人脸模型的表情调整方法、装置、设备及存储介质与流程
本申请涉及人工智能,尤其涉及一种人脸模型的表情调整方法、装置、设备及存储介质。
背景技术:
1、随着电子技术的发展,立体模型在虚拟现实、数字娱乐、通信、计算机视觉以及机器人技术等诸多领域有着非常广泛的应用。其中,人脸模型是一种常用的立体模型,如何灵活地调整人脸模型的表情,非常受到重视。传统的动画制作只能控制人脸模型的表情按照预设流程变化,已逐渐难以满足当前对人脸模型调节的灵活性需求。
技术实现思路
1、本申请实施例提供了一种人脸模型的表情调整方法、装置、设备及存储介质,以通过语音数据灵活地驱动人脸模型的表情调整,使表情调整后的人脸模型与发出语音数据的真实人脸的表情相匹配。
2、第一方面,本申请实施例提供了一种人脸模型的表情调整方法,包括:
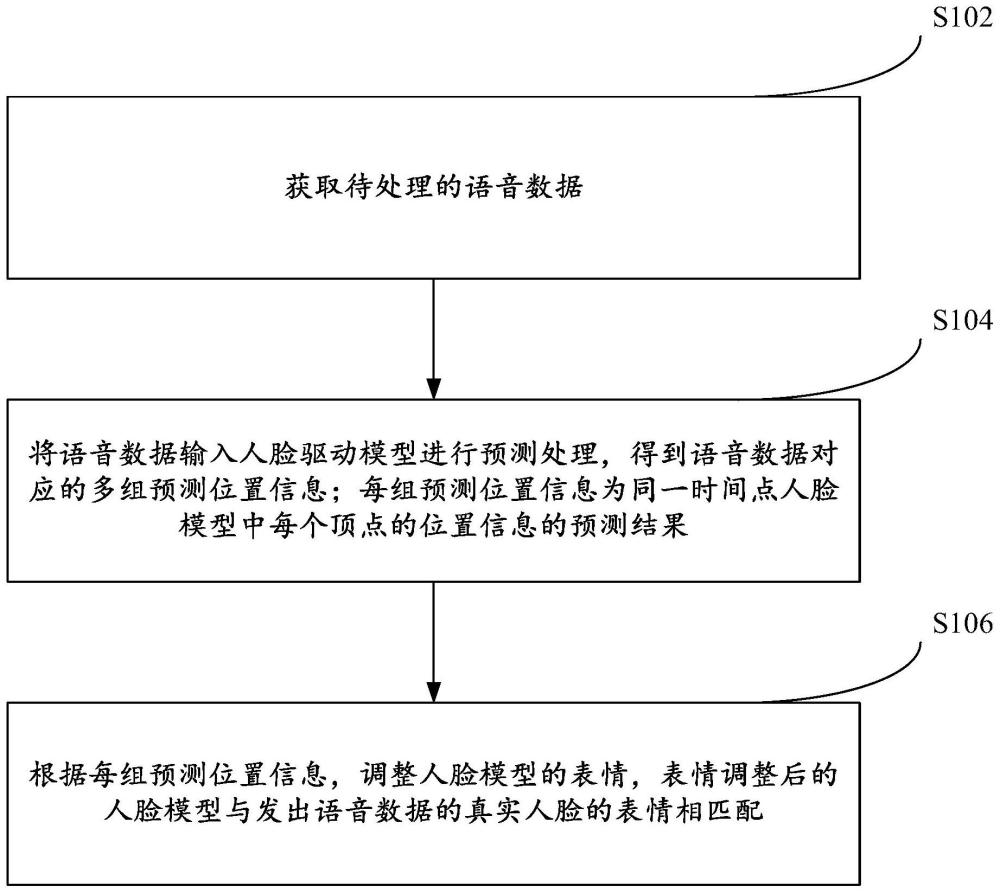
3、获取待处理的语音数据;
4、将所述语音数据输入人脸驱动模型进行预测处理,得到所述语音数据对应的多组预测位置信息;每组所述预测位置信息为同一时间点所述人脸模型中每个顶点的位置信息的预测结果;
5、根据每组所述预测位置信息,调整所述人脸模型的表情,表情调整后的人脸模型与发出所述语音数据的真实人脸的表情相匹配。
6、第二方面,本申请实施例提供了一种人脸模型的表情调整装置,包括:
7、第一获取模块,用于获取待处理的语音数据;
8、预测模块,用于将所述语音数据输入人脸驱动模型进行预测处理,得到所述语音数据对应的多组预测位置信息;每组所述预测位置信息为同一时间点所述人脸模型中每个顶点的位置信息的预测结果;
9、调整模块,用于根据每组所述预测位置信息,调整所述人脸模型的表情,表情调整后的人脸模型与发出所述语音数据的真实人脸的表情相匹配。第一获取模块
10、第三方面,本申请实施例提供了一种人脸模型的表情调整设备,包括:处理器;以及,被配置为存储计算机可执行指令的存储器,所述计算机可执行指令在被执行时使所述处理器执行第一方面所述的人脸模型的表情调整方法。
11、第四方面,本申请实施例提供了一种计算机可读存储介质,用于存储计算机可执行指令,所述计算机可执行指令在被处理器执行时实现如第一方面所述的人脸模型的表情调整方法。
12、可以看出,在本申请实施例中,首先,获取待处理的语音数据;接着,将语音数据输入人脸驱动模型进行预测处理,得到语音数据对应的多组预测位置信息;每组预测位置信息为同一时间点人脸模型中每个顶点的位置信息的预测结果;最后,根据每组预测位置信息,调整人脸模型的表情,表情调整后的人脸模型与发出语音数据的真实人脸的表情相匹配,以此,一方面,通过人脸驱动模型对语音数据进行预测处理,得到语音数据对应的多组预测位置信息,进而基于每组预测位置信息调整人脸模型的表情,可以不依赖于动作捕捉而是通过语音数据驱动人脸模型的表情调整,降低了表情调整的过程中对实时性的要求;另一方面,获取语音数据的难度极低,且表情调整后的人脸模型与发出语音数据的真实人脸的表情相匹配,可以提高表情调整的灵活性和易操作性。
