一种车载智能助手的控制方法和系统与流程
本发明涉及车载智能助手,具体是一种车载智能助手的控制方法和系统。
背景技术:
1、现有的一些车载智能助手的方案中,对助手形象的设计,要么是自己上传的照片,要么是系统自带的图片,这样就显得要么太正式,要么就千篇一律,没有一点自己的风格。同时,现有的车载智能助手的功能在做场景推荐的时候,为了减少或者增加场景的个数,在很大程度上是需要二次开发的,需要程序员的介入,会增加场景减少或增加的难度。同时,针对智能语音助手,大多数的方案是一种通用的语音方案,没有做到针对车辆的数据的定制化应用。
技术实现思路
1、本发明的目的在于提供一种车载智能助手的控制方法和系统,以解决上述背景技术中提出的问题,具体的,本发明的目的在于解决现有技术中,不能根据用户的喜好,对助手的形象进行个人形象的漫画版处理,以做到用户的个性化形象设置,并且不那么呆板,同时在智能化场景语音推荐方面,改进场景单一化的问题,在增加或者减少场景的过程中,只需要在配置文件里做相应修改。
2、为实现上述目的,本发明提供如下技术方案:
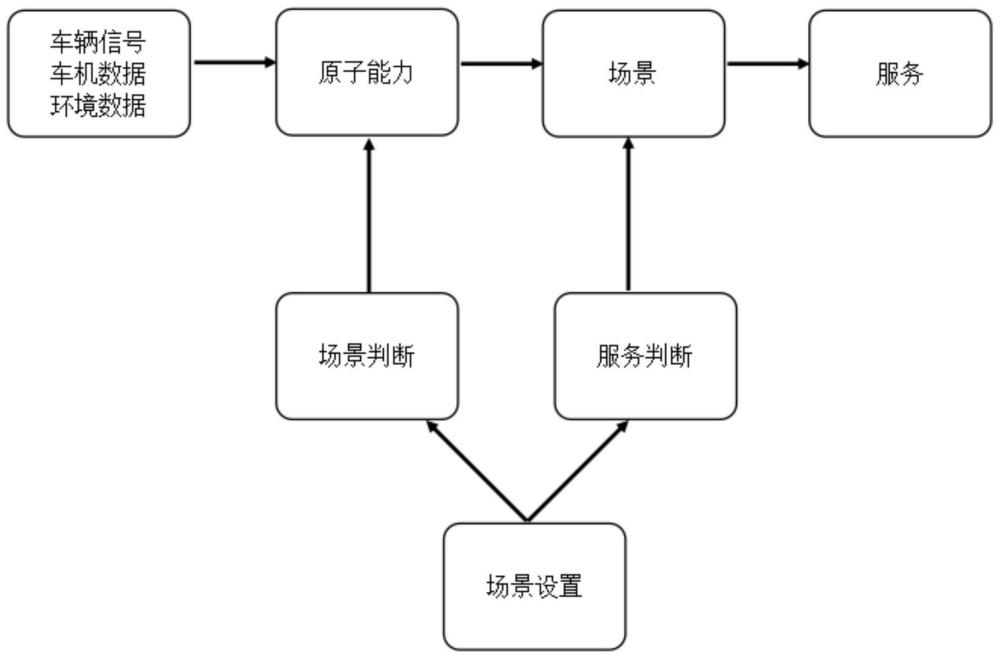
3、第一方面,本发明提供了一种车载智能助手的系统,包括ui展现子系统,场景引擎子系统;其中,所述ui展现子系统用于为用户提供人机交互,并与场景引擎子系统链接;所述场景引擎子系统用于根据预设的场景设置,对用户采集的数据进行判断,通过判断得到的场景,选择合适的服务内容,然后传递给ui展现子系统,为用户提供场景化的服务内容。
4、作为本发明进一步的方案:所述人机交互包括语音交互和通过车机显示屏的图像交互,所述图像交互中包括一个个性化虚拟形象,该虚拟形象以动画的形式通过不同的表情及肢体动作与用户进行信息交互。
5、作为本发明进一步的方案:所述个性化虚拟形象的生成方法包括以下步骤:
6、步骤a:通过三层dcnn网络,识别用户所上传的个人照片中的108个人脸的关键点;
7、步骤b:通过gtn学习几何映射,通过gtn勾勒出夸张的几何线条,并确定五官的几何信息,几何信息被分为三种独立属性,位置、大小和脸型,然后使用三个sub-gan分别进行转换;
8、步骤c:通过atn学习外观映射,通过atn生成所有的面部特征,包括眼睛、鼻子和嘴巴,atn采用multi-gan结构网络,其包含四个局部gan,分别用来转换眼、口、鼻子和头发这四个面部位置;
9、步骤d:融合并根据训练的风格生成五官获得漫画头像,并搭配使用预设的身体形象,以获得一个个性化的虚拟形象。
10、作为本发明进一步的方案:所述场景引擎子系统包括预先设置好一个可以配置的页面,使用场景引擎的人员,只需要按照自己的一些设想,选择出一系列的配置,就能很方便快捷的对场景进行增加或者更改,不需要技术人员的参与。本发明场景引擎最大的好处就是定义了一系列的标准模块,按照标准模块的方式进行设置,这样技术人员只需要增加根据标准来对模块的原子能力进行扩展,然后把原子能力同步到配置库中,非技术人员(主要是指产品经理和运营相关人员)可以根据原子能力组合成相应的场景能力,对用户提供场景化的服务。
11、第一方面,本发明提供了一种车载智能助手的控制方法,包括以下步骤:
12、步骤一:场景引擎设置,按照希望对用户的服务来设置场景引擎;
13、步骤二:具体原子能力的计算,车辆在行驶过程中,实时的根据车辆的相关数据、车机终端的相关数据、环境相关数据来计算出车辆触发了哪些原子能力;
