一种识别省市区的方法及装置与流程
1.本发明涉及大数据分析处理领域,具体提供一种识别省市区的方法及装置。
背景技术:
2.网络爬虫(web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
3.传统爬虫从一个或若干初始网页的url开始,获得初始网页上的url,在抓取网页的过程中,不断从当前页面上抽取新的url放入队列,直到满足系统的一定停止条件。
4.聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的url队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页url,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
5.在线生活服务方兴未艾,是各大数据公司的研究热点。但是爬取的服务设施地址往往不规范,无法直接用于分省份、分地市和分区县维度的数据分析。
技术实现要素:
6.本发明是针对上述现有技术的不足,提供一种实用性强的识别省市区的方法。
7.本发明进一步的技术任务是提供一种设计合理,安全适用的识别省市区的装置。
8.本发明解决其技术问题所采用的技术方案是:
9.一种识别省市区的方法,具有如下步骤:
10.s1、制作数据集;
11.s2、选取或自定义特征提取函数;
12.s3、选择合适分类方法训练;
13.s4、获得识别装置。
14.进一步的,在步骤s1中,制作带省市区标签的地址数据集。
15.进一步的,在步骤s2中,特征提取函数feature()从每个地址中提取至多4个特征,用jieba.analyse.extract_tags()选择tfidf值最大的3个特征词,取地址的前10个中文字符作为第四个特征。
16.进一步的,在步骤s3中,选择合适的分类算法学习地址数据集中的第二步特征,输出模型,记为nb_classifier()。
17.进一步的,在步骤s4中,所述nb_classifier()将来用于识别新地址所属省份、地市、区县的装置,输入新地址,输出所属省市区,即nb_classifier。
18.一种识别省市区的装置,包括数据集,在数据集中设计特征提取函数,所述特征提取函数从每个地址中提取至多4个特征,选择合适的分类算法输出模型,所述模型用于识别新地址所属省份、地市、区县的装置。
19.进一步的,所述数据集为带有省市区标签的地址数据集。
20.进一步的,特征提取函数feature()从每个地址中提取至多4个特征,用jieba.analyse.extract_tags()选择tfidf值最大的3个特征词,取地址的前10个中文字符作为第四个特征。
21.进一步的,选择合适的分类算法学习地址数据集中的第二步特征,输出模型,记为nb_classifier()。
22.进一步的,所述nb_classifier()将来用于识别新地址所属省份、地市、区县的装置,输入新地址,输出所属省市区,即nb_classifier。
23.本发明的一种识别省市区的方法及装置和现有技术相比,具有以下突出的有益效果:
24.本发明利用机器学习中的监督式分类算法以及前期已经标注了省市区的地址数据,搭建简便,能够直接用于分省份、分地市和分区县维度的数据分析。
附图说明
25.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
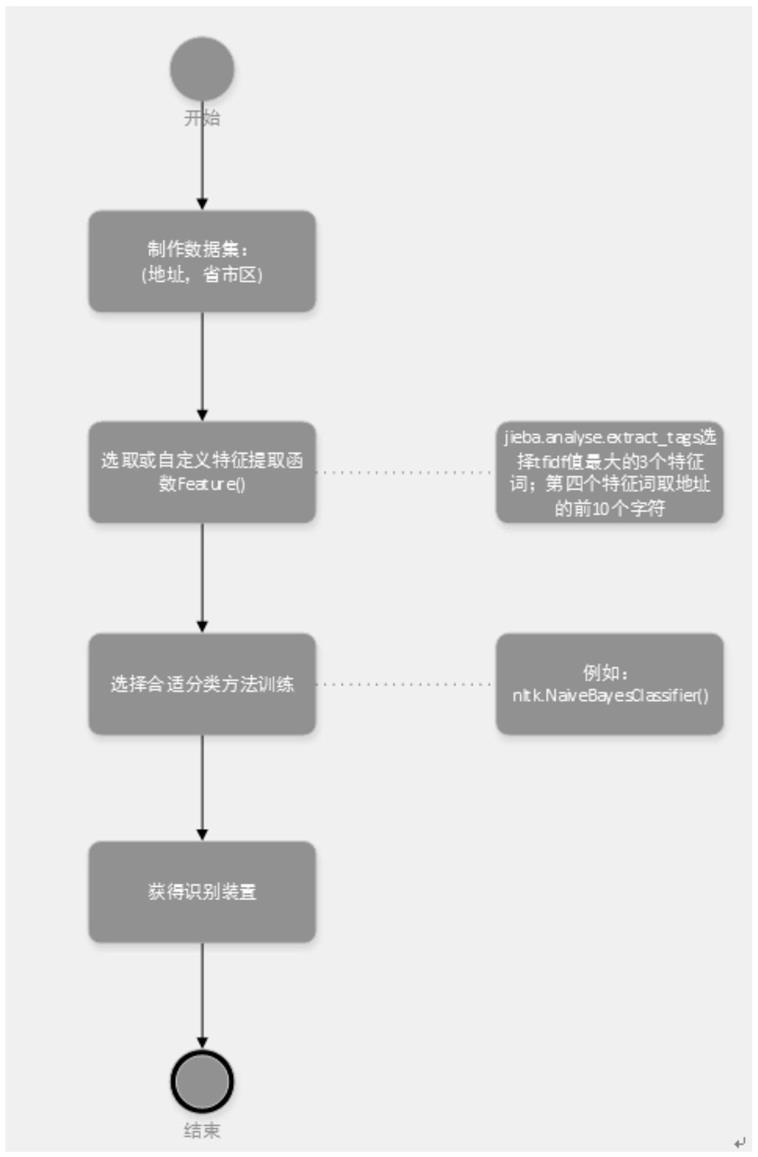
26.附图1是一种识别省市区的方法的流程示意图。
具体实施方式
27.为了使本技术领域的人员更好的理解本发明的方案,下面结合具体的实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例都属于本发明保护的范围。
28.下面给出一个最佳实施例:
29.如图1所示,本实施例中的一种识别省市区的方法,具有如下步骤:
30.s1、制作数据集;
31.制作带省市区标签的地址数据集,形如:(地址,省市区)格式。
32.s2、选取或自定义特征提取函数;
33.特征提取函数feature()从每个地址中提取至多4个特征,用jieba.analyse.extract_tags()选择tfidf值最大的3个特征词,取地址的前10个中文字符作为第四个特征。
34.s3、选择合适分类方法训练;
