一种基于人群差异的人脸识别方法与流程
本申请属于人脸识别,更具体地说,是涉及一种基于人群差异的人脸识别方法。
背景技术:
1、因为深度学习的快速发展,人脸识别也得到了快速的发展,精度和速度均得到非常大的提升。现有人脸识别技术主要分为两类,第一类是基于传统的手动设计的人脸特征,得到人脸识别的结果;第二类方法则是基于深度学习自动提取特征,将训练数据中自动提取的特征,训练得到人脸识别模型。这两类方法一般都用于进行通用型的人脸识别。
2、然而,在人脸识别的应用中,人脸数据起着决定性的作用。因为大量的数据来自公开数据集,数据的分布往往很不平衡,例如大多数公开数据集都是西方人脸,且大多数是中青年。这会导致训练出来的人脸识别模型在分布较少的数据类别,如东方人脸,小孩或老人,人群识别效果较差。无论是早期的传统方法还是最新的深度学习提取人脸特征,由于针对的是大范围人群,其训练数据的分布决定了模型对不同人群的识别效果;例如,因为分布集中在中青年,训练得到的模型在老人和小孩人群中的人脸识别效果并不好;这种人群差异情况不仅体现在年龄中,也体现在地理人种中。
技术实现思路
1、本申请实施例的目的在于提供一种基于人群差异的人脸识别方法,以解决现有技术在人脸识别过程中存在的因数据的分布不平衡引起的部分人群的人脸识别准确率低的技术问题。
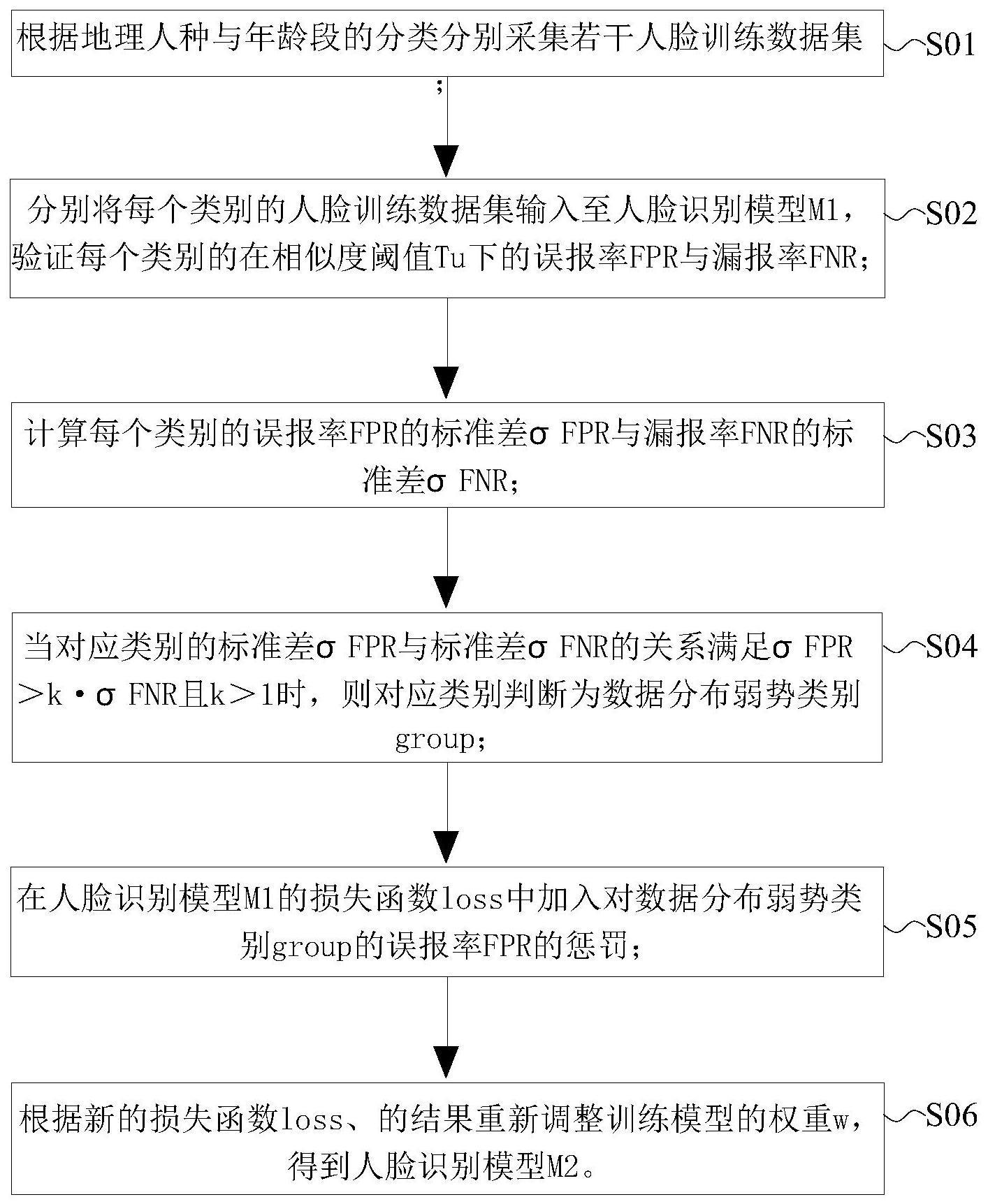
2、为实现上述目的,本申请采用的技术方案是:提供一种基于人群差异的人脸识别方法,包括:
3、步骤s01,根据地理人种与年龄段的分类分别采集若干人脸训练数据集;
4、步骤s02,分别将每个类别的人脸训练数据集输入至人脸识别模型m1,验证每个类别的在相似度阈值tu下的误报率fpr与漏报率fnr;
5、步骤s03,计算每个类别的误报率fpr的标准差σfpr与漏报率fnr的标准差σfnr;
6、步骤s04,当对应类别的标准差σfpr与标准差σfnr的关系满足σfpr>k·σfnr且k>1时,则对应类别判断为数据分布弱势类别group;
7、步骤s05,在人脸识别模型m1的损失函数loss中加入对数据分布弱势类别group的误报率fpr的惩罚;
8、步骤s06,根据新的损失函数loss、的结果重新调整训练模型的权重w,得到人脸识别模型m2。
9、优选地,在步骤s01中,根据地理人种可以分为非洲地理人种、亚洲地理人种、欧洲地理人种以及印第安地理人种,按照年龄段可以分为幼年、少年、青年以及老年。
10、优选地,在步骤s01中,非洲地理人种、亚洲地理人种、欧洲地理人种以及印第安地理人种的人脸训练数据集的数量相同;幼年、少年、青年以及老年的人脸训练数据集的数量相同。
