一种基于声发射的阀门内漏速率检测方法
1.本发明涉及阀门声发射传感检测技术领域,尤其涉及一种基于声发射的阀门内漏速率检测方法。
背景技术:
2.在现代许多的工厂生产以及楼栋消防系统中,阀门是非常重要的一环,其基本作用是控制管道中流体的接通或者切断、调节下一环介质中的流量、保护管路或者设备的正常运行等。它广泛地应用在石油、化工、电站、冶金和船舶等工业以及楼栋消防等民用领域。为确保管道介质的安全运输,阀门应具有良好的密封性能。由于阀门长期处于高温高压以及强腐蚀性的环境当中,而且阀门属于密封性的器件,容易出现划伤变形等现象,因此阀门在关闭状态时会伴随有内漏现象的产生,造成泄露和维护困难等问题。密封失效主要源于松动的密封或密封表面损坏,如果密封球阀与阀体之间存在间隙和压力差,则会发生阀泄漏。阀门的更换主要取决于阀门内漏量的大小,因此对阀门速率的定量研究得十分有必要。如果能够在早期对阀门的泄露以及工作状态进行实时监测,获得阀门工作的数据并诊断内漏的程度便能够更好的进行检测和容错控制。
3.针对阀门的内漏问题,主要的有损监测方法有加压检测法、真空检测法和气泡法,这些方法不仅要求阀门停用且必须从管件上拆卸下来进行检测;无损检测主要有振动法、红外法、超声波检测以及声发射检测等方法。传统的方法很难实现对设备的动态检测,声发射检测具有实时、连续监测的特点,是目前为止比较有效的阀门无损检测方法之一。
4.阀门内漏的影响主要取决于阀门内漏速率。但是,由于阀门的内漏的机理复杂,内部阀门内漏速率是一个复杂机理过程;建立模型的方法条件较为苟刻,较难实现。因此,准确预测阀门泄漏率是一个重要的挑战。目前大部分的检测系统主要采用现成通用的采集设备采集声发射数据,运用简单的时频域特征进行浅层模型的训练,往往无法达到对阀门泄露更多深层信息的了解。
技术实现要素:
5.1.要解决的技术问题
6.本发明的目的是为了解决现有技术中大部分的检测系统主要采用现成通用的采集设备采集声发射数据,运用简单的时频域特征进行浅层模型的训练,往往无法达到对阀门泄露更多深层信息了解的问题,而提出的一种基于声发射的阀门内漏速率检测方法。
7.2.技术方案
8.为了实现上述目的,本发明采用了如下技术方案:
9.一种基于声发射的阀门内漏速率检测方法,包括如下步骤:
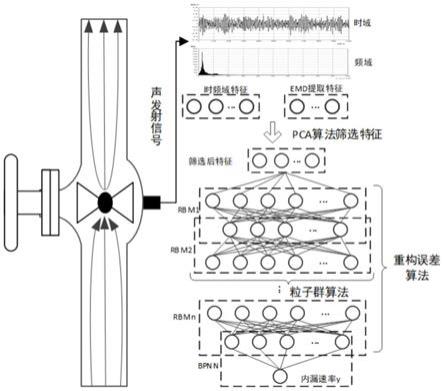
10.步骤1:对于不同的阀门内漏速率状态下的阀门阀体处的声发射信号进行采样,其中的数据包括阀门模拟内漏时不同程度的小角度开度的声发射信号数据和对应的先验内漏速率信息,生成采样数据集x:
11.x={x1,x2,...,xr}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
12.步骤2:将步骤1中采集到的时域信号x=[x(1),x(2),...,x(n)]进行离散傅里叶变换到频域信号s=[s(1),s(2),...,s(n
fft
)];并将时域信号经过emd分解得到5个imf分量;同时提取阀前压力、时域和频域的关键特征集以及emd各个imf分量的幅度、能量和hht频率等相关特征组成数据集dn:
[0013]dn
={d1,d2,...,dn}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0014]
步骤3:将步骤2中的数据集dn通过主成分分析(pca)方法进行筛选和降维,对原始特征集进行预处理,去除冗余信息,增加剩余基向量的表征能力,构成新的特征组成数据集dm:
[0015]dm
={d1,d2,...,dm}m≤n
[0016]
(3)
[0017]
步骤4:考虑到输入和输出数据之间的数据量纲的差别,将步骤2)中所得的数据集dm进行归一化处理,构成新的数据集d',对数据集d'运用“k折交叉验证”方法进行处理,生成k组训练集和测试集的组合;
[0018]
步骤5:取得步骤3中所得的所有样本数据用于训练深度置信网络(dbn),首先根据经验值确定并固定隐藏层的神经元个数,当重构误差相对最小时,确定当前的dbn网络层数l;然后根据重构误差算法确定的l层dbn,通过粒子群算法来进行dbn隐含层节点数的优化,最终确定dbn的网络结构;
[0019]
步骤6:对待测的未知内漏速率状态下的阀门阀体处的声发射信号进行采样,所得到的样本使用步骤3的方法提取特征值,在使用步骤4中的方法进行归一化,构造标准特征向量,输入到步骤5生成的确定结构的dbn网络中,进行阀门内漏速率的预测,从而实现基于声发射的阀门内漏速率检测。
