基于容器的多实例GPU设备实现人工智能计算的方法与流程
基于容器的多实例gpu设备实现人工智能计算的方法
技术领域
1.本发明涉及计算机技术领域,特别涉及一种基于容器的多实例gpu设备实现人工智能计算的方法。
背景技术:
2.人工智能技术正在快速实现从理论概念到实际应用场景落地的转变,然而其高学习、使用门槛,对资源的高要求以及复杂的开发、训练、推理环境及优化、安全、便捷的使用、维护需求,使大量用户望而却步。随着人工智能的发展,特别是神经元网络算法的深入发展与应用,大量的神经网络训练需求由此而生。进行神经网络训练需要利用到大规模的计算能力,特别是gpu计算能力。由于gpu设备较为昂贵,神经网络训练又是阶段性的工作,因此,提供基于大规模gpu,分布式计算的神经网络训练平台,可以作为人工智能计算的基础平台。
3.在现有技术中,我们所知道的有两种通用的技术方案,gpu直通和gpu虚拟化。gpu直通是基于容器技术直通物理显卡来实现人工智能计算,一台服务器设备插入多张物理显卡,然后将每个物理显卡设备分给需要计算的容器使用;gpu虚拟化是将一个物理gpu设备虚拟切割成多个虚拟的gpu设备,然后分配给多个容器进行计算。以上方案存在两个主要问题:(1)一个容器使用一个物理gpu设备进行计算,资源使用率低,资源调度效率低;(2)一块物理gpu设备被等比切割成多块虚拟gpu设备,多个使用者会使用共同的内存,除了无法保证推理的速度和吞吐量之外,也有可能因为一位使用者的程序出错导致其它使用者受到干扰。
技术实现要素:
4.本发明的目的在于提供一种基于容器的多实例gpu设备实现人工智能计算的方法,提高gpu的使用率。
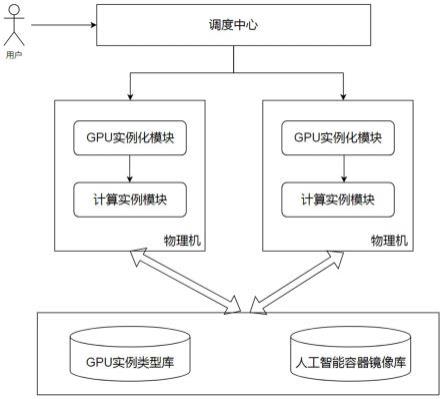
5.为实现以上目的,本发明采用的技术方案为:一种基于容器的多实例gpu设备实现人工智能计算的方法,包括如下步骤:s100、用户提出创建计算容器的需求并发送给调度中心;s200、调度中心根据用户提出的计算容器的需求,分别向gpu实例化模块和计算实例模块发出申请;s300、gpu实例化模块从gpu实例类型库实时获取可用的gpu实例类型或创建用户发出的gpu实例类型;s400、计算实例模块根据用户发出的人工智能计算请求从人工智能容器镜像库拿到相应的镜像后,创建相应的计算实例。
6.与现有技术相比,本发明存在以下技术效果:通过对物理显卡进行“物理”切割,避免了虚拟化切割时互相影响的情况,按此方案切割得到的每个gpu实例都有各自的处理器和内存系统,保证各个使用者工作的时延和吞吐量是可预期的,并且通过灵活的资源分配方法,避免出现资源闲置的情况,提高了gpu的使用率。
附图说明
7.图1是本发明的原理框图;图2是物理显卡切割方案的架构图;图3是本发明实现人工智能计算方法的示意图;图4是本发明物理切割资源组合图。
具体实施方式
8.下面结合图1至图4,对本发明做进一步详细叙述。
9.参阅图1-3,本发明公开了一种基于容器的多实例gpu设备实现人工智能计算的方法,包括如下步骤:s100、用户提出创建计算容器的需求并发送给调度中心;s200、调度中心根据用户提出的计算容器的需求,分别向gpu实例化模块和计算实例模块发出申请;s300、gpu实例化模块从gpu实例类型库实时获取可用的gpu实例类型或创建用户发出的gpu实例类型;s400、计算实例模块根据用户发出的人工智能计算请求从人工智能容器镜像库拿到相应的镜像后,创建相应的计算实例。通过对物理显卡进行“物理”切割,避免了虚拟化切割时互相影响的情况,按此方案切割得到的每个gpu实例都有各自的处理器和内存系统,保证各个使用者工作的时延和吞吐量是可预期的,并且通过灵活的资源分配方法,避免出现资源闲置的情况,提高了gpu的使用率。
