一种基于类别感知的跨区域友谊推断方法
本发明涉及跨区域友谊推断领域,具体涉及一种基于类别感知的跨区域友谊推断方法。
背景技术:
1、近年来,随着基于位置的服务和在线社交网络的普及,基于位置社交网络服务的软件(lbsns)已成为研究人类流动性和社交网络分析的主要数据源。在社交网络分析最重要的研究是社交友谊推理,主要目的是利用用户间签到行为的相似性(具有多次共同签到记录)来判断用户间社交好友关系。
2、国际上许多学者和科研机构都已开展基于位置的社交关系推断的研究工作,并提出了多种方法。包括基于手工特征提取方法、基于随机行走的方法、基于时间序列预测方法和基于图网络的方法。这些研究主要集中在基于多次共同签到记录来对社交友谊推断。它们潜在的假设是,多次共同签到的用户更有可能是朋友关系。例如,多次在同一家咖啡馆签到的两个人更可能是朋友,在同一栋大楼里工作的两个人更可能是同事。
3、尽管对基于共同定位的友谊推理进行了大量的研究,但很少有人关注跨区域友谊推理的问题,即推断两个活动轨迹分布在不同区域下、且只有极少共同签到是否是朋友。由于跨区域好友间共同签到记录极少,因此当前已有方法难以获得准确的预测结果。同时,跨区域好友关系推断具有重要实际意义。第一、随着网络技术的发展,真实世界中存在大量跨区域好友,他们活动分布在不同区域,平时沟通主要利用社交网络软件进行联系,很少进行线下共同活动,研究跨区域友谊推荐技术有利于进一步提高好友关系推断的准确度;第二,在许多lbsns的应用程序中,用户为了保护隐私会故意隐藏其签到记录,导致朋友间共同签到记录极其稀疏,区域的友谊推断技术有助于获得更好的朋友推荐。
技术实现思路
1、针对现有技术中存在的缺陷,本发明的目的在于提供一种基于类别感知的跨区域友谊推断方法及系统,推断两个活动轨迹分布在不同区域下、且缺乏共同签到记录是否是朋友,获得较为准确的预测结果。
2、为达到以上目的,一方面,采取一种基于类别感知的跨区域友谊推断方法,包括:
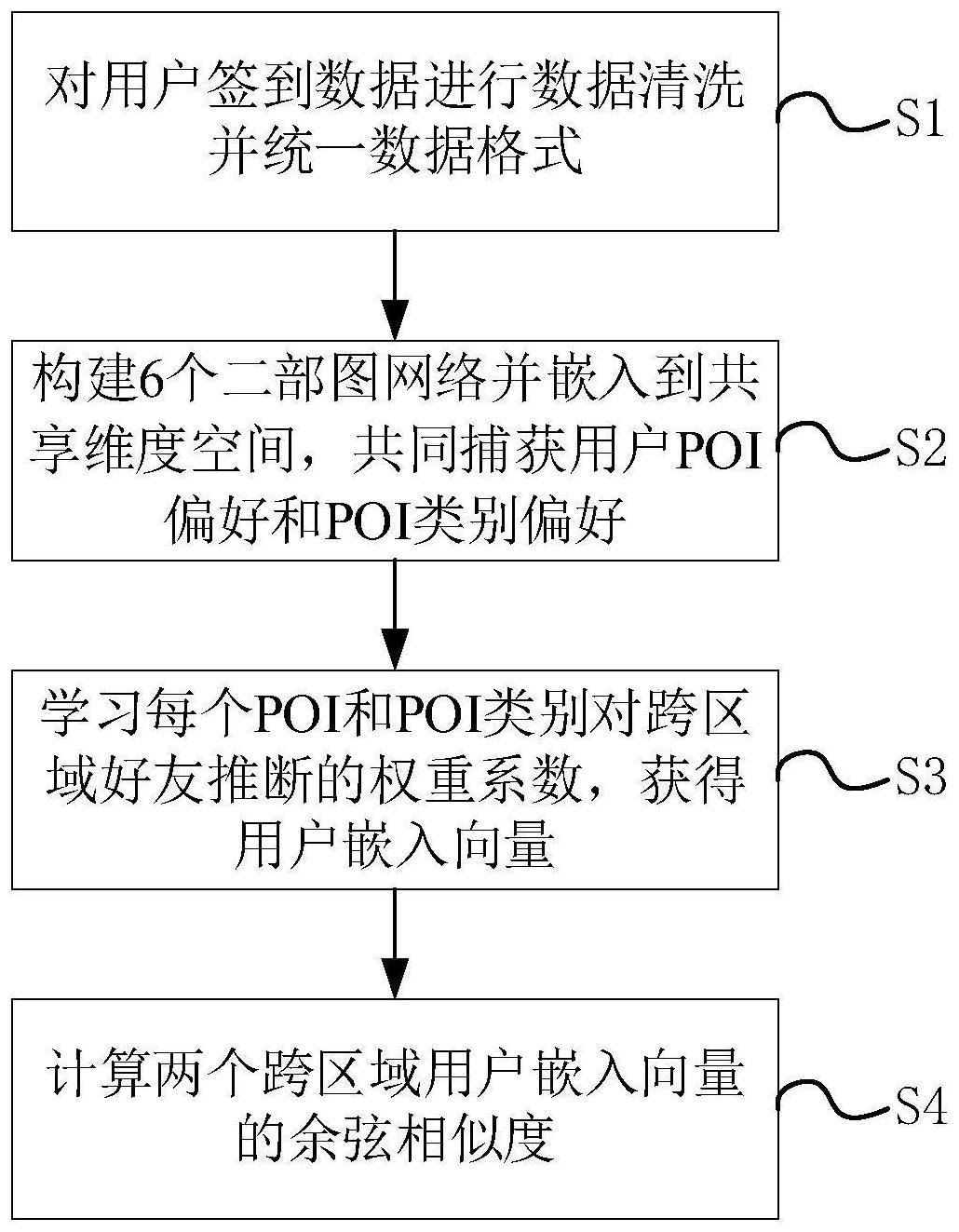
3、s1.对用户签到数据进行数据清洗并统一数据格式;
4、s2.将时间按照每天24个时间段和每周168个时间段进行划分,根据用户历史签到行为中的poi、poi类别和签到时间,构建6个二部图网络并嵌入到共享维度空间,共同捕获用户poi偏好和poi类别偏好;
5、s3.通过类别感知的异构图注意网络,学习每个poi和poi类别对跨区域好友推断的权重系数,获得用户嵌入向量;
6、s4.计算两个跨区域用户嵌入向量的余弦相似度,作为两个跨区域用户好友关系的概率值。
7、优选的,所述步骤s1中的数据清洗包括:滤除签到次数少于预设次数的poi、以及对应的poi类别。
8、优选的,所述步骤s2中,六个二部图网络包括:用户-poi、poi-poi、poi-poi类别、用户-poi类别、poi类别-poi类别和poi类别-签到时间;每个二部图中的权重表示发生此项签到的频率。
