述第二数据与所述数据项相关联地被存储在所述第一数据集中、并且所述另外的数据不与所述数据项相关联地被存储在所述第一数据集中,并且其中,所述方法包括基于所述覆盖数据元素选择元数据而禁止所述另外的数据与所述数据项相关联地被存储在所述第一数据集中。
9.根据权利要求7所述的方法,其中,所述另外的数据与另外的数据项相关联地被存储在所述第二数据集中。
10.根据权利要求1至9中任一项所述的方法,其中,所述第一数据集是子数据集,其中,所述数据存储还包括第三数据集,并且其中,所述第三数据集是所述第一数据集的父。
11.根据权利要求10所述的方法,其中,所述第一数据集潜在地包括所述第三数据集中未包括的数据。
12.根据权利要求10或11所述的方法,其中,所述方法包括,响应于所述搜索未在所述第一数据集中找到所述数据项,在所述第三数据集中搜索所述数据项,
13.根据权利要求12所述的方法,其中,所述数据存储还包括作为所述第三数据集的覆盖的数据集,并且其中,所述方法包括在作为所述第三数据集的覆盖的数据集中搜索所述数据项。
14.根据权利要求10至13中任一项所述的方法,其中,所述第三数据集也是所述第二数据集的父。
15.根据权利要求10至13中任一项所述的方法,其中,所述第三数据集不是所述第二数据集的父。
16.根据权利要求10至15中任一项所述的方法,其中,所述第三数据集在所述第一数据集和/或所述第二数据集的创建时变得不可变。
17.根据权利要求1至16中任一项所述的方法,其中,所述第二数据集在成为所述第一数据集的覆盖时变得不可变。
18.根据权利要求1至17中任一项所述的方法,包括对所述数据存储中的给定数据集执行清理操作,其中,所述清理操作包括:
19.根据权利要求1至18中任一项所述的方法,其中,在所述第一数据集的创建时,所述第一数据集是空的,以及/或者其中,在所述第二数据集的创建时,所述第二数据集是空的。
20.根据权利要求1至19中任一项所述的方法,其中,所述数据存储还包括:
21.根据权利要求1至20中任一项所述的方法,其中,如果在所述第一数据集中未找到所述数据项,并且如果在所述第二数据集中找到所述数据项,则所述返回包括返回与所述数据项相关联地被存储在所述第二数据集中的所述第二数据。
22.根据权利要求1至21中任一项所述的方法,包括:
23.一种在数据存储中存储数据的方法,所述数据存储包括:
24.一种在数据库中搜索机器学习模型数据的方法,所述数据库包括:
25.一种系统,其被配置成执行根据权利要求1至24中任一项所述的方法。
技术总结
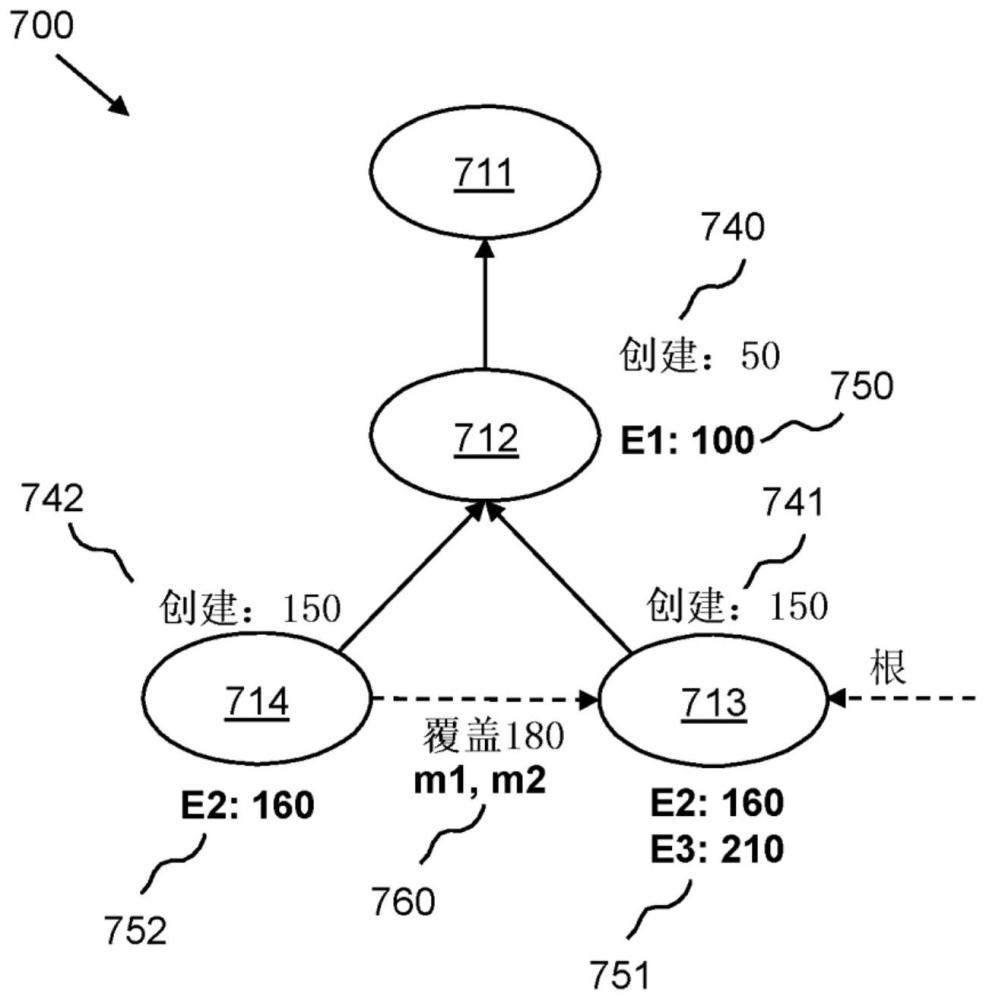
在数据存储的第一数据集和/或第二数据集中搜索数据项。如果在第一数据集中找到数据项,并且如果在第二数据集成为第一数据集的覆盖之后在第一数据集中更新数据项,则返回与数据项相关联地存储在第一数据集中的第一数据。如果在第一数据集和第二数据集中找到数据项,并且如果在第一数据集中更新数据项之后第二数据集成为第一数据集的覆盖,则返回与数据项相关联地存储在第二数据集中的第二数据。基于覆盖元数据来识别第二数据集,覆盖元数据指示第二数据集是第一数据集的覆盖。
技术研发人员:西蒙·库柏,大卫·埃克斯赛尔
受保护的技术使用者:特征空间有限公司
技术研发日:
技术公布日:2024/7/18
- 还没有人留言评论。精彩留言会获得点赞!