对抗样本训练方法、装置、设备、存储介质及计算机程序与流程
本申请实施例涉及机器学习领域,特别涉及一种对抗样本训练方法、装置、设备、存储介质及计算机程序。
背景技术:
1、深度学习模型在许多领域都得到了广泛应用,虽然模型的精度越来越高,但同时也容易受到攻击,例如:对抗攻击。对抗攻击是指对原数据集施加轻微扰动以生成对抗样本,并通过对抗样本欺骗目标模型的过程,研究对抗攻击可以更好地对机器学习模型的脆弱部分做出判断,从而提高模型的鲁棒性。
2、相关技术中,提高模型的鲁棒性通常需要提高对抗样本的迁移性,使得对抗样本可以对更多种类的目标模型产生攻击。为了产生迁移性更强的对抗样本,通常采用基于动量的方法生成对抗样本,以提高对抗样本的迁移性。
3、然而,在模型参数未知以及数据量较少的黑盒攻击场景下,对抗样本的迁移性较差,且当前黑盒攻击中迁移攻击的性能尚不如意,采用上述方法无法提高对抗样本的迁移性能。
技术实现思路
1、本申请实施例提供了一种对抗样本训练方法、装置、设备、存储介质及计算机程序,能够提高对抗样本的迁移性,对目标模型的模型漏洞进行精准定位,从而保护目标模型。所述技术方案如下。
2、一方面,提供了一种对抗样本训练方法,所述方法包括:
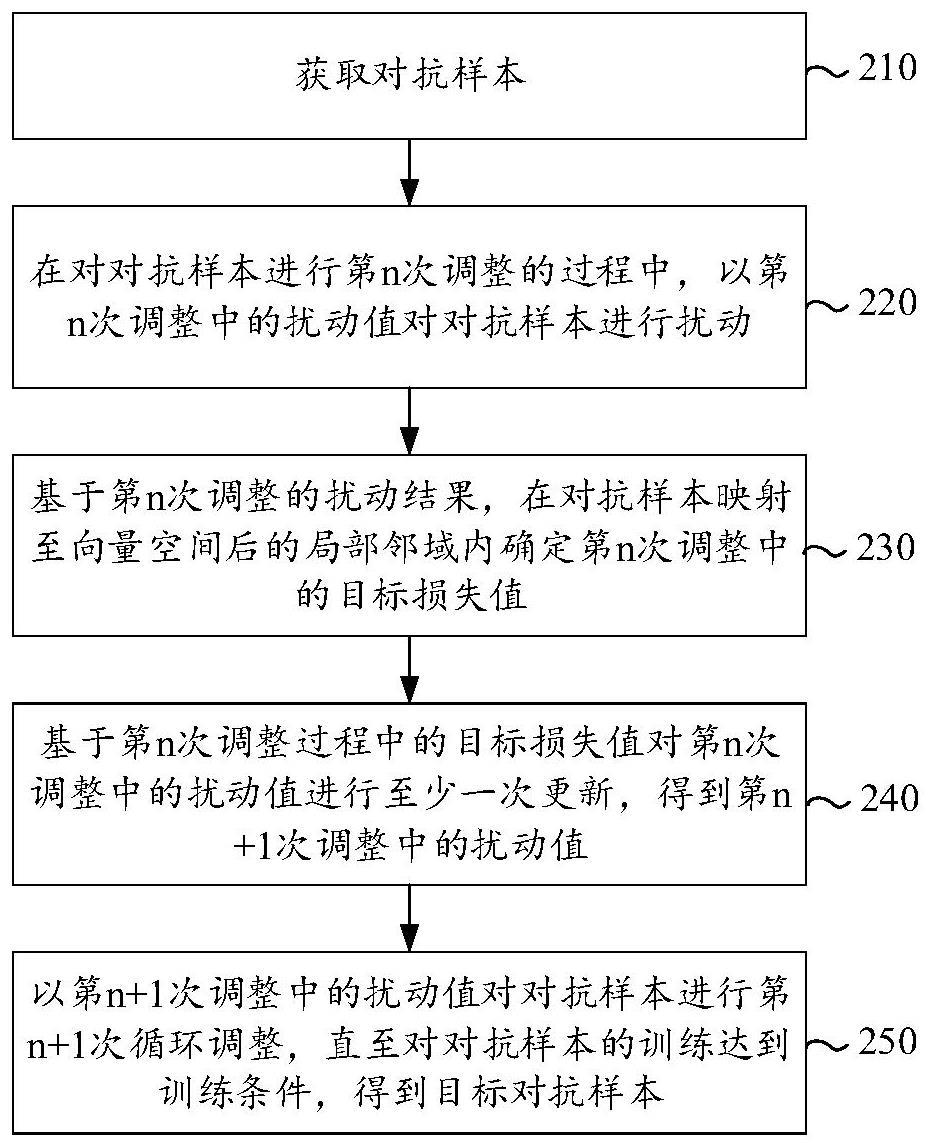
3、获取对抗样本,所述对抗样本为待进行调整的样本;
4、在对所述对抗样本进行第n次调整的过程中,以第n次调整中的扰动值对所述对抗样本进行扰动,n为正整数;
5、基于所述第n次调整的扰动结果,在所述对抗样本映射至向量空间后的局部邻域内确定所述第n次调整中的目标损失值;
6、基于所述第n次调整中的目标损失值对所述第n次调整中的扰动值进行至少一次更新,得到第n+1次调整中的扰动值;
7、以所述第n+1次调整中的扰动值对所述对抗样本进行第n+1次循环迭代调整,直至对所述对抗样本的训练达到训练条件,得到目标对抗样本。
8、另一方面,提供了一种对抗样本训练装置,所述装置包括:
9、获取模块,用于获取对抗样本,所述对抗样本为待进行调整的样本;
10、扰动模块,用于在对所述对抗样本进行第n次调整的过程中,以第n次调整中的扰动值对所述对抗样本进行扰动,n为正整数;
11、确定模块,用于基于所述第n次调整的扰动结果,在所述对抗样本映射至向量空间后的局部邻域内确定所述第n次调整中的目标损失值;
12、更新模块,用于基于所述第n次调整中的目标损失值对所述第n次调整中的扰动值进行至少一次更新,得到第n+1次调整中的扰动值;
13、调整模块,用于以所述第n+1次调整中的扰动值对所述对抗样本进行第n+1次循环迭代调整,直至对所述对抗样本的训练达到训练条件,得到目标对抗样本。
14、另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上述本申请实施例中任一所述对抗样本训练方法。
15、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如上述本申请实施例中任一所述的对抗样本训练方法。
16、另一方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例中任一所述的对抗样本训练方法。
17、本申请实施例提供的技术方案带来的有益效果至少包括:
18、以第n次调整中的扰动值对对抗样本进行扰动后,在对抗样本对应的局部邻域内确定目标损失值,根据目标损失值对第n次调整中的扰动值进行更新,得到第n+1次调整中的扰动值,以第n+1次调整中的扰动值对对抗样本进行循环迭代调整,直至得到目标对抗样本。通过上述方法,避免直接采用未经处理的对抗样本对模型进行攻击时,被成功攻击的目标模型数量、种类较少的情况,可以提高获取得到的对抗样本的迁移性,使得经调整后得到的目标对抗样本可以攻击更多的目标模型,从而更准确地评估目标模型被攻击的风险,并更精准地定位到不同目标模型的模型漏洞,以便进一步提升模型对应产品的安全性能,避免受到来自攻击者的攻击,从而更全面地保护目标模型。