14、步骤三:根据场景引擎中设置的原子能力组合判断是否触发某一场景,当场景引擎设置中的组合里的每一项原子能力都满足时,就可以出发某一场景;
15、步骤四:根据场景引擎设置中的场景出发以及对应的服务内容,为用户提供服务。
16、作为本发明再进一步的方案:步骤四中,为用户提供的服务包括三种类型,类型一:通过车机向用户发送语音及图像提醒,所提醒的内容如超速提醒、加油站提醒、服务区提醒等。类型二:将用户所需的信息以图像形式进行显示,并同时进行语音播报,如语音唤醒智能助手后问一下天气状况,会将天气信息直接展示到车机终端上,同时语音播报。类型三:通过语音控制车载设备,如语音控制车载空调温度、开关窗等。
17、与现有技术相比,本发明的有益效果是:
18、本发明通过ui展现子系统的设置,能够根据用户所上传的照片,生成个性化虚拟形象,并且根据设置的表情以及服饰,可以给出不同场景下的不同的虚拟形象,同时根据不同的场景服务内容的不同,会产生不同表情的虚拟形象,通过场景引擎子系统的设置,可以很方便的增加或者删除场景以及在相应场景下的场景服务。
技术特征:
1.一种车载智能助手的系统,其特征在于:包括ui展现子系统,场景引擎子系统;其中,所述ui展现子系统用于为用户提供人机交互,并与场景引擎子系统链接;所述场景引擎子系统用于根据预设的场景设置,对用户采集的数据进行判断,通过判断得到的场景,选择合适的服务内容,然后传递给ui展现子系统,为用户提供场景化的服务内容。
2.根据权利要求1所述的一种车载智能助手的系统,其特征在于:所述人机交互包括语音交互和通过车机显示屏的图像交互,所述图像交互中包括一个个性化虚拟形象,该虚拟形象以动画的形式通过不同的表情及肢体动作与用户进行信息交互。
3.根据权利要求2所述的一种车载智能助手的系统,其特征在于:所述个性化虚拟形象的生成方法包括以下步骤:
4.根据权利要求1所述的一种车载智能助手的系统,其特征在于:所述场景引擎子系统包括可配置页面,所述可配置页面包含若干个标准模块。
5.一种车载智能助手的控制方法,其特征在于:包括以下步骤:
6.根据权利要求1所述的一种车载智能助手的控制方法,其特征在于:步骤四中,为用户提供的服务包括三种类型,类型一:通过车机向用户发送语音及图像提醒。类型二:将用户所需的信息以图像形式进行显示,并同时进行语音播报。类型三:通过语音控制车载设备。
技术总结
本发明公开了一种车载智能助手的控制方法和系统,第一方面,本发明提供了一种车载智能助手的系统,包括UI展现子系统,场景引擎子系统;其中,所述UI展现子系统用于为用户提供人机交互,并与场景引擎子系统链接;所述场景引擎子系统用于根据预设的场景设置,对用户采集的数据进行判断,通过判断得到的场景,选择合适的服务内容;本发明通过UI展现子系统的设置,能够根据用户所上传的照片,生成个性化虚拟形象,并且根据设置的表情以及服饰,可以给出不同场景下的不同的虚拟形象,同时根据不同的场景服务内容的不同,会产生不同表情的虚拟形象,通过场景引擎子系统的设置,可以很方便的增加或者删除场景以及在相应场景下的场景服务。
技术研发人员:卜园渊,梁龑,李凯,郭浩浩
受保护的技术使用者:上海翌擎智能科技有限公司
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!