[0020]
优选地,所述步骤1的阀门的声发射信号的数据采样过程为:在模拟不同内漏速率的r种不同的阀门小开度的状态下,分别采集当前阀门阀体处的声发射信号和先验的内漏速率数据,生成采样数据集x。
[0021]
优选地,所述步骤2的时域特征主要有均值、标准差、方根均值、均方根值、峰峰值、峰值、偏斜度、峭度、熵等特征;频域特征主要有平均频率、中心频率,频率标准差、频率均方根、最大幅值等;emd提取的特征主要包括每层imf分量的振铃计数、幅度、能量和hht频率等特征参数。
[0022]
优选地,所述步骤3的特征筛选主要使用的是pca主成分分析算法,意在对原始特征集进行中心化预处理,进行数据降维并增加剩余基向量的正交性,即特征向量集对先验内漏速率信息的表征能力。
[0023]
优选地,所述步骤4的归一化公式为:
[0024][0025]
式中,x'为做归一化处理后的数据序列,x为做归一化处理前的各数据序列,x
max
、x
min
分别为数据序列中的最大值和最小值,归一化处理一般是将数据变换到[0,1]之间,当预测模型计算结束后,再通过反归一化得到预测数据。
[0026]
优选地,所述步骤5的通过重构误差的方法来确定dbn网络隐含层的层数,重构误差是根据原始数据与重构的差异,计算重构误差公式如下:
[0027][0028]
其中:n为样本个数,m为像素个数,p为网络计算的值,d为真实值,px为取值个数或范围,最终的判断规则如下:
[0029][0030]
式中:ε为重构误差的预设值,l为隐藏层的层数,开始进行网络训练后,如果重构误差大于预设值,则继续增加rbm网络的层数;当低于预设定值时,保持当前层数开始进行梯度的反向微调;最终确定rbm网络的层数l。
[0031]
优选地,所述步骤5的每个隐含层的节点个数以及学习率主要通过粒子群优化算法来确定,其算法原理为:在粒子群算法中,搜索空间上的每一个点都可以看成待优化问题的潜在解,也称之为粒子,粒子会在搜索空间里面按照一定的移动方向和距离进行搜索,其中粒子的运动速度和方向更新公式如下所示:
[0032]
v[i+1]=w
×
v[i]+c1×
rand()
×
(pbest[i]-present[i])+c2×
rand()
×
(gbest-prsent[i])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0033][0034]
present[i+1]=prsent[i]+v[i+1]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0035]
其中:v[i]代表第i个粒子的速度,w代表惯性权值,c1和c2表示学习参数,rand()表示在0:1之间的随机数,pbest[i]代表第i个粒子搜索得到的最优值,gbest代表整个集群搜索到的最优值,present[i]代表第i个粒子的当前位置。
[0036]
优选地,所述粒子群优化算法的训练优化流程如下所示:
[0037]
s1:初始化一群粒子(种群规模为m),按照经验随机初始化它们的位置和速度;
[0038]
s2:根据确定的目标函数,计算当前种群每个粒子的适应度值;
[0039]
s3:训练dbn网络模型;
[0040]
s4:对于每一次的粒子运动,若当前的适应度值与经历过的最好位置pbest[i]相比更好,则将其作为新的最好位置pbest[i];同样的如果比它的整个种群的最好位置gbest更好,则将其作为最好的种群位置gbest;
[0041]
s5:根据上述公式(7)和公式(8)更新粒子群中每个粒子的速度和位置,判断是否能够到达预设的足够好的适应值或者到达了最大训练次数,如果到达就保存最好的位置并退出;如果未达到就返回步骤2继续进行训练。
[0042]
优选地,所述步骤6的dbn网络结构经过重构误差和粒子群算法确定的较优的结构,并能够较好的表达特征参数与内漏速率之间的非线性关系。
[0043]
3.有益效果
[0044]
相比于现有技术,本发明的优点在于:
[0045]
(1)本发明中,使用人工经验和算法相结合进行特征提取,由重构误差和粒子群算法优化的dbn网络来进行内漏速率的检测;在提取特征向量和构建训练的算法时,考虑到阀门声发射信号非线性和非平稳性的特点,将人工经验提取的时频域特征与emd算法自动提取的内部特征相结合,克服了以往模型中只使用单一的时频域特征或算法提取的特征的问题,增加提取特征与内漏速率输出之间的表征能力。
