基于联邦学习的多粒度动态知识图谱嵌入模型构造方法
1.本发明涉及人工智能和联邦学习技术领域,特别是一种基于联邦学习的多粒度动态知识图谱嵌入模型构造方法。
背景技术:
2.知识图谱是一种图谱组织形式,通常使用有效的结构化信息来描述实体之间的语义关联性,诸如freebase、yago、nell等大型知识图谱已经在自然语言处理、智能问答、推荐系统等人工智能应用中展现出巨大的价值。知识图谱的通用表示方式是大量事实三元组的集合,每个三元组的形式为(头实体,关系,尾实体),也可以表示为(h,r,t),用来表明两个实体之间的关系。而动态知识图谱主要融入了时间的信息,将三元组(h,r,t)扩展到四元组(h,r,t,τ),其中τ是三元组(h,r,t)的时间信息,可以包含不同时间粒度。知识图谱嵌入方法则是将知识图谱中的实体和关系表示成同一语义空间中的向量,这些实体和关系的嵌入可以进一步应用于各种下游任务中,如知识图谱补全、关系提取、实体分类和实体解析。由于时序信息非常重要,且不同粒度的时间信息包含了不同的含义,例如有些事实只在年的粒度内有效,有些事实只在月的粒度下有效(如某家店铺的月营业额),有些事实只在日的粒度下有效(如某天发生的热门事件)。而动态知识图谱嵌入技术目前只简单考虑时序信息对于事实三元组的影响,并没有关注不同时间粒度的信息与事实三元组的关联性,这使得动态知识图谱嵌入模型在对事实三元组进行表征的时候准确性较低,冗余信息高。
3.现实中,由于数据中包含大量个人隐私、商业机密等,重视数据隐私和安全已经成为近年来数据领域的最重要趋势。2016年欧盟通过的《通用数据保护条例》(gdpr),2018年紧随其后的《美国加州消费者隐私法》(ccpa)和2021 年中国实施的《中华人民共和国信息保护法》都表明了国内外对数据隐私和安全问题愈发关注,相关法律法规对数据隐私保护的监管也变得越来越严苛。毫无疑问的是,在这种情况下,数据孤岛会逐渐显现,导致大数据与人工智能的结合不完美,数据价值无法被充分挖掘和释放。而联邦学习正是在隐私保护和数据挖掘的背景下被提出,旨在保证各参与者原始数据不出库的前提下,通过服务器交互不可逆的中间信息完成联合建模。目前的联邦学习基础框架与动态知识图谱嵌入模型结合时,可以将模型参数上传至服务器进行聚合,但没有考虑部分粒度参数的选择性上传,使得训练过程中客户端和服务器的通信效率低。
4.(1)动态知识图谱嵌入
5.参考文献1“diachronic embedding for temporal knowledge graph completion
”ꢀ
(r.goel,s.m.kazemi,m.brubaker,p.poupart,proceedings of the aaaiconference on artificial intelligence,pp.3988-3995,2020)和参考文献2“hyte: hyperplane-based temporally aware knowledge graph embedding”(s.s.dasgupta, s.n.ray,p.talukdar,proceedings of the conference on empirical methods innatural language processing,pp.2001-2011,2018)在知识图谱数据中加入时间维度分别提出de模型和hyte模型。de模型增加了一个历时的实体嵌入函数来建立新的时间上的知
识图谱补全模型,该函数提供实体在任何时间点的特征。所提出的嵌入函数是与模型无关的,并且可以与任何静态模型相结合。hyte通过一种时间上感知的知识图谱嵌入方法,将每个时间戳与相应的超平面相关联,明确地将时间结合在实体关系空间中。目前的动态知识图谱嵌入方法虽然考虑了时间的信息,但是并没有结合不同的时间粒度进行分析,使得动态知识图谱嵌入模型中的三元组表征可靠性低,难以在现实的下游应用中使用。
6.(2)联邦学习