9、优选的,所述步骤s2中,六个二部图进行联合图嵌入,依次从每个图中抽取边,再依次进行节点嵌入学习。
10、优选的,每个二部图网络嵌入方法包括:
11、对于任一个二部图网络gab,取两个不同节点vi和vj之间的连边eij,根据连边eij的权重和节点i的度得到经验分布定义节点vi生成节点vj的条件分布p(vj|vi),在二部图网络gab上最小化目标函数并化简,通过引入负采样机制,最终得到损失函数oab;
12、对每个二部图网络进行图嵌入,得到整体损失函数,在整体损失最小时,得出用户、poi、poi类别、以及签到时间的嵌入,分别表示为hu、hl、hc、ht。
13、优选的,用户-poi表示为gul(u∪l,wul),poi-poi表示为gll(l∪l,wll),poi-poi类别表示为glc(l∪c,wlc),用户-poi类别表示为guc(u∪c,wuc),poi类别-poi类别表示为gcc(c∪c,wcc),poi类别-签到时间表示为gct(c∪t,wct);其中,u为用户的向量,l为poi的向量,c为poi类别的向量,t为签到时间的向量,w为对应二部图的连边权重值;gul、gll、glc的构建主要用于捕捉用户的poi偏好,guc、gcc、gct用于捕捉用户poi类别偏好。
14、优选的,所述经验分布表示为:
15、
16、其中,wij表示边eij的权重,deg(i)表示节点i的度;
17、所述条件分布p(vj|vi)表示为:
18、
19、其中,和表示为节点vi和节点vj的嵌入表达向量。
20、优选的,在二部图网络gab上最小化目标函数为:
21、
22、其中,λi表示节点vi的度,d(·,·)表示两个分布的距离;经过化简得到:
23、
24、其中,e表示二部图中边的集合;
25、所述损失函数oab为:
26、
27、其中vk表示为经过负采样得到的负样本,p(v)表示负样本的集合。
28、优选的,所述步骤s3包括,给定直接连接的节点i和节点j以及对应的输入特征hi和hj,节点j对于节点i的归一化权重系数为:
29、
30、其中ni表示与节点i具有直接联系的邻居集合,节点i的最终嵌入输出为:
31、
32、损失函数为:
33、
34、其中,v表示同构邻居节点,w表示异构邻居节点,z表示i负采样节点。λhom、λheter和λneg分别是同构损失、异构损失和负采样损失,损失最小时,得到节点的嵌入向量。
35、优选的,所述s4中,概率值计算方法为:
36、
37、其中和分别为用户i和用户j的嵌入向量。
38、上述技术方案中的一个具有如下有益效果:
39、通过将六个二部图网络嵌入到共享空间中,共同捕获用户的poi偏好和poi类别偏好,然后通过一个异构注意力网络学习每个poi和poi类别对跨区域好友推断贡献权重。
40、针对跨区域好友间缺乏共同签到记录的问题,通过用户-poi、poi-poi、poi-poi类别三个二部图嵌入来建模用户的poi偏好。通过提取签到poi类别将基于签到行为的poi转化到语义空间,挖掘好友间对poi类别的共同偏好。最后通过计算两个用户嵌入向量的相似度作为好友关系预测的概率。