[0046]
(2)本发明中,重构误差和粒子群优化算法的优势在于:能够依据训练过程中的误差来在整个搜索空间进行dbn网络结构的调整,使dbn网络结构到达一个相对合理和较优的位置。
[0047]
(3)本发明中,dbn网络的优势在于:它是典型的全连接神经网络深层模型,通过利用贪婪逐层无监督训练策略对具有多个隐含层的dbn网络进行有效训练,能够建立表征所提取特征与数据输出之间更为精确的机理模型;克服浅层模型在有限样本和计算单元的情况下,复杂模型的表示能力有限并且无法有效地探索特征的规律性的问题。
附图说明
[0048]
图1为本发明中提出的基于声发射的阀门内漏速率检测方法的整体架构图;
[0049]
图2为本发明中提出的基于声发射的阀门内漏速率检测方法的重构误差算法确定隐含层数流程图;
[0050]
图3为本发明中提出的基于声发射的阀门内漏速率检测方法的粒子群算法确定dbn网络结构流程图;
[0051]
图4为本发明中提出的基于声发射的阀门内漏速率检测方法的流程图。
具体实施方式
[0052]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0053]
实施例1:
[0054]
参照图1-4,一种基于声发射的阀门内漏速率检测方法,包括如下步骤:
[0055]
步骤1:对于不同的阀门内漏速率状态下的阀门阀体处的声发射信号进行采样,其中的数据包括阀门模拟内漏时r种不同程度的小角度开度的声发射信号数据和对应的先验内漏速率信息,生成采样数据集x:
[0056]
x={x1,x2,...,xr}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0057]
步骤2:将步骤1中采集到的时域信号x=[x(1),x(2),...,x(n)]进行离散傅里叶变换到频域信号s=[s(1),s(2),...,s(n
fft
)],并将时域信号经过emd分解得到5个imf分量:
[0058]
同时提取阀前压力、时域和频域的关键特征集以及emd各个imf分量的相关特征组成数据集dn。
[0059]
其中,时域特征主要有均值、标准差、方根均值、均方根值、峰峰值、峰值、偏斜度、峭度、熵等特征;频域特征主要有平均频率、中心频率,频率标准差、频率均方根、最大幅值等;emd提取的特征主要包括每层imf分量的振铃计数、幅度、能量和hht频率等特征参数。组成特征数据集:
[0060]dn
={d1,d2,...,dn}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2);
[0061][0062]
步骤3:将步骤2中的数据集dn通过主成分分析(pca)方法进行筛选和降维,对原始特征集进行预处理,去除冗余信息,增加剩余基向量的表征能力,构成新的特征组成数据集dm。
[0063]dm
={d1,d2,...,dm} m≤n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0064]
步骤4:考虑到输入和输出数据之间的数据量纲的差别,将步骤3中所得的数据集x计算所得的特征集dm与先验流量信息进行归一化处理,构成新的数据集d',对数据集d'运用“k折交叉验证”方法进行处理,生成k组训练集和测试集的组合。归一化处理一般是将数据变换到[0,1]之间,其中归一化公式为:
[0065][0066]
式中,x'为做归一化处理后的数据序列,x为做归一化处理前的各数据序列,x
max
、x
min
分别为数据序列中的最大值和最小值。当检测模型计算结束后,再通过反归一化得到检测数据。将数据集划分为k个大小相等的互斥子集,也即d'=d1∪d2∪...∪dk;每次使用前0.6k个子集作为训练集,剩下的子集作为测试集;
[0067]
步骤5:取得步骤4中所得的所有样本数据用于训练深度置信网络(dbn),首先根据经验值确定并固定隐藏层的神经元个数,当重构误差相对最小时,确定当前的dbn网络层数l。
[0068]
通过重构误差的方法来确定dbn网络隐含层的层数,重构误差是根据原始数据与重构的差异,计算重构误差公式如下:
[0069][0070]