7.参考文献3“fede:embedding knowledge graphs in federated setting”(m. chen,w.zhang,z.yuan,y.jia,h.chen,proceedings of the 10th international jointconference on knowledge graphs,pp.80-88,2021)和参考文献4“differentiallyprivate federated knowledge graphs embedding”(h.peng,h.li,y.song,v.zheng,j. li,proceedings of the 30th acm international conference on information& knowledge management,pp.1416-1425,2021)分别通过联邦学习充分利用来自不同知识领域的数据和信息。这些方法将联邦学习与知识图谱嵌入模型相结合,但客户端的模型参数都是直接上传至服务器直接聚合,没有考虑选择性的参数发送规则,增加了联邦学习模型的通信负担。
技术实现要素:
8.本发明的目的是提供一种基于联邦学习的多粒度动态知识图谱嵌入模型构造方法。
9.实现本发明目的的技术方案如下:
10.基于联邦学习的多粒度动态知识图谱嵌入模型构造方法,包括:
11.步骤1,客户端对多粒度动态知识图谱嵌入模型进行本地训练;
12.所述多粒度动态知识图谱嵌入模型,具体为:
13.1.1将动态知识图谱数据的头实体向量、尾实体向量、关系向量和时间向量,分别按照时间粒度进行切割;所述时间粒度的数量大于等于2;
14.1.2将切割后的时间向量,分别嵌入到对应时间粒度的切割后的头实体向量,得到各个时间粒度的头实体嵌入;将切割后的时间向量,分别嵌入到对应时间粒度的切割后的尾实体向量,得到各个时间粒度的尾实体嵌入;将切割后的时间向量,分别嵌入到对应时间粒度的切割后的关系向量,得到各个时间粒度的关系嵌入;
15.1.3将相同时间粒度的头实体嵌入、尾实体嵌入和关系嵌入进行链接,得到嵌入绑定三元组;
16.1.4将嵌入绑定三元组按照时间粒度依次排列得到矩阵;通过卷积核集合将所述矩阵进行卷积,得到多个特征图;将多个特征图连接得到单一特征向量,再通过点积将单一特征向量与权重向量相乘,得到三元组得分;
17.本地多轮训练所述多粒度动态知识图谱嵌入模型:采取正例和负例,通过最小化损失函数来进行训练,并对权重向量进行正则化;所述正例为:属于该客户端的动态知识图谱数据集的数据;所述负例为:将所述正例中,头实体向量或尾实体向量替换为随机实体向量;
18.步骤2,多个完成本地多轮训练多粒度动态知识图谱嵌入模型的客户端,将模型的
卷积核集合和权重向量上传到服务器,服务器按照平均聚合规则更新卷积核集合和权重向量,之后下传到每个客户端;
19.重复执行步骤1、步骤2多轮后,得到全局多粒度动态知识图谱嵌入模型。
20.上述技术方案中,所述重复执行步骤1、步骤2多轮后,得到全局多粒度动态知识图谱嵌入模型,可以替换为:重复执行步骤1、步骤2,直至满足全局模型收敛条件后,得到全局多粒度动态知识图谱嵌入模型。
21.上述技术方案中,所述步骤2中,服务器按照平均聚合规则更新卷积核集合和权重向量,可以替换为:服务器按照平均聚合规则更新卷积核集合,按照多粒度聚合规则更新权重向量;所述服务器按照多粒度聚合规则更新权重向量,具体为:
22.2.1将客户端上传到服务器的权重向量,按照时间粒度进行切割,得到该客户端具有不同时间粒度的权重分量;
23.2.2服务器将所有具有相同时间粒度的权重分量求和,再根据上传该时间粒度的客户端的总量,求得该时间粒度的权重分量平均值;
24.2.3服务器将不同时间粒度的权重分量平均值,更新客户端的不同时间粒度的权重分量,再按照时间粒度进行组合,得到该客户端的权重向量。
25.本发明提供的联邦学习的多粒度动态知识图谱嵌入模型构造方法,关注不同时间粒度的信息与事实三元组的关联性,提高了动态知识图谱嵌入模型中事实三元组表征的准确性。联邦学习使用多粒度聚合规则时,提高了动态知识图谱嵌入模型的通信效率,降低了冗余信息。
附图说明
26.图1是本发明的框架结构图。
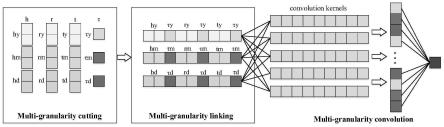
