一种数据处理方法、系统、设备及存储介质与流程
本发明涉及数据处理,具体涉及一种数据处理方法、系统、设备及存储介质。
背景技术:
1、目前许多的数据传输sdk(software development kit,软件开发工具包)是对第三方客户端做一个简单的包装,但许多数据源的弊端没有得到真正的解决。以kafka为例,kafka提供原生单线程的消费形式,但是一旦消息发送速度过快,就会出现消息堆积的问题,从而导致延迟。除此之外,由于kafka消息中保留机制的作用,有些消息可能在被消费之前就被清理了,从而造成了消息的丢失。所以需要通过多线程的形式提高消费能力。现有技术中,基于多线程的消费形式有许多种模式,有多线程模式和生产者消费者模式。
2、多线程模式中,数据的拉取与处理都在一个线程中。对于多线程模式而言,其存在的问题如下:(1)线程的数量受限于分区数,导致无法横向扩展。(2)需要更多的tcp连接,从而占用更多的系统资源。(3)一旦处理逻辑耗时过长,导致数据出现重平衡的现象。
3、生产者消费者模式中,通过将数据的拉取与处理解耦,使用单线程拉取数据后,用多线程处理拉取的数据。但对于生产者消费者模式,存在如下问题:(1)无法支持小批量提交消费者队列中的各offset,如果支持小批量提交,又无法保证消息offset提交的一致性。(2)无法平衡数据拉取能力与数据处理能力。(3)请求频繁,对客户端、数据源都是造成较大的压力,从而导致系统的吞吐量下降。因此,需要提供一种数据处理方法、系统、设备及存储介质。
技术实现思路
1、鉴于以上现有技术的缺点,本发明的目的在于提供一种数据处理方法、系统、设备及存储介质,以改善现有技术中,数据传输过程中,数据拉取与数据处理能力不均衡的问题。
2、为实现上述目的及其它相关目的,本发明提供一种数据处理方法,包括以下过程:
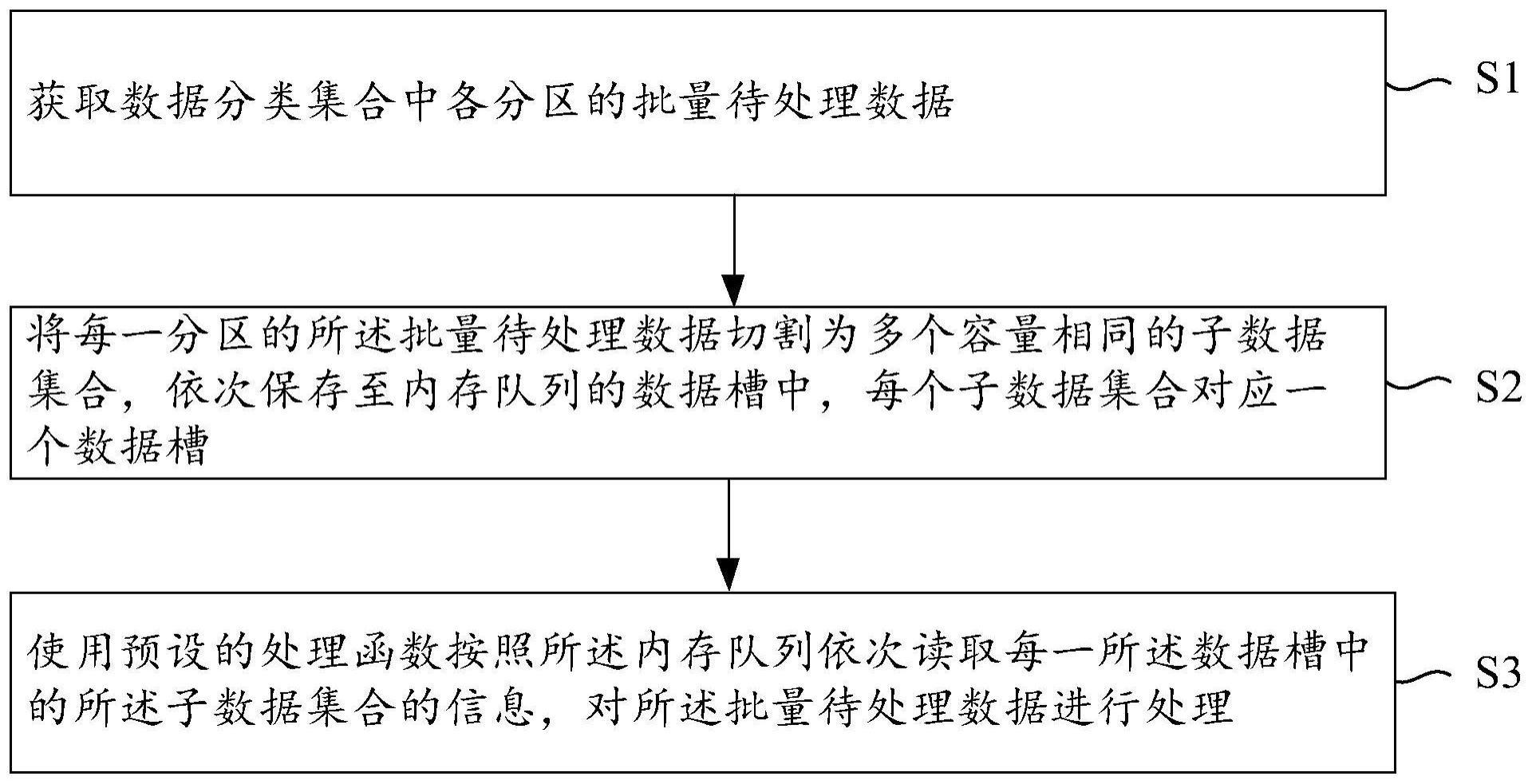
3、获取数据分类集合中各分区的批量待处理数据;
4、将每一分区的所述批量待处理数据切割为多个容量相同的子数据集合,依次保存至内存队列的数据槽中,每个子数据集合对应一个数据槽;
5、使用预设的处理函数按照所述内存队列依次读取每一所述数据槽中的所述子数据集合的信息,对所述批量待处理数据进行处理。
6、在本发明一实施例中,所述获取数据分类集合中各分区的批量待处理数据,包括:
7、若内存队列的数据槽的数量小于预设消费者的数量,拉取数据分类集合中预存的消费者记录列表;
