一种基于Transformer模型的中文文本情感分析方法
一种基于transformer模型的中文文本情感分析方法
技术领域
1.本发明涉及自然语言处理领域,具体涉及一种基于transformer模型的中文文本情感分析方法。
背景技术:
2.情感分析已经成为自然语言处理中最活跃的领域之一,特别是随着互联网和大数据的发展,其潜在的商业价值引起了社会各界的关注。应用情感分析技术不仅可以用来帮助检测社会网络舆情走向,还能够帮助商家及时了解顾客对于产品的评价,更进一步的还可以帮助预测社交用户的心理健康状态以便其能及时得到情感干预。
3.尽管近年来情感分析取得了令人瞩目的成就,但它们大多数都是基于英语的,而同英文相比,中文自然语言处理更具挑战性,一方面是因为汉语的词汇和语义更加丰富一些,另一方面是因为汉语的语篇语义更依赖于语境。
4.最早的中文情感分析方法是基于情感词典的,它是通过文本的词汇来判断文本的情感倾向,但是不具备捕获序列特征的能力。后来出现了循环神经网络 rnn能够解决这一缺陷,但是其又伴随着梯度消失/爆炸问题,随后基于rnn的一系列递归模型被提出以解决这些问题,如长短期记忆网络(lstm)、门控循环神经网络(gru)等。但是当处理较长的文本时仍然会出现梯度消失或爆炸的问题,而随后出现的注意力机制则能够有效解决此问题,它通过对输入序列赋予权重,让模型更加关注关键词,而充分应用注意力机制的transformer及其变体模型在文本情感分析领域取得了比较好的性能。但是,transformer是通过位置编码去实现序列特征的提取,其和rnn等自然序列特征提取方法还是有一定的差距的。
技术实现要素:
5.针对现有技术中存在的问题,本发明提出了一种基于transformer模型 的中文文本情感分析方法,该方法主要是通过将transformer中注意力机制的强 大的全局特征提取能力和rnn强大的序列特征提取能力结合起来,从而来对中 文文本进行情感分析,来实现更好的性能。
6.为实现上述目的,本发明采用以下技术方案予以实现:
7.一种基于transformer模型的中文文本情感分析方法,包括以下步骤:
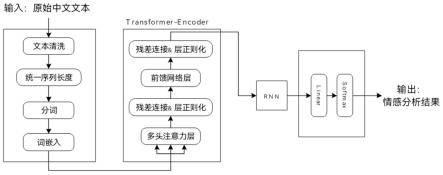
8.步骤1:对原始中文文本数据进行预处理,并统一文本序列的长度;
9.步骤2:将步骤1中得到的中文文本序列进行向量化得到相应的原始向量序列;
10.步骤3:将步骤2中得到的原始向量序列输入transformer的encoder,来提取文本向量特征并输出;
11.步骤4:将transformer的encoder的输出作为rnn的输入来生成状态序列,并把rnn生成的状态序列的最终状态作为rnn的输出,最后使用分类来实现中文文本情感分析。
12.进一步地,步骤1中对文本序列进行处理的过程具体为:先过滤中文文本数据中不
规则的标点符号和字符等,保留文本中的正常标点符号,然后对中文文本进行分词操作,最后以文本序列数据中序列最长的文本序列为标准,对达不到标准长度的文本序列采用在其末尾补零的方式来扩充长度。
13.进一步地,步骤2中对中文文本序列进行向量化的过程为:采用词嵌入的表示方法来将中文文本序列向量化,通过对文本划分得到的每个词进行编码生成词向量来表示对应的主要语义信息,同时对于文本中的保留的标点符号也进行编码,来得到其对应的向量表示,最后该步骤得到的为词向量和标点符号表示的原始向量序列。
14.进一步地,步骤3中原始向量序列输入进transformer的encoder中,通过encoder中的多头自注意力、前馈网络、以及残差连接和层正则化来进行重新处理,来提取出重要的特征向量并组成新的向量序列。
15.进一步地,步骤4中rnn的输出为生成的状态序列的最终状态,随后通过linear层和softmax层来获得相应的输出,从而得到对文本情感分析的结果。
16.本发明的有益效果是:结合了transformer的强大的全局特征提取能力和rnn的强大的序列特征提取能力,同时在进行中文文本数据预处理的时候保留了文本中的正常标点符号,因为在中文中标点符号某种程度上也和文本想要表达的情感有所关联。因此本发明提出的基于transformer来实现中文文本情感分析的方法能够极大程度的提取出对分析中文文本情感有帮助的特征信息,从而有效地分析出中文文本的表达的情感倾向。
附图说明
17.图1为本发明基于transformer实现中文文本情感分析的方法构建分析模型的示意图。
具体实施方式
18.下面将结合附图和实施例,对本发明实例中的技术方案惊醒更为清晰的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
19.本发明提供了一种基于transformer模型的中文文本情感分析方法,具 体包括如下步骤:
20.步骤1:对原始中文文本数据进行预处理,先过滤中文文本数据中不规则的标点符号和字符等,保留文本中的正常标点符号,然后对中文文本进行分词操作,最后以文本序列数据中序列最长的文本序列为标准,对达不到标准长度的文本序列采用在其末尾补零的方式来扩充长度,最终实现统一文本序列的长度。
21.步骤2:采用词嵌入的表示方法来将步骤1中得到的中文文本序列进行向量化,通过对文本划分得到的每个词进行编码生成词向量来表示对应的主要语义信息,同时对于文本中的保留的标点符号也进行编码,来得到其对应的向量表示,最后该步骤得到的为词向量和标点符号表示的原始向量序列。
22.步骤3:将步骤2中得到的原始向量序列输入transformer的encoder,通过encoder中的多头自注意力、前馈网络、以及残差连接和层正则化来进行重新处理,来提取出重要的
特征向量组成新的向量序列并输出。
23.步骤4:将transformer的encoder的输出作为rnn的输入来生成状态序列,并把rnn的状态序列的最终状态作为rnn的输出,随后通过linear层和softmax层来获得相应的输出,从而得到对文本情感分析的结果。
24.本发明提出了一种结合transformer的强大的全局特征提取能力和rnn 的强大的序列特征提取能力,同时在进行中文文本数据预处理的时候保留了文本中的正常标点符号,因为在中文中标点符号某种程度上也和文本想要表达的情感有所关联,这些都使得本发明能够极大程度提取出对分析中文文本情感有帮助的特征信息,从而有效地分析出中文文本的表达的情感倾向。
25.以上对本发明所提出的一种基于transformer模型的中文文本情感分析 方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了 阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时, 对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上 均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
技术特征:
1.一种基于transformer模型的中文文本情感分析方法,其特征在于,所述方法包括:步骤1:对原始中文文本数据进行预处理,并统一文本序列的长度;步骤2:将步骤1中得到的中文文本序列进行向量化得到原始向量序列;步骤3:将步骤2中得到的原始向量序列输入进transformer的encoder,来提取文本向量特征并输出;步骤4:将transformer的encoder的输出作为rnn的输入来生成状态序列,并把rnn生成的状态序列的最终状态作为rnn的输出,最后使用分类来实现中文文本情感分析。2.根据权利要求1所述一种基于transformer模型的中文文本情感分析方法,其特征在于,所述步骤1中对文本序列进行处理的过程具体为:先过滤中文文本数据中不规则的标点符号和字符等,保留文本中的正常标点符号,然后对中文文本进行分词操作,最后以文本序列数据中序列最长的文本序列为标准,对达不到标准长度的文本序列采用在其末尾补零的方式来扩充长度。3.根据权利要求1所述一种基于transformer模型的中文文本情感分析方法,其特征在于,所述步骤2中对中文文本序列进行向量化的过程为:采用词嵌入的表示方法来将中文文本序列向量化,通过对文本划分得到的每个词进行编码生成词向量来表示对应的主要语义信息,同时对于文本中的保留的标点符号也进行编码,来得到其对应的向量表示,最后该步骤得到的为词向量和标点符号表示的原始向量序列。4.根据权利要求2所述一种基于transformer模型的中文文本情感分析方法,其特征在于,通过transformer和rnn来对步骤2中得到的原始向量序列进行重新处理,并进行全局特征信息和序列特征信息的提取,最后通过linear层和softmax层来最终得到文本情感分析的结果。
技术总结
本发明公开了一种基于改进Transformer模型的中文文本情感分析方法,涉及自然语言处理领域,该方法在中文文本数据预处理时考虑到了标点符号和中文文本情感的关联,保留了中文文本中正常的标点符号,然后通过把RNN和Transformer进行结合来实现把强大的全局特征提取能力和序列特征提取能力结合起来,进而实现充分提取特征信息,从而提高对中文文本进行情感分析的效果。情感分析的效果。情感分析的效果。
技术研发人员:徐军 王高飞
受保护的技术使用者:哈尔滨理工大学
技术研发日:2022.04.26
技术公布日:2022/8/22
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1