27.图2是多粒度动态知识图谱嵌入模型图。
28.图3是多粒度聚合规则图。
29.图4是在三个真实数据集上对比了应用多粒度聚合规则和基于fedavg的聚合规则的联邦多粒度动态知识图谱嵌入模型构造方法的性能结果。
具体实施方式
30.以下结合附图对本发明进一步说明。
31.一、联邦多粒度动态知识图谱嵌入框架
32.本发明的整体框架结构如图1所示,即联邦多粒度动态知识图谱嵌入框架 (fedmdkge)。它的每轮迭代过程遵循联邦学习的三个阶段:(i)服务器初始化全局嵌入模型,并将其发送给参与训练的客户端。(ii)客户端在本地使用自己的动态知识图谱数据集训练多粒度动态知识图谱嵌入模型(mdkge),然后将训练好的模型参数上传到服务器。(iii)服务器根据聚合规则对接收到的参数进行更新。
33.二、多粒度动态知识图谱嵌入模型
34.如图2所示,该模型主要分为以下步骤:多粒度切割,多粒度链接,多粒度卷积。在动态知识图谱中,每一个三元组(h,r,t)都有对应的一个时间信息,它表明这个事实在特定的时间是有效的。这个时间信息可以是不同的粒度,例如:年、月、日,或者年、月、日、小时,
或者月、日,等等。因此,多粒度动态知识图谱嵌入的主要目标是为了更加精确地表征不同时间粒度下的实体和关系。多粒度切割是将嵌入分割为元素个数相等的多个部分来表示不同的信息。将实体向量h和t,关系向量r,以及时间向量τ按照时间粒度切割为三个部分。多粒度链接将切割后的向量与时间的不同粒度进行链接,从而实现同一粒度下的信息交互。具体地,时间向量的每一个粒度与实体向量和关系向量的每一个粒度链接。多粒度卷积将卷积神经网络的知识图谱嵌入方法扩展为多粒度卷积方法,以此来捕捉不同时间粒度的信息。
35.三、多粒度聚合规则
36.如图3所示,多粒度聚合规则用来适应不同粒度的多方信息聚合。模型 mdkge有n个卷积核,每个卷积核有1
×
d1个参数和一个bias参数,一共有 (1
×
d1+1)
×
n个参数。这些卷积核重复地对向量矩阵的每一行(每一个粒度)进行卷积操作,可以看作是多种粒度的融合参数,因此将客户端模型的卷积核参数p
ω
都上传至服务器聚合。
[0037][0038]
其中,k是参与训练的客户端,表示服务器聚合后的卷积核参数,表示某个客户端的卷积核参数。
[0039]
卷积后产生的特征图连接到一个单独的特征向量中,并结合权重向量w通过点积操作计算知识四元组的最终得分。由于每个特征图是卷积核对不同粒度的向量进行卷积得到的,那么权重向量w可以看作包含了时间粒度的权重参数 pw。以时间粒度为年、月、日为例,权重参数pw可以分解为三部分的粒度参数,即p
wy
,p
wm
,p
wd
,分别表示年、月、日三种粒度下的pw参数。客户端可以根据自身的情况上传参数pw的一部分,服务器仍然将客户端上传的pw参数按照粒度进行聚合。例如,关注年粒度的客户端只上传p
wy
参数,关注月粒度的客户端需要将p
wy
和p
wm
一起上传,因为月粒度包含在年粒度之下,而关注到具体日期的客户端则将p
wy
,p
wm
和p
wd
(即pw本身)一起上传。这在一定程度上可以减轻联邦学习中的通讯负担,因为在不影响模型精度的情况下,越少的参数上传意味着越少的通讯量。
[0040][0041][0042][0043]
其中,ky是上传年粒度参数的客户端,km是上传月粒度参数的客户端, kd是上传日粒度参数的客户端,表示服务器聚合后的相应粒度的权重参数(*代表时间粒度y、m或d)。
[0044]
实施例一:
[0045]
一种基于联邦学习的多粒度动态知识图谱嵌入模型构造方法,其步骤如下:
[0046]
步骤1:输入k个客户端在本地不出库的动态知识图谱数据集dkg1,dkg2, dkg3,...,dkgk,每个动态知识图谱表示为dkg={(h,r,t,τ)|h,t∈e,r∈r,τ∈t},其中,e和r分别表示实体集合和关系集合,t表示时间集合。h、t和r分别表示头实体,尾实体和关
