基于注意力图像的人脸表情识别方法
1.本发明属于图像处理技术领域,更进一步涉及图像识别技术领域中一种基于注意力图像的人脸表情识别方法。本发明可应用于对智慧教育、辅助医疗、车载安全等诸多复杂场景中人脸的表情类别进行识别。
背景技术:
2.人脸表情识别是指利用计算机提取人脸表情图像特征,并结合人类已有的先验知识进行特征建模,挖掘人脸表情图像与情感之间的关系,从而识别人脸表情的类别。人脸表情能够有效表达个人的情绪,是人类情绪的直观反应。因此,人脸表情识别技术在智慧教育、辅助医疗、车载安全等人工智能领域均具有广泛的应用。由于人脸表情识别任务中存在类内差异大及类间差异小的特点,人脸表情识别任务的性能并不是很理想,这需要网络能够很好地挖掘人脸的关键区域。
3.yong li等人在其发表的论文“occlusion aware facial expression recognition using cnn with attention mechanism”(ieee transactions on image processing:2439
–
2450,2019)中提出了一种基于注意力机制的卷积神经网络模型用于感知人脸的遮挡区域并专注于最具辨别力的未遮挡区域。该方法的实施步骤是:收集人脸表情图像并对其进行人脸关键点检测;将人脸表情图像作为输入数据并使用卷积神经网络对其进行特征提取,生成相应的特征图;对特征图进行全局特征编码并通过注意力网络对其进行重要性权重学习;根据人脸关键点对特征图进行区域分解得到24个局部块,对每个局部块进行局部特征编码并通过注意力网络对其进行重要性权重学习;对得到的局部特征及全局特征根据其对应的重要性权重进行特征融合并输入到分类器中进行人脸表情类别的识别。该方法存在的不足之处是:人脸关键区域的挖掘依赖于人脸关键点的检测,若人脸关键点的检测效果不佳,则会导致挖掘的人脸关键区域不够准确,容易对人脸图像的表情类别做出误判。
4.哈尔滨理工大学在其申请的专利文献“一种基于注意力机制的人脸表情识别方法”(申请号:202110663990.7,申请公布号:cn 113392766 a)中公开一种基于注意力机制的人脸表情识别方法。该方法的实现步骤是:收集数据集并对数据集进行预处理;对每幅人脸表情图像标注人脸特征关键点;对图像进行关键位置裁剪并将裁剪的图像缩放;将得到的图像以及整张人脸表情图像输入到神经网络中进行局部特征与全局特征的识别和获取;对得到的特征进行特征融合并输入到分类器中进行人脸表情类别的识别。该方法存在的不足之处是:该方法通过将人脸图像裁剪为块来挖掘人脸的关键区域,关键区域的挖掘是以图像块而不是单个的像素点为单位,导致挖掘的关键区域较为粗糙,影响人脸表情图像的识别准确率。
技术实现要素:
5.本发明的目的在于针对上述现有技术的不足,提出一种基于注意力图像的人脸表
情识别方法,用于解决现有技术在挖掘人脸关键区域时挖掘的人脸关键区域不够准确,以及挖掘的人脸关键区域较为粗糙的问题。
6.为实现上述目的,本发明的思路是,为每张人脸表情图像生成与其分辨率相同且标签也相同的注意力图像,注意力图像仅包含人脸表情图像的关键区域像素,使用注意力图像来挖掘人脸的关键区域,可以克服现有技术在挖掘人脸关键区域时,因对人脸关键点检测技术的依赖,而导致挖掘的人脸关键区域不够准确的问题,提高人脸表情图像的识别准确率。本发明利用人脸表情图像及其对应的标签、图像的注意力图像及其对应的标签共同训练卷积神经网络,使得网络更加关注人脸表情图像中的关键区域像素,实现在像素级别上对人脸关键区域的自动定位,解决了现有技术中挖掘的人脸关键区域较为粗糙的问题。
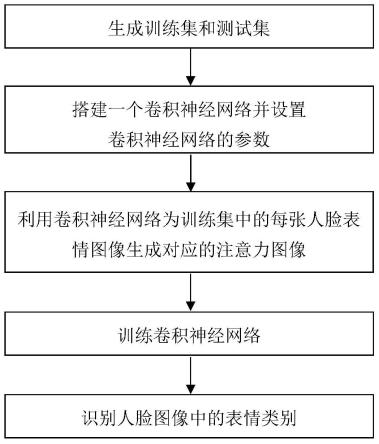
7.实现本发明目的的具体步骤如下:
8.步骤1,生成训练集:
9.步骤1.1,采集至少10000张人脸表情图像组成样本集,样本集中至少包括3种不同的人脸表情的情绪类别,每种情绪类别至少采集280张图像;
10.步骤1.2,采用224
×
224的采样分辨率,对样本集中的每张图像进行双线性采样,对采样后的图像进行归一化处理,将归一化后的所有人脸表情图像及其对应的标签组成训练集;
11.步骤2,搭建一个卷积神经网络并设置卷积神经网络的参数;
12.步骤3,利用卷积神经网络为训练集中的每张人脸表情图像生成对应的注意力图像:
13.步骤3.1,将从训练集中随机选取的一张人脸表情图像输入到卷积神经网络中,输出所选图像属于真实标签的概率值以及所选图像的特征图;