8、读取所述消费者记录列表中的各分区列表的数据信息,并选择其中一个分区列表,获取当前分区的批量待处理数据。
9、在本发明一实施例中,所述将每一分区的所述批量待处理数据切割为多个容量相同的子数据集合,依次保存至内存队列的数据槽中,包括:
10、将每一分区的所述批量待处理数据切割为多个容量相同的子数据集合,并根据数据处理的任务,建立与子数据集合对应的检查点;
11、将当前子数据集合和对应的检查点封装成一个事件,保存至内存队列的一个数据槽中。
12、在本发明一实施例中,所述拉取数据分类集合中预存的消费者记录列表之前,还包括:设置数据分类集合中数据拉取的频率、数据处理的频率、生产者数量和消费者数量。
13、在本发明一实施例中,所述读取所述消费者记录列表中的各分区列表的数据信息之后,还包括:若各分区列表的数据信息读取完毕,获取预设的检查点的数据。
14、在本发明一实施例中,所述获取预设的检查点的数据之前,还包括:
15、获取检查点分布图;
16、根据所述检查点分布图中各分区的键值,获取各分区对应的检查点列表,所述检查点列表包含当前分区已拉取数据的检查点;
17、计算各分区的检查点列表,获取各分区对应的标志点,并提交各标志点对应的偏移量。
18、在本发明一实施例中,所述使用预设的处理函数按照所述内存队列依次读取每一所述数据槽中的所述子数据集合的信息之后,还包括:获取所述数据传输任务中预设的检查点的数据。
19、在本发明一实施例中,还提供一种数据处理系统,所述系统包括:
20、单线程模块,用于在一个线程内部完成数据的拉取与处理;
21、多线程模块,用于在多个线程内完成数据的拉取与处理;
22、生产者消费者模块,用于获取数据分类集合中各分区的批量待处理数据;将每一分区的所述批量待处理数据切割为多个容量相同的子数据集合,依次保存至内存队列的数据槽中,每个子数据集合对应一个数据槽;使用预设的处理函数按照所述内存队列依次读取每一所述数据槽中的所述子数据集合的信息,对所述批量待处理数据进行处理。
23、在本发明一实施例中,还提供一种设备,包括处理器,所述处理器与存储器耦合,所述存储器存储有程序指令,当所述存储器存储的程序指令被所述处理器执行时实现上述任一项所述的方法。
24、在本发明一实施例中,还提供一种计算机可读存储介质,包括程序,当所述程序在计算机上运行时,执行上述中任一项所述的方法。