11、优选地,在步骤s02中,所述误报率fpr是被错误报告为阳性的阴性情况的比例,误报率fpr的计算公式为:
12、
13、其中,fp是被模型预测为正类的负样本,tn是被模型预测为负类的负样本;
14、优选地,所述漏报率fnr是被错误地报道为阴性的阳性情况的比例,漏报率fnr的计算公式为:
15、
16、其中,fn是被模型预测为负类的正样本,tp是被模型预测为正类的正样本。
17、优选地,在步骤s02中,人脸识别模型m1在验证每个类别的误报率fpr与漏报率fnr时,相似度阈值tu为满足0.2≤tu≤0.4。
18、优选地,在步骤s04中,当对应类别的标准差σfpr与标准差σfnr的关系满足σfpr>k·σfnr且k>5时,则对应类别判断为数据分布弱势类别group。
19、优选地,在步骤s04中,当对应类别的标准差σfpr与标准差σfnr的关系不满足σfpr>k·σfnr且k>5时,则对应类别的图像数据用人脸识别模型m1识别。
20、优选地,所述人脸识别模型m1为以resnet50为backbone且以arcface为损失函数loss的识别模型。
21、优选地,在步骤s05中,在人脸识别模型m1的损失函数loss中加入对数据分布弱势类别group的误报率fpr的惩罚的方法包括以下步骤:
22、定义arcface的损失函数loss为:
23、
24、其中,n为样本的数量,θ是输入的特征x和权重w两个向量之间的夹角,s为超参数代表特征的缩放,m为超参数代表角度的变化;
25、通过fpr的定义,记录满足误识别的情况cosθj>tu,则满足:
26、
27、将fpr引入到arcface的损失函数loss中,则:
28、
29、其中,α为缩放系数,将γi缩放至与角度θ同范围之内。
30、本申请提供的基于人群差异的人脸识别方法,与现有技术相比,根据地理人种与年龄段的分类,验证每个类别的在不同相似度阈值tu下的误报率fpr与漏报率fnr,通过判断对应类别的标准差σfpr与标准差σfnr的关系,精准筛选出数据分布弱势类别group;然后在人脸识别模型m1的损失函数loss中加入对数据分布弱势类别group的误报率fpr的惩罚,加入到总的损失函数中,解决因人脸数据分布不均匀而引起的部分人群的人脸识别准确率低的技术问题。
技术特征:
1.一种基于人群差异的人脸识别方法,其特征在于,包括:
2.如权利要求1所述的基于人群差异的人脸识别方法,其特征在于,在步骤s01中,根据地理人种分为非洲地理人种、亚洲地理人种、欧洲地理人种以及印第安地理人种,按照年龄段可以分为幼年、少年、青年以及老年。
3.如权利要求2所述的基于人群差异的人脸识别方法,其特征在于,在步骤s01中,非洲地理人种、亚洲地理人种、欧洲地理人种以及印第安地理人种的人脸训练数据集的数量相同;幼年、少年、青年以及老年的人脸训练数据集的数量相同。
