模型训练方法、数据处理方法、装置、设备及存储介质与流程
本申请涉及人工智能,尤其涉及一种模型训练方法、数据处理方法、装置、设备及存储介质。
背景技术:
1、识别模型可以用于对两个文本是否为相同的语义进行识别,也可以用于对两个图像是否包括相同的目标进行识别。识别模型可以通过多种方式训练得到,如自监督学习和无监督学习。
2、在训练样本不足的情况下训练识别模型,需要对已有的训练样本进行数据增强,以扩充训练样本。相关技术采用的方式是将增强数据作为正例样本训练识别模型。但通过该方式训练得到的识别模型的鲁棒性较差。
技术实现思路
1、本申请实施例提供一种模型训练方法、数据处理方法、装置、设备及存储介质,以提高训练得到的识别模型的鲁棒性。
2、第一方面,本申请实施例提供一种模型训练方法,包括:
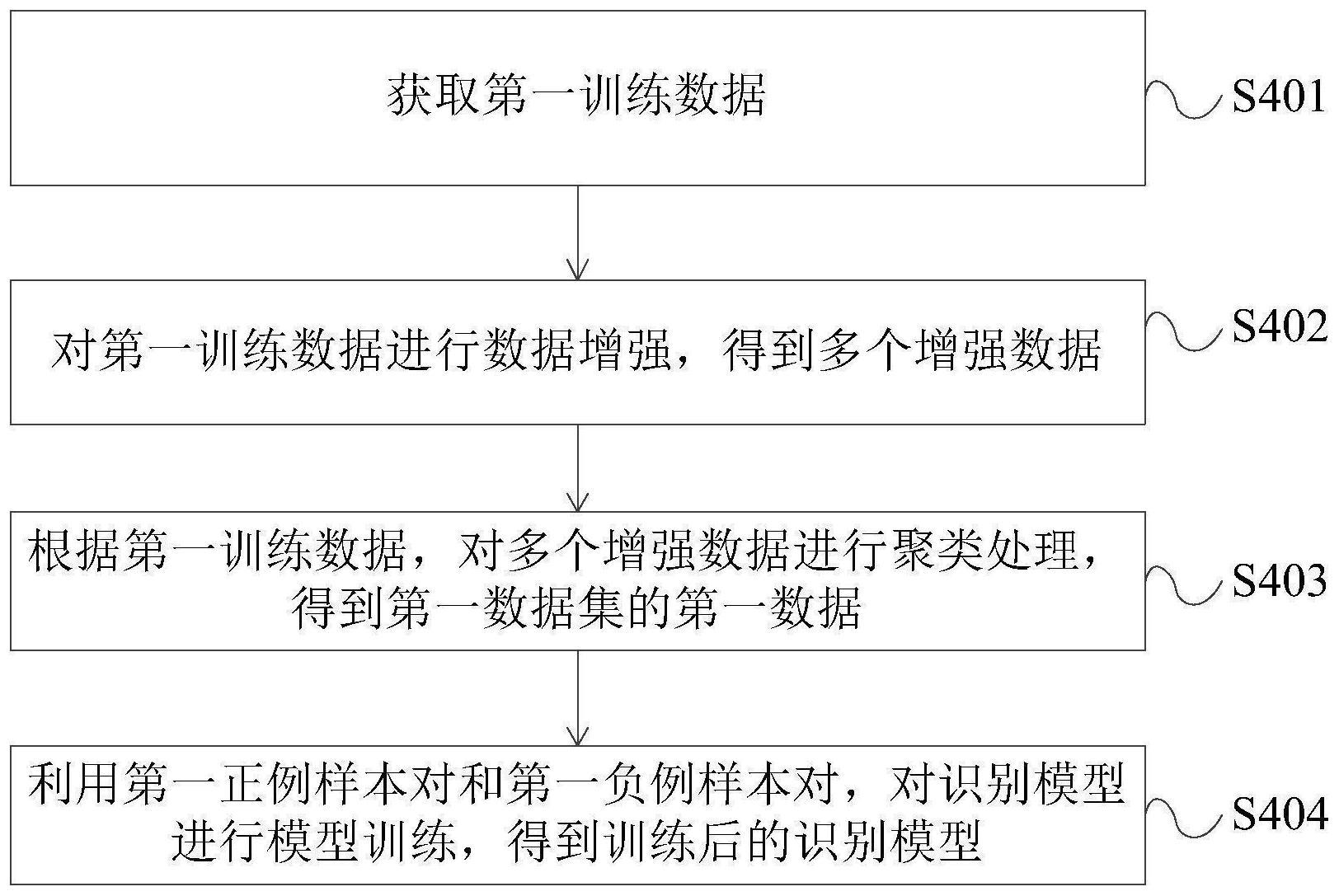
3、获取第一训练数据,所述第一训练数据包括图像样本或文本样本;
4、对所述第一训练数据进行数据增强,得到多个增强数据;
5、根据所述第一训练数据对所述多个增强数据进行聚类处理,得到第一数据集;所述第一数据集包括的第一数据与所述第一训练数据聚类为表示相同的含义;
6、利用第一正例样本对和第一负例样本对,对识别模型进行模型训练,得到训练后的识别模型;所述第一正例样本对包括所述第一数据集中的两个数据;所述第一负例样本对包括所述第一训练数据和第二训练数据,若所述第一训练数据为图像样本,则所述第一训练数据和所述第二训练数据包含的对象不同,若所述第一训练数据为文本样本,则所述第一训练数据和所述第二训练数据的语义不同。
7、可以看出,本申请实施例提供的模型训练方法通过对第一训练数据进行数据增强,得到多个增强数据,实现训练样本的扩充。然后采用聚类处理将多个增强数据聚为与第一训练数据表示相同的含义的第一数据集,实现增强数据的分类,避免直接采用增强数据作为正例样本训练识别模型,导致识别模型的鲁棒性降低。此外,将第一数据集中的两个数据作为第一正例样本对、将第一训练数据和第二训练数据作为第一负例样本对,训练得到识别模型,能够提高训练得到的识别模型的鲁棒性。
8、第二方面,本申请实施例提供一种数据处理方法,包括:
9、获取第一数据和第二数据,所述第一数据和所述第二数据均为图像或文本;
10、将所述第一数据和所述第二数据输入识别模型进行识别处理,得到数据识别结果,所述数据识别结果用于指示所述第一数据和所述第二数据的含义是否相同,所述识别模型为第一方面所述的模型训练方法训练得到的。
11、可以看出,本申请实施例通过将第一数据和第二数据输入第一方面的模型训练方法训练得到的识别模型,由于识别模型具有很好的鲁棒性,因此能够对第一数据和第二数据进行准确的识别。
12、第三方面,本申请实施例提供一种模型训练装置,包括:
13、获取模块,用于获取第一训练数据,所述第一训练数据包括图像样本或文本样本;
14、数据增强模块,用于对所述第一训练数据进行数据增强,得到多个增强数据;
15、处理模块,用于根据所述第一训练数据对所述多个增强数据进行聚类处理,得到第一数据集;所述第一数据集包括的第一数据与所述第一训练数据聚类为表示相同的含义;
16、训练模块,用于利用第一正例样本对和第一负例样本对,对识别模型进行模型训练,得到训练后的识别模型;所述第一正例样本对包括所述第一数据集中的两个数据;所述第一负例样本对包括所述第一训练数据和第二训练数据,若所述第一训练数据为图像样本,则所述第一训练数据和所述第二训练数据包含的对象不同,若所述第一训练数据为文本样本,则所述第一训练数据和所述第二训练数据的语义不同。
17、第四方面,本申请实施例提供一种数据处理装置,包括:
18、获取模块,用于获取第一数据和第二数据,所述第一数据和所述第二数据均为图像或文本;
19、识别模块,用于将所述第一数据和所述第二数据输入识别模型进行识别处理,得到数据识别结果,所述数据识别结果用于指示所述第一数据和所述第二数据的含义是否相同,所述识别模型为第一方面所述的模型训练方法训练得到的。