10.进一步地,所述的步骤s300中,gpu实例化模块判断gpu实例类型库中是否含有用户发出的gpu实例类型,若有,则直接将该gpu实例类型分配给该用户,若没有,则gpu实例化模块将一个物理显卡切割成指定个数的gpu实例并将其中一个gpu实例分配给该用户,并且在分配后,将其他gpu实例保存至gpu实例类型库中,通过该切割方式,可以灵活的进行资源分配,充分提高gpu的使用率。
11.进一步地,所述的步骤s400中,通过如下步骤创建相应的计算实例:s410、将每个gpu实例分别绑定至多个计算实例;s420、将每个计算实例对应一个计算容器,计算容器中安装有基础操作系统、基础环境和gpu驱动程序;s430、每个计算容器对不同的人工智能算法框架、模板和数据集进行计算。
12.将一个物理显卡切割成多个gpu实例,有多种具体的实施方式,这里结合图4,对切割方案进行详细叙述。
13.实施例一,所述的gpu实例为1个,该gpu实例包括8份显存资源、7份处理器资源。这个实施例中,整个物理显卡作为一个整体,主要提供给需要极多显存资源和处理器资源的计算实例。
14.实施例二,所述的gpu实例为2个,其中第一gpu实例包括4份显存资源、4份处理器资源,第二gpu实例包括4份显存资源、3份处理器资源。
15.实施例三,所述的gpu实例为3个,其中第一gpu实例包括4份显存资源、4份处理器资源,第二gpu实例包括2份显存资源、2份处理器资源,第三gpu实例包括1份显存资源、1份处理器资源;或者,第一gpu实例包括2份显存资源、2份处理器资源,第二gpu实例包括2份显存资源、2份处理器资源,第三gpu实例包括4份显存资源、3份处理器资源;或者,三个gpu实例均包括2份显存资源、2份处理器资源。该实施例中,又有三种切割方案,主要是针对用户需求的不同,更合理的进行资源配置。
16.实施例四,所述的gpu实例为4个,其中第一gpu实例包括4份显存资源、4份处理器资源,其余三个gpu实例均包括1份显存资源、1份处理器资源;或者,三个gpu实例均包括2份显存资源、2份处理器资源,另一个gpu实例包括1份显存资源、1份处理器资源;或者,第一gpu实例和第二gpu实例均包括1份显存资源、1份处理器资源,第三gpu实例包括2份显存资源、2份处理器资源,第三gpu实例包括4份显存资源、3份处理器资源。
17.实施例五,所述的gpu实例为5个,其中四个gpu实例均包括1份显存资源、1份处理器资源,另一个gpu实例包括4份显存资源、3份处理器资源;或者,第一gpu实例和第二gpu实例均包括2份显存资源、2份处理器资源,另外三个gpu实例均包括1份显存资源、1份处理器资源。
18.实施例六,所述的gpu实例为7个,每个gpu实例均包括1份显存资源、1份处理器资源。此实施例与gpu虚拟化切割方案类似,但本质上依然有所区别,即这里的七个gpu实例是互相独立的,互不影响。
19.进一步地,所述的物理显卡为深度学习卡或科学计算显卡。此两类显卡更适合进行切割,因此这里优选地,使用这两种显卡。
技术特征:
1.一种基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:包括如下步骤:s100、用户提出创建计算容器的需求并发送给调度中心;s200、调度中心根据用户提出的计算容器的需求,分别向gpu实例化模块和计算实例模块发出申请;s300、gpu实例化模块从gpu实例类型库实时获取可用的gpu实例类型或创建用户发出的gpu实例类型;s400、计算实例模块根据用户发出的人工智能计算请求从人工智能容器镜像库拿到相应的镜像后,创建相应的计算实例。2.如权利要求1所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的步骤s300中,gpu实例化模块判断gpu实例类型库中是否含有用户发出的gpu实例类型,若有,则直接将该gpu实例类型分配给该用户,若没有,则gpu实例化模块将一个物理显卡切割成指定个数的gpu实例并将其中一个gpu实例分配给该用户。3.