技术特征:
1.一种对抗样本训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述第n次调整的扰动结果,在所述对抗样本映射至向量空间后的局部邻域内确定所述第n次调整中的目标损失值,包括:
3.根据权利要求2所述的方法,其特征在于,所述从所述至少一个损失值中,确定所述第n次调整中的所述目标损失值,包括:
4.根据权利要求1至3任一所述的方法,其特征在于,所述基于所述第n次调整中的目标损失值对所述第n次调整中的扰动值进行至少一次更新,得到第n+1次调整中的扰动值,包括:
5.根据权利要求4所述的方法,其特征在于,所述对所述第n次调整中的目标损失值进行梯度运算,确定所述第n次调整中的扰动值更新量,包括:
6.根据权利要求1至3任一所述的方法,其特征在于,所述以所述第n+1次调整中的扰动值对所述对抗样本进行第n+1次循环迭代调整,包括:
7.根据权利要求6所述的方法,其特征在于,所述替代模型对应替代损失函数;
8.根据权利要求7所述的方法,其特征在于,所述基于所述模型输出值和所述替代损失函数,对所述对抗样本进行第n+1次循环迭代调整,包括:
9.根据权利要求1至3任一所述的方法,其特征在于,所述直至对所述对抗样本的训练达到训练条件,得到目标对抗样本,包括:
10.根据权利要求1至3任一所述的方法,其特征在于,所述获取对抗样本,包括:
11.根据权利要求1至3任一所述的方法,其特征在于,所述基于所述第n次调整中的目标损失值对所述第n次调整中的扰动值进行至少一次更新,得到第n+1次调整中的扰动值,包括:
12.根据权利要求11所述的方法,其特征在于,所述基于所述第n次调整中第k次更新的扰动值,得到所述第n+1次调整中的扰动值,包括:
13.一种对抗样本训练装置,其特征在于,所述装置包括:
14.一种计算机设备,其特征在于,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如权利要求1至12任一所述的对抗样本训练方法。
15.一种计算机可读存储介质,其特征在于,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如权利要求1至12任一所述的对抗样本训练方法。
16.一种计算机程序产品,其特征在于,包括计算机程序或指令,所述计算机程序或指令被处理器执行时实现如权利要求1至12任一所述的对抗样本训练方法。
技术总结
本申请公开了一种对抗样本训练方法、装置、设备、存储介质及计算机程序,涉及机器学习领域。该方法包括:获取对抗样本;在对对抗样本进行第n次调整的过程中,以第n次调整中的扰动值对对抗样本进行扰动;基于第n次调整的扰动结果,在对抗样本的局部邻域内确定第n次调整中的目标损失值;基于第n次调整中的目标损失值对第n次调整中的扰动值进行至少一次更新,得到第n+1次调整中的扰动值;以第n+1次调整中的扰动值对对抗样本进行第n+1次循环迭代调整,得到目标对抗样本。通过以上方式,可以提高对抗样本的迁移性,更准确地评估目标模型被攻击的风险,从而更全面地保护目标模型。本申请可应用于云技术、人工智能、智慧交通等各种场景。
技术研发人员:吴保元,秦泽钰,樊艳波,刘奕,张勇,王珏
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!