技术特征:
1.一种基于类别感知的跨区域友谊推断方法,其特征在于,包括:
2.如权利要求1所述的基于类别感知的跨区域友谊推断方法,其特征在于,所述s1中的数据清洗包括:滤除签到次数少于预设次数的poi、以及对应的poi类别。
3.如权利要求1所述的基于类别感知的跨区域友谊推断方法,其特征在于,所述s2中,六个二部图网络包括:用户—poi、poi—poi、poi—poi类别、用户—poi类别、poi类别-poi类别和poi类别-签到时间;每个二部图中的权重表示发生此项签到的频率。
4.如权利要求3所述的基于类别感知的跨区域友谊推断方法,其特征在于,所述s2中,六个二部图进行联合图嵌入,依次从每个图中抽取边,再依次进行节点嵌入学习。
5.如权利要求4所述的基于类别感知的跨区域友谊推断方法,其特征在于,每个二部图网络嵌入方法包括:
6.如权利要求5所述的基于类别感知的跨区域友谊推断方法,其特征在于,用户-poi表示为gut(u∪l,wul),poi-poi表示为gll(l∪l,wll),poi-poi类别表示为glc(l∪c,wlc),用户-poi类别表示为guc(u∪c,wuc),poi类别-poi类别表示为gcc(c∪c,wcc),poi类别-签到时间表示为gct(c∪t,wct);其中,u为用户的向量,l为poi的向量,c为poi类别的向量,t为签到时间的向量,w为对应二部图的连边权重值;gul、gll、glc的构建主要用于捕捉用户的poi偏好,guc、gcc、gct用于捕捉用户poi类别偏好。
7.如权利要求6所述的基于类别感知的跨区域友谊推断方法,其特征在于,所述经验分布表示为:
8.如权利要求7所述的基于类别感知的跨区域友谊推断方法,其特征在于,在二部图网络gab上最小化目标函数为:
9.如权利要求5所述的基于类别感知的跨区域友谊推断方法,其特征在于,所述步骤s3包括,给定直接连接的节点i和节点j以及对应的输入特征hi和hj,节点j对于节点i的归一化权重系数为:
10.如权利要求9所述的基于类别感知的跨区域友谊推断方法,其特征在于,所述s4中,概率值计算方法为:
技术总结
一种基于类别感知的跨区域友谊推断方法,涉及跨区域友谊推断领域,以位置社交网络服务数据为基础,通过用户、POI、POI类别和签到时间构建多个二部图网络,并将二部图网络嵌入到一个共享的维度空间中,利用一个异构注意力网络学习每个POI和POI类别的权重系数,并最终计算两个跨区域用户向量表示的相似度,作为此两个用户具有好友关系的概率值,本发明推断两个活动轨迹分布在不同区域下、且缺乏共同签到记录是否是朋友,并获得较为准确的预测结果。
技术研发人员:胡瑞敏,任灵飞,李登实,吴俊杭,臧屹隆,胡文怡,黄子俊,胡津彰
受保护的技术使用者:武汉大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!