14.步骤3.2,按照下式,计算所选图像的特征图中每个通道的权重:
[0015][0016]
其中,ak表示所选图像的特征图中第k个通道ak的权重,m和n分别表示通道ak在垂直高度和水平宽度方向上的元素总数,i和j分别表示通道ak在垂直高度和水平宽度方向上的元素序号,h表示将所选图像输入到卷积神经网络后输出的属于真实标签的概率值;
[0017]
步骤3.3,对特征图中的所有通道加权求和,得到所选图像的加权特征图;
[0018]
步骤3.4,计算加权特征图中所有元素的均值,将加权特征图中小于或等于均值的元素置为0,得到所选图像的重要性矩阵;
[0019]
步骤3.5,对重要性矩阵进行归一化处理,将归一化后的重要性矩阵缩放至与所选图像相同尺寸,得到所选图像的注意力矩阵;
[0020]
步骤3.6,将所选图像与其注意力矩阵点乘,得到所选图像的注意力图像,并将所选图像的标签作为注意力图像的标签;
[0021]
步骤3.7,判断是否选完训练集中所有的人脸表情图像,若是,则执行步骤4,否则,执行步骤3.1;
[0022]
步骤4,训练卷积神经网络:
[0023]
按照批次将训练集中的图像及其对应的标签、图像的注意力图像及其对应的标签依次输入到卷积神经网络中,使用adam优化器优化训练过程,通过梯度下降算法,迭代更新卷积神经网络中各层的参数,直至卷积神经网络的交叉熵损失函数收敛为止,得到训练好的卷积神经网络;
[0024]
步骤5,识别人脸图像中的表情类别:
[0025]
采用224
×
224的采样分辨率,对每张待识别人脸图像进行双线性采样,对采样后的图像进行归一化处理,将归一化后的图像输入到训练好的卷积神经网络中,输出该张人脸图像的表情类别。
[0026]
本发明与现有技术相比,具有以下优点:
[0027]
第一,本发明为每张人脸表情图像生成与其分辨率相同且标签也相同的注意力图像,用于挖掘人脸的关键区域,克服了现有技术对挖掘的人脸关键区域不够准确的不足,使得本发明提高了人脸表情图像的识别准确率。
[0028]
第二,本发明利用人脸表情图像及其对应的标签、注意力图像及其对应的标签共同训练卷积神经网络,解决了现有技术中挖掘的人脸关键区域较为粗糙的缺陷,使得本发明训练好的网络更加关注人脸表情图像中的关键区域像素,实现在像素级别上对人脸关键区域的自动定位。
附图说明
[0029]
图1为本发明的实现流程图;
[0030]
图2为本发明生成的注意力图像的效果图。
具体实施方式
[0031]
以下结合附图和实施例,对本发明做进一步的详细描述。
[0032]
参照图1和实施例,对本发明的实现步骤做进一步的详细描述。
[0033]
步骤1,生成训练集和测试集。
[0034]
步骤1.1,本发明的实施例是从野外人脸表情数据集raf-db中采集标注为愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性共七种人脸表情图像,每种情绪类别至少采集350张,共采集15539张人脸表情图像组成样本集。
[0035]
步骤1.2,使用224
×
224的采样分辨率,对样本集中的每张图像进行双线性采样,对采样后的图像进行归一化处理,得到归一化后的样本集。
[0036]
步骤1.3,将从归一化后的样本集中随机选取的12271张人脸表情图像及其对应的标签组成训练集,每种情绪类别至少280张;将剩余的3068张人脸表情图像及其对应的标签组成测试集,每种情绪类别至少70张。
[0037]
步骤2,搭建一个卷积神经网络并设置卷积神经网络的参数。
[0038]
步骤2.1,搭建一个卷积神经网络,其结构依次为:输入层,第一卷积层,第二卷积层,第一池化层,第三卷积层,第四卷积层,第二池化层,第五卷积层,第六卷积层,第七卷积层,第三池化层,第八卷积层,第九卷积层,第十卷积层,第四池化层,第十一卷积层,第十二卷积层,第十三卷积层,第五池化层,展平层,第一全连接层,随机失活层,第二全连接层,输出层。
[0039]
步骤2.2,设置卷积神经网络的参数如下:
[0040]
将输入层的维度大小设置为b
×
224
×
224
×
3,其中,b表示卷积神经网络一次输入所选取的样本数,在本发明实施例中,训练阶段的b设置为128;
[0041]
将第一至第十三卷积层的卷积核个数依次设置为64,64,128,128,256,256,256,512,512,512,512,512,512,卷积核尺寸均设置为3
