一种基于语义容错的大规模勘探开发BERT分类方法与流程
本发明涉及勘探开发,尤其涉及一种基于语义容错的大规模勘探开发bert分类方法。
背景技术:
1、面向勘探开发综合研究过程产生的成果报告,为了提高研究成果查询准确率、实现精准推送,对非结构化成果报告需要采取机器学习的方法,对文本进行准确的业务分类。
2、传统的nlp业务分类方法一般通过采集大量样本进行人工标注的方法获得标注语料,然后通过规则方法、统计学习方法如crf或者深度学习方法lstm建立模型。
3、行业应用难以获得大规模语料,虽然公共平台容易获得大量数据,如cnki或者百度文库,但是对于某一个特定的专业应用能获得的数据是非常有限的,如石油上游业务勘探开发综合应用文献。以”勘探开发综合应用”为关键词在cnki查查询文献的总数是73篇,包括杂志文献、学位论文;胜利油田物探院内研究用部文献将图片、表格和各种格式的文本文件算在一起只有157篇。行业应用难以获得大规模语料,因此难以开展有效的大规模分类技术研究。
4、传统分类方法采用0阶语法,0阶语法是上下文无关语法,将一篇文献无论多长都按句子进行打散,去掉句子之间的关联关系,将句子都标为整篇文献的类别,然后进行分类。最重要的知识是句子之间的关系,因此0阶语法抽掉了整篇文献最精华的知识框架,抛弃了文献中最重要的高层次知识,所以传统分类方法所采用的处理手段不能有效地表达整篇文献的核心内容。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供克服上述问题或者至少部分地解决上述问题的一种基于语义容错的大规模勘探开发bert分类方法。
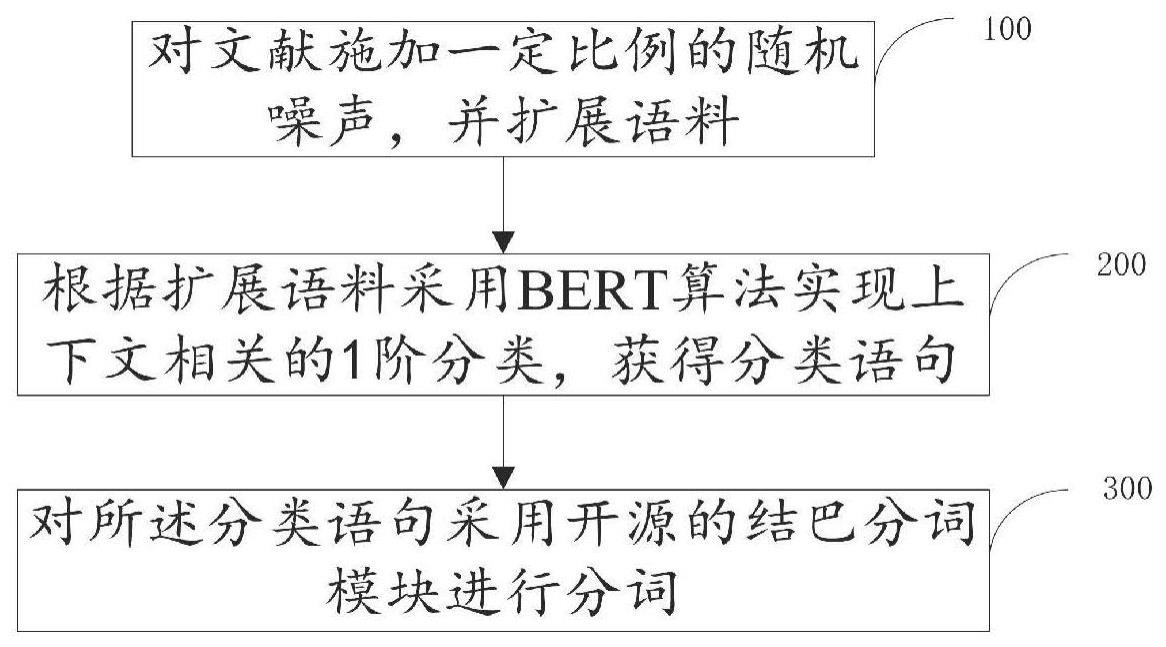
2、本发明的提供了一种基于语义容错的大规模勘探开发bert分类方法包括:
3、对文献施加一定比例的随机噪声,并扩展语料;
4、根据扩展语料采用bert算法实现上下文相关的1阶分类,获得分类语句;
5、对所述分类语句采用开源的结巴分词模块进行分词。
6、可选的,所述对文献施加一定比例的随机噪声,并扩展语料包括:
7、对文献施加随机噪声,使文献出现一定比例的字、词错误;
8、反用搜索词纠错技术,构造一篇新文献,重复操作构建大量的标注语料。
9、可选的,所述根据扩展语料采用bert算法实现上下文相关的1阶分类,获得分类语句具体包括:
10、将文献按顺序输入进行分类,利用bert算法对上下文的及功能,实现对文献进行1阶语法分类;
11、bert的段落重排序任务是将一篇文章的各段打乱,然后通过重新排序把原文还原出来,用于实现算法对全文的充分准确了解。
12、可选的,所述对所述分类语句采用开源的结巴分词模块进行分词具体包括:
13、对句子采用开源的结巴分词模块进行分词,得到以词为单位的句子;
14、在分词过程中,对于专业词汇要增加用户字典,用于提升分词的准确率。
15、本发明提供的一种基于语义容错的大规模勘探开发bert分类方法包括:对文献施加一定比例的随机噪声,并扩展语料;根据扩展语料采用bert算法实现上下文相关的1阶分类,获得分类语句;对所述分类语句采用开源的结巴分词模块进行分词。通过输入文本在保持文本篇章结构不变的前提下对句子进行加错处理,扩大语料的数量,同时采用bert算法以句子对为输入,实现了1型语法对前后文的记忆,间接实现了对篇章结构知识的理解。
16、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
技术特征:
1.一种基于语义容错的大规模勘探开发bert分类方法,其特征在于,所述分类方法包括:
2.根据权利要求1所述的一种基于语义容错的大规模勘探开发bert分类方法,其特征在于,所述对文献施加一定比例的随机噪声,并扩展语料包括:
3.根据权利要求1所述的一种基于语义容错的大规模勘探开发bert分类方法,其特征在于,所述根据扩展语料采用bert算法实现上下文相关的1阶分类,获得分类语句具体包括:
4.根据权利要求1所述的一种基于语义容错的大规模勘探开发bert分类方法,其特征在于,所述对所述分类语句采用开源的结巴分词模块进行分词具体包括:
技术总结
本发明提供的一种基于语义容错的大规模勘探开发BERT分类方法包括:对文献施加一定比例的随机噪声,并扩展语料;根据扩展语料采用BERT算法实现上下文相关的1阶分类,获得分类语句;对所述分类语句采用开源的结巴分词模块进行分词。通过输入文本在保持文本篇章结构不变的前提下对句子进行加错处理,扩大语料的数量,同时采用BERT算法以句子对为输入,实现了1型语法对前后文的记忆,间接实现了对篇章结构知识的理解。
技术研发人员:颜世磊,孙晓杰,郑云拓,张敏,李晶晶,李妍琛,宋建,史纪强,任恩茂,王文蔚
受保护的技术使用者:中国石油化工股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!