其中:n为样本个数,m为像素个数,p为网络计算的值,d为真实值,px为取值个数或范围。最终的判断规则如下:
[0071][0072]
式中:ε为重构误差的预设值,m为隐藏层的层数。开始进行网络训练后,如果重构误差大于预设值,则继续增加rbm网络的层数;当低于预设定值时,保持当前层数开始进行梯度的反向微调;最终确定rbm网络的层数l;
[0073]
步骤6:取得步骤5中所得的l层未知隐含层节点数深度置信网络(dbn),通过粒子群优化算法来进行dbn隐含层节点数的优化,最终确定dbn的网络结构。每个隐含层的节点个数以及学习率主要通过粒子群优化算法来确定。其算法原理为:在粒子群算法中,搜索空间上的每一个点都可以看成待优化问题的潜在解,也称之为粒子,粒子会在搜索空间里面按照一定的移动方向和距离进行搜索。其中粒子的运动速度和方向更新公式如下所示:
[0074]
v[i+1]=w
×
v[i]+c1×
rand()
×
(pbest[i]-present[i])+c2×
rand()
×
(gbest-prsent[i])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0075][0076]
present[i+1]=prsent[i]+v[i+1]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0077]
其中:v[i]代表第i个粒子的速度,w代表惯性权值,c1和c2表示学习参数,rand()表示在0:1之间的随机数,pbest[i]代表第i个粒子搜索得到的最优值,gbest代表整个集群搜索到的最优值,present[i]代表第i个粒子的当前位置。待训练的参数:各个隐含层的节点数、学习率;粒子群算法训练的基本参数如下:
[0078]
表1粒子群算法训练参数
[0079][0080]
其基本的训练优化流程如下所示:
[0081]
s1:初始化一群粒子(种群规模为m),按照经验随机初始化它们的位置和速度;
[0082]
s2:根据确定的目标函数,计算当前种群每个粒子的适应度值;
[0083]
s3:训练dbn网络模型;
[0084]
s4:对于每一次的粒子运动,若当前的适应度值与经历过的最好位置pbest[i]相比更好,则将其作为新的最好位置pbest[i];同样的如果比它的整个种群的最好位置gbest更好,则将其作为最好的种群位置gbest;
[0085]
s5:根据上述公式(7)和公式(8)更新粒子群中每个粒子的速度和位置;
[0086]
s6:判断是否能够到达预设的足够好的适应值或者到达了最大训练次数,如果到达就保存最好的位置并退出;如果未达到就返回步骤2继续进行训练。
[0087]
s7:利用训练好确定网络结构的dbn模型对待检测的数据进行阀门内漏速率检测。确定输入节点数为m,rbm隐含层数为l,输出节点数为1的dbn网络内漏速率检测模型;对于待测的未知内漏速率的状态下的阀门,由于上游和下游管道之间的压力差,阀门将由于不完全关闭而引起泄漏,此时对阀门阀体处的声发射信号进行采样,提取特征值并进行归一化来构造标准特征向量,输入到确定结构的dbn网络内漏速率检测模型,进行阀门内漏速率的预测,从而实现基于声发射信号的阀门内漏速率检测。
[0088]
本发明中,使用人工经验和算法相结合进行特征提取,由重构误差和粒子群算法优化的dbn网络来进行内漏速率的检测;在提取特征向量和构建训练的算法时,考虑到阀门声发射信号非线性和非平稳性的特点,将人工经验提取的时频域特征与emd算法自动提取的内部特征相结合,克服了以往模型中只使用单一的时频域特征或算法提取的特征的问题,增加提取特征与内漏速率输出之间的表征能力。
[0089]
本发明中,重构误差和粒子群优化算法的优势在于:能够依据训练过程中的误差来在整个搜索空间进行dbn网络结构的调整,使dbn网络结构到达一个相对合理和较优的位置。
[0090]
本发明中,dbn网络的优势在于:它是典型的全连接神经网络深层模型,通过利用贪婪逐层无监督训练策略对具有多个隐含层的dbn网络进行有效训练,能够建立表征所提取特征与数据输出之间更为精确的机理模型;克服浅层模型在有限样本和计算单元的情况下,复杂模型的表示能力有限并且无法有效地探索特征的规律性的问题。
[0091]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1