×
3,步长均设置为1,激活函数均采用线性整流函数;
[0042]
将第一至第五池化层的池化窗口均设置为2
×
2,步长均设置为2;
[0043]
展平层采用flatten函数将输入的矩阵拉伸成一个向量;
[0044]
将第一全连接层的节点数量设置为512,激活函数采用带泄露的线性整流函数;将第二全连接层的节点数量设置为7;
[0045]
随机失活层采用dropout函数将每个神经元以概率p置为0,在本发明实施例中,p=0.3;
[0046]
在训练阶段,输出层的输出结果由输入图像属于真实标签的概率值和输入图像的特征图组成。在测试阶段,输出层仅输出输入图像的表情类别预测结果。
[0047]
步骤3,利用卷积神经网络为训练集中的每张人脸表情图像生成对应的注意力图像。
[0048]
步骤3.1,将从训练集中随机选取的一张人脸表情图像输入到卷积神经网络中,输出所选图像属于真实标签的概率值以及所选图像的特征图。
[0049]
步骤3.2,按照下式,计算所选图像的特征图中每个通道的权重:
[0050][0051]
其中,ak表示所选图像的特征图中第k个通道ak的权重,m和n分别表示通道ak在垂直高度和水平宽度方向上的元素总数,i和j分别表示通道ak在垂直高度和水平宽度方向上的元素序号,k表示将所选图像输入到卷积神经网络后输出的属于真实标签的概率值,在本发明实施例中,m=n=7。
[0052]
步骤3.3,按照下式,对特征图中的所有通道加权求和,得到所选图像的加权特征图:
[0053][0054]
其中,map表示所选图像的加权特征图,d表示特征图的通道总数,k表示特征图的通道序号,ak表示特征图中第k个通道ak的权重,在本发明实施例中,d=512。
[0055]
步骤3.4,计算加权特征图中所有元素的均值,将加权特征图中小于或等于均值的元素置为0,得到所选图像的重要性矩阵。
[0056]
步骤3.5,对重要性矩阵进行归一化处理,将归一化后的重要性矩阵缩放至与所选图像相同尺寸,得到所选图像的注意力矩阵。
[0057]
步骤3.6,将所选图像与其注意力矩阵点乘,得到所选图像的注意力图像,并令注意力图像的标签与所选图像的标签相同。
[0058]
步骤3.7,判断是否选完训练集中所有的人脸表情图像,若是,则执行步骤4,否则,
on image processing:2439
–
2450,2019)中提出的一种基于注意力机制的卷积神经网络模型。
[0077]
为了评价本发明仿真的效果,利用下述分类精度公式,分别对本发明仿真实验中每种方法的两个分类结果进行评价,其评价结果如表1所示。
[0078][0079]
表1.本发明与现有技术分类结果的精度对比表
[0080]
数据集现有技术(%)本发明(%)1.raf-db85.0786.682.affectnet58.7859.08
[0081]
结合表1可以看出,本发明在raf-db和affectnet测试集中的分类精度分别为86.68%和59.08%,均高于现有技术,证明本发明可以得到更好的人脸表情图像的分类精度。
[0082]
下面参照图2,对本发明实施例中的一张训练图片分别利用训练前的卷积神经网络和训练好的卷积神经网络所生成的注意力图像作进一步的描述。
[0083]
图2(a)为本发明实施例中的一张训练图片,图2(b)是利用训练前的卷积神经网络生成的与训练图片相同分辨率的注意力图像,图2(c)是利用训练好的卷积神经网络生成的与训练图片相同分辨率的注意力图像。
[0084]
图2(b)和图2(c)中将像素点值从0至255之间的变化,通过颜色由黑到白进行表达。从视觉上观察图2(b)和图2(c)中的像素点,若像素点的颜色越接近黑色,则代表该像素点对应图2(a)中相应位置的像素点为非关键像素点;若像素点的颜色越接近白色,则代表该像素点对应图2(a)中相应位置的像素点为关键像素点。
[0085]
结合图2(b)和图2(c)可以看出,图2(b)中对应图2(a)中面部动作变化较大的额头、眼角和嘴角等关键区域均接近黑色,说明图2(b)没有挖掘到图2(a)中的关键区域。而图2(c)中对应图2(a)中面部动作变化较大的额头、眼角和嘴角等关键区域均接近白色,说明图2(c)更好地挖掘出了图2(a)中的关键区域,证明了本发明所提出的基于注意力图像的人脸表情识别方法能够准确挖掘出人脸的关键区域。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1