如权利要求1或2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的步骤s400中,通过如下步骤创建相应的计算实例:s410、将每个gpu实例分别绑定至多个计算实例;s420、将每个计算实例对应一个计算容器,计算容器中安装有基础操作系统、基础环境和gpu驱动程序;s430、每个计算容器对不同的人工智能算法框架、模板和数据集进行计算。4.如权利要求2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的gpu实例为1个,该gpu实例包括8份显存资源、7份处理器资源。5.如权利要求2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的gpu实例为2个,其中第一gpu实例包括4份显存资源、4份处理器资源,第二gpu实例包括4份显存资源、3份处理器资源。6.如权利要求2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的gpu实例为3个,其中第一gpu实例包括4份显存资源、4份处理器资源,第二gpu实例包括2份显存资源、2份处理器资源,第三gpu实例包括1份显存资源、1份处理器资源;或者,第一gpu实例包括2份显存资源、2份处理器资源,第二gpu实例包括2份显存资源、2份处理器资源,第三gpu实例包括4份显存资源、3份处理器资源;或者,三个gpu实例均包括2份显存资源、2份处理器资源。7.如权利要求2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的gpu实例为4个,其中第一gpu实例包括4份显存资源、4份处理器资源,其余三个gpu实例均包括1份显存资源、1份处理器资源;或者,三个gpu实例均包括2份显存资源、2份处理器资源,另一个gpu实例包括1份显存资源、1份处理器资源;或者,第一gpu实例和第二gpu实例均包括1份显存资源、1份处理器资源,第三gpu实例包括2份显存资源、2份处理器资源,第三gpu实例包括4份显存资源、3份处理器资源。8.如权利要求2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的gpu实例为5个,其中四个gpu实例均包括1份显存资源、1份处理器资源,另一个
gpu实例包括4份显存资源、3份处理器资源;或者,第一gpu实例和第二gpu实例均包括2份显存资源、2份处理器资源,另外三个gpu实例均包括1份显存资源、1份处理器资源。9.如权利要求2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的gpu实例为7个,每个gpu实例均包括1份显存资源、1份处理器资源。10.如权利要求2所述的基于容器的多实例gpu设备实现人工智能计算的方法,其特征在于:所述的物理显卡为深度学习卡或科学计算显卡。
技术总结
本发明特别涉及一种基于容器的多实例GPU设备实现人工智能计算的方法,包括如下步骤:S100、用户提出创建计算容器的需求并发送给调度中心;S200、调度中心根据用户提出的计算容器的需求,分别向GPU实例化模块和计算实例模块发出申请;S300、GPU实例化模块从GPU实例类型库实时获取可用的GPU实例类型或创建用户发出的GPU实例类型;S400、计算实例模块根据用户发出的人工智能计算请求从人工智能容器镜像库拿到相应的镜像后,创建相应的计算实例。按此方案切割得到的每个GPU实例都有各自的处理器和内存系统,保证各个使用者工作的时延和吞吐量是可预期的,并且通过灵活的资源分配方法,避免出现资源闲置的情况,提高了GPU的使用率。率。率。
技术研发人员:田辉 薛帅 郭玉刚 张志翔
受保护的技术使用者:合肥高维数据技术有限公司
技术研发日:2022.03.30
技术公布日:2022/6/17
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1