25、综上所述,本发明中,通过将每个分区的待处理数据切割为多个容量大小相同的子数据集合,将每个子数据集合保存至内存队列的一个数据槽中。在消费者进行消费时,使用用户预先注册的处理函数依次读取数据槽中的子数据集合,对批量待处理数据进行处理。实现了数据的拉取与数据的处理过程的解耦,不会等到拉取到的数据全部处理完成,才提交offset,而是通过将数据进行切割的形式,处理完一部分即提交对应的offset,从而平衡了系统资源,舒缓了数据源负载。
技术特征:
1.一种数据处理方法,其特征在于,包括以下过程:
2.根据权利要求1所述的数据处理方法,其特征在于,所述将每一分区的所述批量待处理数据切割为多个容量相同的子数据集合,依次保存至内存队列的数据槽中,包括:
3.根据权利要求1所述的数据处理方法,其特征在于,所述获取数据分类集合中各分区的批量待处理数据,包括:
4.根据权利要求3所述的数据处理方法,其特征在于,所述拉取数据分类集合中预存的消费者记录列表之前,还包括:设置数据分类集合中数据拉取的频率、数据处理的频率、生产者数量和消费者数量。
5.根据权利要求3所述的数据处理方法,其特征在于,所述读取所述消费者记录列表中的各分区列表的数据信息之后,还包括:若各分区列表的数据信息读取完毕,获取预设的检查点的数据。
6.根据权利要求5所述的数据处理方法,其特征在于,所述获取预设的检查点的数据之前,还包括:
7.根据权利要求1所述的数据处理方法,其特征在于,所述使用预设的处理函数按照所述内存队列依次读取每一所述数据槽中的所述子数据集合的信息之后,还包括:获取所述数据传输任务中预设的检查点的数据。
8.一种数据处理系统,其特征在于,所述系统包括:
9.一种数据处理设备,其特征在于:包括处理器,所述处理器与存储器耦合,所述存储器存储有程序指令,当所述存储器存储的程序指令被所述处理器执行时实现权利要求1至7中任一项所述的方法。
10.一种计算机可读存储介质,其特征在于:包括程序,当所述程序在计算机上运行时,执行如权利要求1至7中任一项所述的方法。
技术总结
本发明提供一种数据处理方法、系统、设备及存储介质,属于数据处理技术领域。方法包括:获取数据分类集合中各分区的批量待处理数据;将每一分区的所述批量待处理数据切割为多个容量相同的子数据集合,依次保存至内存队列的数据槽中,每个子数据集合对应一个数据槽;使用预设的处理函数按照所述内存队列依次读取每一所述数据槽中的所述子数据集合的信息,对所述批量待处理数据进行处理。改善了数据传输过程中,数据拉取与数据处理能力不均衡的问题。
技术研发人员:耿得恒,倪宝亮,王振雷
受保护的技术使用者:浙江极氪智能科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!