技术特征:
1.一种人脸模型的表情调整方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述人脸驱动模型包括依次连接的频率分析模块、语音处理模块以及顶点映射模块;
3.根据权利要求2所述的方法,其特征在于,所述顶点映射模块包括依次连接的第一全连接层和第二全连接层;
4.根据权利要求2所述的方法,其特征在于,所述频率分析模块包括依次连接的自相关层以及包括n个第一卷积层的卷积模块;所述卷积模块中首个第一卷积层的输入为所述自相关层的输出,除首个第一卷积层外的每个第一卷积层的输入为前一个第一卷积层的输出;
5.根据权利要求2所述的方法,其特征在于,所述语音数据包括多帧子语音数据;所述语音处理模块包括依次连接的m个第二卷积层;所述语音处理模块中除首个第二卷积层外的每个第二卷积层的输入为前一个第二卷积层的输出;
6.根据权利要求1所述的方法,其特征在于,所述人脸模型包括数字人的目标人脸模型;所述根据每组所述预测位置信息,调整所述人脸模型的表情,包括:
7.根据权利要求1所述的方法,其特征在于,所述获取待处理的语音数据之前,还包括:
8.根据权利要求7所述的方法,其特征在于,所述人脸驱动模型的损失函数由位置项、运动项以及正则项确定;
9.一种人脸模型的表情调整装置,其特征在于,包括:
10.一种人脸模型的表情调整设备,其特征在于,所述设备包括:
11.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于存储计算机可执行指令,所述计算机可执行指令在被处理器执行时实现如权利要求1-8任一项所述的人脸模型的表情调整方法。
技术总结
本说明书实施例提供了人脸模型的表情调整方法、装置、设备及存储介质,其中,一种人脸模型的表情调整方法包括:获取待处理的语音数据;将语音数据输入人脸驱动模型进行预测处理,得到语音数据对应的多组预测位置信息;每组预测位置信息为同一时间点人脸模型中每个顶点的位置信息的预测结果;根据每组预测位置信息,调整人脸模型的表情,表情调整后的人脸模型与发出语音数据的真实人脸的表情相匹配,以此,实现通过语音数据驱动人脸模型的表情调整,降低实时性要求,以及,提高灵活性和易操作性。
技术研发人员:杨茂,冯晟,韩卫强,吴海英,蒋宁,耿福明,李云彬
受保护的技术使用者:马上消费金融股份有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!