35.选择合适的分类算法学习地址数据集中的第二步特征,输出模型,记为nb_classifier(),例如,贝叶斯算法,对应的软件包为:nltk.naivebayesclassifier()。
36.s4、获得识别装置;
37.所述nb_classifier()将来用于识别新地址所属省份、地市、区县的装置,输入新地址,输出所属省市区,即nb_classifier。
38.一种识别省市区的装置,包括数据集,在数据集中设计特征提取函数,所述特征提取函数从每个地址中提取至多4个特征,选择合适的分类算法输出模型,所述模型用于识别新地址所属省份、地市、区县的装置。
39.其中,数据集为带有省市区标签的地址数据集。
40.特征提取函数feature()从每个地址中提取至多4个特征,用jieba.analyse.extract_tags()选择tfidf值最大的3个特征词,取地址的前10个中文字符作为第四个特征。
41.选择合适的分类算法学习地址数据集中的第二步特征,输出模型,记为nb_classifier()。
42.所述nb_classifier()将来用于识别新地址所属省份、地市、区县的装置,输入新地址,输出所属省市区,即nb_classifier。
43.上述具体的实施方式仅是本发明具体的个案,本发明的专利保护范围包括但不限于上述具体的实施方式,任何符合本发明的一种识别省市区的方法及装置权利要求书的且任何所述技术领域普通技术人员对其做出的适当变化或者替换,皆应落入本发明的专利保护范围。
44.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
技术特征:
1.一种识别省市区的方法,其特征在于,具有如下步骤:s1、制作数据集;s2、选取或自定义特征提取函数;s3、选择合适分类方法训练;s4、获得识别装置。2.根据权利要求1所述的一种识别省市区的方法,其特征在于,在步骤s1中,制作带省市区标签的地址数据集。3.根据权利要求2所述的一种识别省市区的方法,其特征在于,在步骤s2中,特征提取函数feature()从每个地址中提取至多4个特征,用jieba.analyse.extract_tags()选择tfidf值最大的3个特征词,取地址的前10个中文字符作为第四个特征。4.根据权利要求3所述的一种识别省市区的方法,其特征在于,在步骤s3中,选择合适的分类算法学习地址数据集中的第二步特征,输出模型,记为nb_classifier()。5.根据权利要求4所述的一种识别省市区的方法,其特征在于,在步骤s4中,所述nb_classifier()将来用于识别新地址所属省份、地市、区县的装置,输入新地址,输出所属省市区,即nb_classifier。6.一种识别省市区的装置,其特征在于,包括数据集,在数据集中设计特征提取函数,所述特征提取函数从每个地址中提取至多4个特征,选择合适的分类算法输出模型,所述模型用于识别新地址所属省份、地市、区县的装置。7.根据权利要求6所述的一种识别省市区的装置,其特征在于,所述数据集为带有省市区标签的地址数据集。8.根据权利要求7所述的一种识别省市区的装置,其特征在于,特征提取函数feature()从每个地址中提取至多4个特征,用jieba.analyse.extract_tags()选择tfidf值最大的3个特征词,取地址的前10个中文字符作为第四个特征。9.根据权利要求8所述的一种识别省市区的装置,其特征在于,选择合适的分类算法学习地址数据集中的第二步特征,输出模型,记为nb_classifier()。10.根据权利要求9所述的一种识别省市区的装置,其特征在于,所述nb_classifier()将来用于识别新地址所属省份、地市、区县的装置,输入新地址,输出所属省市区,即nb_classifier。
技术总结
本发明涉及大数据分析处理领域,具体提供了一种识别省市区的方法,具有如下步骤:S1、制作数据集;S2、选取或自定义特征提取函数;S3、选择合适分类方法训练;S4、获得识别装置。与现有技术相比,本发明利用机器学习中的监督式分类算法以及前期已经标注了省市区的地址数据,搭建简便,能够直接用于分省份、分地市和分区县维度的数据分析。县维度的数据分析。县维度的数据分析。
技术研发人员:张瑞 谢传家
受保护的技术使用者:浪潮卓数大数据产业发展有限公司
技术研发日:2022.02.18
技术公布日:2022/5/25
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1