20、第五方面,本申请实施例提供一种电子设备,包括处理器、存储器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现如第一方面中任一项所述的模型训练方法或第二方面中任一项所述的数据处理方法。
21、第六方面,本申请实施例提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,当计算机程序在电子设备上运行时,使得电子设备执行如第一方面中任一项所述的模型训练方法或第二方面中任一项所述的数据处理方法。
22、第七方面,本申请实施例提供一种计算机程序产品,包括计算机程序,该计算机程序在电子设备上运行时,使得电子设备执行如第一方面中任一项所述的模型训练方法或第二方面中任一项所述的数据处理方法。
23、本申请实施例提供一种模型训练方法、数据处理方法、装置、设备及存储介质。本申请实施例通过对第一训练数据进行数据增强,得到多个增强数据,实现训练样本的扩充。然后采用聚类处理将多个增强数据聚为与第一训练数据表示相同的含义的第一数据集,实现增强数据的分类,避免直接采用增强数据作为正例样本训练识别模型,导致识别模型的鲁棒性降低。此外,将第一数据集中的两个数据作为第一正例样本对、将第一训练数据和第二训练数据作为第一负例样本对,训练得到识别模型,能够提高训练得到的识别模型的鲁棒性。
技术特征:
1.一种模型训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的模型训练方法,其特征在于,在根据所述第一训练数据对所述多个增强数据进行聚类处理后,还得到第二数据集,所述第二数据集包括的第二数据与所述第一训练数据聚类为表示不同的含义;所述方法还包括:
3.根据权利要求2所述的模型训练方法,其特征在于,针对每个所述第二数据集包括的第二数据,对所述训练后的识别模型进行测试均有以下方式:
4.根据权利要求3所述的模型训练方法,其特征在于,所述方法还包括:
5.根据权利要求4所述的模型训练方法,其特征在于,在所述第二负例样本中,所述第二数据与所述第一训练数据的比例为预设比例。
6.根据权利要求3所述的模型训练方法,其特征在于,所述方法还包括:
7.根据权利要求1至6任一项所述的模型训练方法,其特征在于,所述方法还包括:
8.一种数据处理方法,其特征在于,包括:
9.一种模型训练装置,其特征在于,包括:
10.一种数据处理装置,其特征在于,包括:
11.一种电子设备,包括处理器、存储器及存储在所述存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7中任一项所述的模型训练方法或权利要求8所述的数据处理方法。
12.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,当所述计算机程序在电子设备上运行时,使得电子设备执行如权利要求1至7中任一项所述的模型训练方法或权利要求8所述的数据处理方法。
技术总结
本申请提供一种模型训练方法、数据处理方法、装置、设备及存储介质,该模型训练方法包括:获取第一训练数据;对第一训练数据进行数据增强,得到多个增强数据;根据第一训练数据对多个增强数据进行聚类处理,得到第一数据集,第一数据集包括的第一数据与第一训练数据聚类为表示相同的含义;利用第一正例样本对和第一负例样本对,对识别模型进行模型训练,得到训练后的识别模型;第一正例样本对包括第一数据集中的两个数据;第一负例样本对包括第一训练数据和第二训练数据,其中,识别模型用于识别两个样本的含义是否相同。本申请能够提高识别模型的鲁棒性。
技术研发人员:吕乐宾,蒋宁,肖冰,李宽,丁隆耀
受保护的技术使用者:马上消费金融股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!