系,τ是关于知识三元组成立的时序信息。例如,在事件预警动态知识图谱中,四元组(四川雅安,发生,6.1级地震,2022-06-01)中,“四川雅安”是头实体h,“发生”是关系r,“6.1级地震”是尾实体t,“2022-06-01”是四川雅安发生6.1级地震这个三元组成立的时序信息τ。在地铁流量动态知识图谱中,四元组(茶店子站点,流量1138,流入,2022-02-05)中,“茶店子站点”是头实体 h,“流量1138”是关系r,“流入”是尾实体t,“2022-02-05”是茶店子站点流入流量1138这个三元组成立的时序信息τ。
[0047]
步骤2:每个客户端在本地使用自己的dkg数据集训练多粒度动态知识图谱嵌入模型(mdkge),将数据集中的每个四元组(h,r,t,τ)的实体向量h和t,关系向量r,以及时间向量τ按照时间粒度年、月和日切割为元素个数相等的多个部分来表示不同的信息。实体向量h划分为三个部分,即h=[hy,hm,hd]。hy 用来表示头实体在年粒度下的信息,hm和hd分别用来表示头实体在月粒度和日粒度下的时间信息。这样每一个头实体向量可以包含多种时间粒度信息。而实体向量t,关系向量r和时间向量τ也根据这种切割方法进行划分,即:
[0048]
h=[hy,hm,hd]
[0049]
r=[ry,rm,rd]
[0050]
t=[ty,tm,td]
[0051]
τ=[τy,τm,τd]
[0052]
其中,实体向量h和t和关系向量r的维度为d1,每一个分量的维度为d1/3。时间向量τ的维度为d2,每一个分量的维度为d2/3。
[0053]
步骤3:将切割后的向量与时间的不同粒度进行链接,从而实现同一粒度下的信息交互。具体地,时间向量的每一个粒度与实体向量和关系向量的每一个粒度链接,形式地表示为:
[0054]
hτy=[hy,τy],hτm=[hm,τm],hτd=[hd,τd]
[0055]
rτy=[ry,τy],rτm=[rm,τm],rτd=[rd,τd]
[0056]
tτy=[ty,τy],tτm=[tm,τm],tτd=[td,τd]
[0057]
以上的每一个向量,例如hτy,rτy,tτy,维度都是d1/3+d2/3。
[0058]
步骤4:然后根据三元组的组成形式(h,r,t),再将包含了相同时间粒度的头实体嵌入,关系嵌入和尾实体嵌入进行链接,形成同一粒度下的嵌入绑定三元组,如下:
[0059]
hrty=[hτy,rτy,tτy]
[0060]
hrtm=[hτm,rτm,tτm]
[0061]
hrtd=[hτd,rτd,tτd]
[0062]
其中,链接之后的嵌入绑定三元组hrty,hrtm,hrtd的维度都为d1+d2。
[0063]
步骤5:之后转变为一个三行的矩阵[hrty,hrtm,hrtd]
t
,为了捕捉dkg中不同时间粒度的信息,通过多个卷积核对维度为3
×
(d1+d2)的矩阵[hrty,hrtm,hrtd]
t
进行卷积,生成不同的特征图。这些特征映射被连接成一个表示输入的单一特征向量,再通过点积将特征向量与权重向量相乘,最后返回三元组得分。相应地, mdkge的得分函数定义为:
[0064]fmdkge
(h,r,t,τ)=concat(g([hrty,hrtm,hrtd]
t
*ω))*w
[0065]
其中,concat(
·
)表示连接操作,g(
·
)是激活函数,[
·
]
t
表示矩阵的转置,ω是卷积核集合的参数,w表示权重参数。
[0066]
步骤6:在客户端进行mdkge模型训练时采取正例和负例一起训练的方法,训练达
到设定的轮次nc之后,客户端终止本次训练。其中,负例是将四元组中的头实体或尾实体替换为随机实体,通过最小化损失函数l来训练 mdkge,并对模型的权值向量进行正则化,定义如下:
[0067][0068]
其中,q表示知识库中的四元组,q’是负采样的四元组,权重向量w 上的正则化项。
[0069]
步骤7:根据传统的联邦学习平均聚合规则,参与训练的客户端在本地终止本次训练之后,将mdkge模型的参数ω和w发送至服务器,服务器再按照平均聚合规则进行更新,更新后再将参数发送回各个客户端,重复执行步骤2、3、 4、5和6,直至满足全局模型收敛条件后或迭代至设定的轮次ng(即最大迭代次数)之后,训练结束,最终输出训练好的全局多粒度动态嵌入模型mdkge。
[0070]
