一种面向时间知识图谱中新实体的知识推理方法
1.本发明涉及时间知识图谱以及自然语言处理领域。
背景技术:
2.近年来,随着静态知识图谱的相关技术逐渐成熟,面向时间知识图谱的研究日益增多,而时间知识图谱的表示学习和推理技术是补全和应用图谱的重中之重。为了获取时间知识图谱中信息的向量表示,现有模型大多仅在静态知识图谱表示学习方法的基础上,将四元组按时间拆分为三元组进行学习,信息来源相对单一,而且忽略了图谱中未存在的新实体信息,需要较大的计算代价获取新实体的向量表示。
技术实现要素:
3.新实体知识的推理方法涉及了时间知识图谱补全及应用等重要任务,适用于新闻语料等各自然语言相关领域。目前的时间知识图谱表示学习方法大多忽略了随着时间推移而新加入实体的情况,且面向数据进行单一角度的学习不能捕捉更深层的结构和语义信息,导致推理预测模型不能够以较低的计算成本高效、准确地得到新实体的向量表示。
4.针对上述时间知识图谱新实体推理表示学习方面的问题,本发明提出了一种有效的新实体知识推理方法,从时间知识图谱中广泛存在的邻居实体出发,合理借助图谱中存在的邻居信息完成对新实体表示的快速推理预测,并通过邻居的结构及语义信息来提升推理表示模型的准确率,以使得推理模型能够以较小的计算成本并准确获取新实体向量表示的目标,为时间知识图谱的补全、问答等应用任务提供更高效、更稳定的推理表示学习方法。首先提出基于邻居结构感知的负样本采样方法,通过邻居结构信息获取实体关联性更强的负样本数据,其次分别从邻居语义、关系时序,以及不同实体间相互影响度等三个角度出发,引入了基于r-gcn、lstm和注意力机制等三种不同结构的编码器,然后将三种编码器获得的实体向量表示进行加权融合,得到最终的实体表示。最后,利用训练好的推理模型,对存在缺失的四元组数据进行推理预测,从而实现时间知识图谱新实体的推理预测及图谱补全,为图谱后续的智能问答、快速检索等应用提供基础技术支撑。
5.为了实现上述目的,本发明给出的技术方案为:
6.一种面向时间知识图谱中新实体的知识推理方法,其特征在于,包括
7.步骤1、处理数据,构建负样本;
8.步骤2、融合三种结构的编码器对步骤1数据进行编码;
9.步骤3、结合解码器对模型进行训练;
10.步骤4、利用步骤3训练得到的推理模型,实现面向新实体的推理预测。
11.有益效果
12.本发明针对现有面向时间知识图谱的表示学习模型无法处理新加入实体的问题,设计了基于邻居信息的时间知识图谱新实体推理模型,通过融合三种不同结构的编码器,从邻居语义、时序和实体间影响等不同角度学习邻居信息,从而直接计算推理出新实体的
表示,而不用单独为每个实体分配向量并进行拟合,进一步扩展了时间知识图谱推理的能力。
13.另外,本发明还提出了一种基于邻居结构感知的负样本生成方法,摒弃了先前随机生成负样本的方法,从不同跳级的邻居实体中生成不同范围的负样本,提升了负样本中实体间的关联性,从而使得推理表示学习模型具有更好的学习能力。这对知识赋能时代下,基于时间知识图谱实现各个领域的智能问答、辅助决策、高效检索等应用需求具有重大意义。
附图说明
14.附图是对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但不构成对本发明的限制。在附图中:
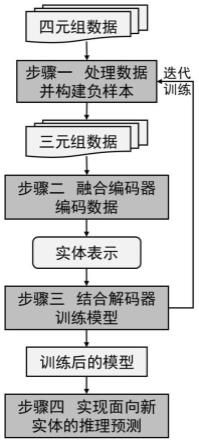
15.图1为面向时间知识图谱中新实体知识推理的流程示意图;
16.图2为步骤一中负样本采样示例图;
17.图3为步骤四中实现面向新实体推理预测的流程示意图;
18.图4为推理预测新实体的示例图。
具体实施方式
19.为了使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的具体实施方式进行清楚、完整的描述。应当理解的是,此处所描述的具体实施方法仅用于说明和解释本发明,并不用于限制本发明。
20.本发明的具体实施过程如图1所示,包括如下4个方面:
21.步骤1、处理数据,构建负样本;
22.步骤2、融合三种结构的编码器对步骤1数据进行编码;
23.步骤3、结合解码器对模型进行训练;
24.步骤4、利用步骤3训练得到的模型,实现面向新实体的推理预测。
25.各个步骤详述如下。
26.第一步:处理数据,构建负样本;
27.1.1:处理数据
28.以新闻语料实体i为例,对于该实体在时间知识图谱中存在的相关四元组(i,r1,j1,τ1),(i,r2,j2,τ2),
…
,(i,rn,jn,τn),jk为实体i的邻居实体,rk为实体间关系,τk为实体关系对应的时间标签,k∈(1,
…