上述满足全局模型收敛条件,即客户端的损失函数l不断下降,直到每个客户端或者一定比例的客户端,它们自己本地训练过程中临近两轮的损失函数l 之差小于所设定的阈值为止。
[0071]
实施例二:
[0072]
为了进一步使得mdkge模型性能更优,步骤7中,应用多粒度聚合规则。参与训练的客户端将mdkge模型的参数ω和w的部分粒度参数发送至服务器,服务器再按照多粒度聚合规则进行更新,更新后再将参数发送回各个客户端,重复执行步骤2、3、4、5和6,直至满足全局模型收敛条件后或迭代至设定的轮次ng后,训练结束,最终输出训练好的全局多粒度动态嵌入模型mdkge。
[0073]
仿真实验
[0074]
为了验证本发明方法的有效性,使用三个真实世界的数据集(icews14, icews05-15和gdelt15-16)进行了实验,并与现有十二个基准方法做了比较,即transe,distmult,simple,convkb,cont,ttranse,hyte,ta-distmult, de-transe,de-distmult,de-simple和de-convkb。评估指标包括正确实体的平均倒数排名(mrr)和其排在前n位的比例(hits@n)。
[0075]
实验一:
[0076]
为了验证所提出的动态知识图谱嵌入模型mdkge的有效性,与十二个基准方法进行对比和分析。表1展示了不同方法在三个真实世界数据集上的实验结果。
[0077]
表1在动态知识图谱上不同基准方法的定量对比结果
[0078][0079]
从表1可以很明显地看出,对于静态知识图谱嵌入方法,在大多数情况下,将其扩展为动态知识图谱嵌入方法后的性能表现更佳。例如,ta-distmult和 de-distmult比distmult拥有更高的mrr和hits@n,de-simple和de-convkb 比simple和convkb也表现的更佳。transe和基于transe的基线(ttranse, hyte和de-transe)相对于其他方法,整体上对知识图谱的嵌入能力还不足,虽然动态知识图谱嵌入方法de-transe有一定的性能提升。动态知识图谱嵌入方法cont在数据集icews14和icews05-15上的表现不如其在数据集gdelt 的表现。mdkge的性能在三个数据集上都高于这些基线(包括动态和静态知识图谱嵌入方法),这表明该模型能够提取到多粒度的时间表征信息,进一步增强模型的知识图谱嵌入能力。
[0080]
实验二:
[0081]
为了验证联邦动态知识图谱嵌入框架的有效性,将icews14划分为k个独立的数据子集(fed-icews14),k个数据子集存储在k个客户端本地,不进行数据交互。icews05-15和gdelt15-16数据集也按照icews14数据集一样分别划分为多个数据子集(fed-icews05-15和fed-gdelt15-16)。基于这三个联邦动态知识图谱数据集进行实验验证在联邦学习框架下该模型协同训练的有效性。
[0082]
表2在联邦动态知识图谱上不同基准方法的定量对比结果
[0083][0084]
如表2所示,将动态知识图谱嵌入方法和mdkge模型分别在多个联邦数据子集上进行实验,然后得到每个数据子集的实验结果,即mrr和hits@n,最后将这些数据子集的实验结果进行求和平均得到最终的结果。同时, fedmdkge在三个联邦数据集下以联合训练的形式进行了实验,得到了对应的实验结果,验证了联邦嵌入框架可以交互不同客户端的信息,并提升模型的性能。
[0085]
实验三:
[0086]
对比了应用多粒度聚合规则和基于fedavg的聚合规则的联邦多粒度动态知识图谱嵌入模型构造方法,即fedmdkge和fedmdkge(fedavg)。实验结果如图4所示,结果表明,两种方法在指标mrr和hits@n上的性能是相似的。所以,在使用多粒度聚合规则的时候,联邦框架中的客户端可以根据自己的情况选择不同粒度的参数进行聚合,在不影响模型性能的同时,不仅可以更加符合实际情况,还可以在一定程度上减少需要上传的参数数量。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1