,n)。因为编码器以实体的邻居实体与关系对为输入,所以,通过省去已知的实体i,将上述四元组数据处理为可以满足编码器输入需求的三元组,即(r1,j1,τ1),(r2,j2,τ2),
…
,(rn,jn,τn)。如在新闻语料中,篮球明星lebron james作为球员这一实体类型,曾先后与cleveland cavaliers、miami heat和los angeles lakers等球队这一类型的实体间具有member of的关系,即(lebron james,member of,cleveland cavaliers,2003-2010&2014-2018)、(lebron james,member of,miami heat,2010-2014)和(lebron james,member of,los angeles lakers,2018-)。之后,将处理后的正样本集x输出给步骤1.2和步骤2;
29.1.2:构建负样本
30.为了避免随机生成负样本,本发明借助实体的邻居关系,提出一种邻居结构感知的负样本生成方法,通过划分不同跳级的邻居实体去生成不同范围的负样本。如,对于实体i的某正样本三元组(r1,j1,τ1),若存在与实体j1相关的三元组(r
k1
,k1,τ
k1
),则k1为实体i的二跳邻居实体,通过替换正样本中的实体j1,可以得到一个二跳范围的负样本(r1,k1,τ1);若存在与实体k1相关的三元组(r
l1
,m1,τ
l1
),则m1为实体i的三跳邻居实体,通过替换正样本中的实体j1,可以得到一个三跳范围的负样本(r1,m1,τ1),以此类推,获得较随机生成方法生成的相关性更强的负样本集x
′
。之后,将负样本集数据输出给步骤2。
31.具体的,如图2所示,与实体1相关的正样本有(r2,3,τ2),(r3,4,τ3),而与实体3和实体4相关的二跳正样本分别有(r5,5,τ5)和(r4,8,τ4),则相应的二跳负样本为(r2,5,τ2)和(r3,8,τ3);与实体8相关的正样本有(r8,9,τ8),则相应的三跳负样本为(r3,9,τ3)。即,图2中实体1的负样本集为(r2,5,τ2),(r3,8,τ3)和(r3,9,τ3)。
32.第二步:融合三种结构的编码器对步骤1的数据进行编码;
33.2.1:基于r-gcn的编码器
34.为了有效的学习三元组数据中的邻居语义信息,本发明借助了r-gcn编码器结构,通过参数共享和矩阵分解的方法,利用邻居信息去获取当前实体的向量表示。为了适应本发明中时间知识图谱中存在的新实体,在r-gcn编码器中去除了自旋边的参数,具体的说明如下所述:
35.通过r-gcn学习步骤1所得三元组数据中的邻居结构信息,r-gcn
1.是gcn在多关系图上的变体,可以利用参数共享或矩阵分解的方法,用比较少的参数,从实体的邻居信息中提取实体的特征。r-gcn通过层层叠加,组成一个较深的网络,其中每一层r-gcn计算得到的实体向量表示与上一层r-gcn得到的向量表示有关。实体i在第l+1层的向量表示为:
[0036][0037]
其中,σ(
·
)为激活函数,通常使用relu函数,为知识图谱中的关系集,为知识图谱中实体i在关系r下的邻居实体集。c
i,r
为标准化参数,通常可设置为为标准化参数,通常可设置为为关系r的参数矩阵。而为自旋边的参数。这里,自旋边是为了防止在层间传播过程中,实体的表示的计算只利用邻居信息,最终完全丢失了当前实体的初始信息而为每个实体加上的连接自己的边。但为了解决新实体问题,需要完全抛弃当前实体的信息,只使用邻居的信息编码当前实体,所以在本发明中,取消了自旋边,相应的实体i的向量表示为
[0038][0039]
这里的编码器选用单层r-gcn,并将r-gcn的输出作为实体i的向量表示输出给步骤2.4。
[0040]
2.2:基于lstm的编码器
[0041]
针对本发明时间知识图谱中广泛存在的时间序列信息,基于lstm编码器结构去学习三元组数据中的时间关联信息。为了更好地学习时间关联信息,本发明首先将三元组数据按照时间顺序进行排序,之后进行相应的线性变换,再使用lstm编码器进行编码,具体流程如下所述:
[0042]
2.2.1:考虑到时间知识图谱中广泛存在的时间标签,我们先将步骤1得到的三元组数据中的邻居实体和关系对,按照时间顺序进行排序,得到一个有序序列(r1,j1,τ1),(r2,j2,τ2),
…
,(rn,jn,τn),τ1≤τ2≤
…
≤τn;
[0043]
2.2.2:对步骤2.2.1得到的有序序列进行线性变换:
[0044][0045]
其中为关系rn的相关参数,为实体jn的初始向量,d为向量的维度。通过简单的线性变换,将实体jn与关系rn的信息融合到向量xn中。因此对于实体i,可以得到向量序列:
[0046]
x
1:n
=[x1,x2,
…
,xn]
[0047]
2.2.3:将步骤2.2.2得到的向量序列x
1:n
输入lstm
[2]
,一个lstm单元接受一个输入向量x
t
∈x
1:n
,以及上一个lstm的隐藏状态作为输入。通过遗忘门f
t
∈[0,1]d决定丢弃之前的单元状态的哪些信息,0表示丢弃所有信息,1表示保留所有信息:
[0048]ft
=σ(wfx
t
+ufh
t-1
+bf)
[0049]
其中,σ(
·
)表示sigmoid函数,为遗忘门的权重矩阵,为偏置;
[0050]
2.2.4:更新单元状态。首先,由输入门i
t
∈[0,1]d决定更新哪些信息:
[0051]it
=σ(wix
t
+u
iht-1
+bi)
[0052]
然后,使用一个tanh层来生成新的候选向量
[0053][0054]
接下来就可以将lstm区块的状态从c
t-1
更新到c
t
:
[0055][0056]
这里,为门的权重矩阵,为门的偏置,
⊙
表示元素相乘。
[0057]
2.2.5:获得实体的编码表示。由输出门确定输出什么信息:
[0058]ot
=σ(wox
t
+u
oht-1
+bo)
[0059]ht
=o
t
⊙
tanh c
t
[0060]
同样的,表示权重矩阵,bo表示偏置。
[0061]
通过以上过程,输入序列x
1:n
被转换为n个隐藏状态h1,h2,
…
,hn。由于每个隐藏状态都由上一个隐藏状态结合当前输入向量计算得来,最后一个隐藏状态hn已涵盖了整个输入序列x
1:n
的信息,所以将输出hn作为实体i的表示输出给步骤2.4。
[0062]
2.3基于注意力机制的编码器
[0063]
为了充分挖掘学习邻居实体间的相互影响,本专利中基于注意力机制的编码器首
先执行一次自注意力机制,然后再执行一次注意力机制。其中,在注意力机制过程中,将自注意力机制得到的向量序列进行均值求和,由此得到对应实体的粗糙表示,并将其作为查询向量进行学习,具体的流程如下所述:
[0064]
2.3.1:考虑到不同的邻居实体对当前实体的重要程度不同,通过引入注意力机制
[3]
来突出学习关键信息,同时利用自注意力机制来挖掘邻居实体间的相互影响。同步骤2.2.2对步骤1输出数据进行线性变换,得到融合了邻居实体与关系信息的输入序列x
1:n
=[x1,x2,
…
,xn];
[0065]
2.3.2:对于输入序列x
1:n
,我们执行一次自注意力机制。对于每一个输入向量,自注意力机制将计算该向量对输入序列其他向量的关注程度。
[0066]
2.3.2.1:将每个输入向量与三个权重矩阵相乘,得到三个向量:键向量ki、查询向量qi和值vi向量,即
[0067][0068][0069][0070]
2.3.2.2:自注意力机制将当前输入xi的查询向量qi与其他输入向量xj的键向量kj相乘,得到一个得分s,即:
[0071][0072]
2.3.2.3:为了防止在应用softmax时得分存在较大偏差,将得分进行归一化:
[0073][0074]
由此得到一个由得分构成的向量s
′
i,1:n
=[s
′
i,1
,s
′
i,2
,
…
,s
′
i,n
];
[0075]
2.3.2.4:对s
′
i,1:n
应用softmax函数,即得到当前输入xi对其他输入的关注程度:
[0076]
α
i,1:n
=softmax(s
′
i,1:n
)
[0077]
2.3.2.5:将每一个输入向量xj的值向量vj与对应的权重α
i,j
相乘,并将得到的所有向量进行求和,即:
[0078][0079]
其中zi已经包含了所有其他输入对当前输入的影响,将zi作为输入xi在本层的输出。因此,对于输入序列x
1:n
,自注意力层输出向量序列z
1:n
=[z1,z2,
…
,zn];
[0080]
2.3.3:对于向量序列z
1:n
=[z1,z2,
…
,zn],执行一次注意力机制,得到当前实体的向量表示。
[0081]
将向量序列z
1:n
进行均值求和得到当前实体的粗糙表示,并作为本层注意力机制的查询向量q,即:
[0082][0083]
因此,每个输入向量的权重为:
[0084]
αj=softmax(qzj)
[0085]
最终对所有输入向量进行加权求和得到当前实体i的向量表示,并将输出给步骤2.4:
[0086][0087]
2.4融合三种编码器
[0088]
对步骤2.1、2.2和2.3得到的表示进行联合,得到实体的最终表示。
[0089]
对于实体i,在关系r与时间τ下的最终表示为:
[0090][0091][0092]
其中σ为sigmoid函数,参数h=1,2,3为实体基于结构信息的表示的权重。相应的,实体j的最终表示记为
[0093]
第3步:结合步骤2中的解码器对模型进行训练;
[0094]
3.1解码器
[0095]
对于一个四元组(i,r,j,τ),解码器将利用hyte
[4]
的评分函数计算四元组的得分,即:
[0096][0097][0098][0099][0100]
其中,er分别为头实体、尾实体和关系的向量,‖w
τ
‖2=1。
[0101]
由于实体的表示已由步骤2中的编码器计算完成,解码器只需要学习关系的向量表示以及时间超平面的法向量即可;
[0102]
3.2计算损失值。
[0103]
对于步骤1得到的正样本x以及负样本x
′
,损失值loss=max(0,f(x)-f(x
′
)+γ),其中f为评分函数f
τ
(i,r,j),为向量的第一或第二范式,γ》0为正负样本之间的间距。之后将损失值loss提供给步骤3.3;
[0104]
3.3:后向传播阶段优化模型参数。
[0105]
根据步骤3.2得到的损失值,使用梯度下降法或adam算法调整模型参数,最小化模型整体的损失值;
[0106]
3.4:迭代训练模型
[0107]
如果进行一次迭代后达到停止迭代的条件(损失值小于设置的阈值或迭代次数达到最大次数),则结束训练,得到训练完的模型,提供给步骤4,否则继续步骤1.2。
[0108]
第4步:利用步骤3训练得到的模型,实现面向新实体的推理预测。如图3所示;
[0109]
4.1:在步骤3.4得到的模型中,将知识图谱中的所有实体(或关系)分别代入到该
四元组中,并根据步骤3.2中计算每次代入实体(或关系)后评分函数f的值,并将所有实体(或关系)的评分提供给步骤4.2。
[0110]
4.2:根据评分进行排序,选出评分最高的一个或多个实体(或关系)作为预测值。如图4是推理预测新实体的示例,通过利用推理模型学习到知识图谱中已有的四元组信息,获得各个邻居实体的向量表示,之后通过计算评分推得与缺失四元组中关系和尾实体相关性最强的实体信息,即可以推理出曾经先后效力于骑士、热火、骑士、湖人等球队的球员是lebron james。
[0111]
参考文献
[0112]
[1]schlichtkrull m,kipf t n,bloem p,et al.modeling relational data with graph convolutional networks[c]//european semantic web conference.springer,cham,2018:593-607.
[0113]
[2]huang z,xu w,yu k.bidirectional lstm-crf models for sequence tagging[j].arxiv preprint arxiv:1508.01991,2015.
[0114]
[3]vaswani a,shazeer n,parmar n,et al.attention is all you need[c]//advances in neural information processing systems.2017:5998-6008.
[0115]
[4]dasgupta s s,ray s n,talukdar p.hyte:hyperplane-based temporally aware knowledge graph embedding[c]//proceedings of the 2018conference on empirical methods in natural language processing.2018:2001-2011.
[0116]
创新点
[0117]
提出了一种面向时间知识图谱中新实体的知识推理方法,与当前从单一信息全量获取新实体表示的方法不同,本发明从时间图谱中的邻居结构和语义信息入手,提出了基于邻居结构感知的负样本生成方法,通过划分不同跳级的邻居实体去生成不同范围的负样本,从而提升训练数据的质量。另外,本发明通过r-gcn、lstm和注意力机制等三种编码器结构,融合关注了时间知识图谱中的邻居语义、时序以及不同邻居间相互影响程度等信息,使得推理表示模型不仅可以通过邻居实体快速习得新实体的表示,还能够在一定程度上提升表示结果的准确率。
[0118]
本发明提出的新实体知识推理方法在推理预测和补全时间知识图谱任务中有较好的表现,提高了新实体推理预测的准确率和效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1