4.如权利要求1所述的基于人群差异的人脸识别方法,其特征在于,在步骤s02中,所述误报率fpr是被错误报告为阳性的阴性情况的比例,误报率fpr的计算公式为:
5.如权利要求4所述的基于人群差异的人脸识别方法,其特征在于,所述漏报率fnr是被错误地报道为阴性的阳性情况的比例,漏报率fnr的计算公式为:
6.如权利要求5所述的基于人群差异的人脸识别方法,其特征在于,在步骤s02中,人脸识别模型m1在验证每个类别的误报率fpr与漏报率fnr时,相似度阈值tu为满足0.2≤tu≤0.4。
7.如权利要求6所述的基于人群差异的人脸识别方法,其特征在于,在步骤s04中,当对应类别的标准差σfpr与标准差σfnr的关系满足σfpr>k·σfnr且k>5时,则对应类别判断为数据分布弱势类别group。
8.如权利要求7所述的基于人群差异的人脸识别方法,其特征在于,在步骤s04中,当对应类别的标准差σfpr与标准差σfnr的关系不满足σfpr>k·σfnr且k>5时,则对应类别的图像数据用人脸识别模型m1识别。
9.如权利要求1至8任意一项所述的基于人群差异的人脸识别方法,其特征在于,所述人脸识别模型m1为以resnet50为backbone且以arcface为损失函数loss的识别模型。
10.如权利要求9所述的基于人群差异的人脸识别方法,其特征在于,在步骤s05中,在人脸识别模型m1的损失函数loss中加入对数据分布弱势类别group的误报率fpr的惩罚的方法包括以下步骤:
技术总结
本申请提供了一种基于人群差异的人脸识别方法,包括:根据地理人种与年龄段的分类分别采集若干人脸训练数据集;分别将每个类别的人脸训练数据集输入至人脸识别模型M<subgt;1</subgt;,验证每个类别的在相似度阈值T<subgt;u</subgt;下的误报率FPR与漏报率FNR;计算每个类别的误报率FPR的标准差σ<subgt;FPR</subgt;与漏报率FNR的标准差σ<subgt;FNR</subgt;;当对应类别的标准差σ<subgt;FPR</subgt;与标准差σ<subgt;FNR</subgt;的关系满足σ<subgt;FPR</subgt;>k·σ<subgt;FNR</subgt;且k>1时,则对应类别判断为数据分布弱势类别group;在人脸识别模型M<subgt;1</subgt;的损失函数loss中加入对数据分布弱势类别group的误报率FPR的惩罚;根据新的损失函数loss<supgt;、</supgt;的结果重新调整训练模型的权重w,得到人脸识别模型M<subgt;2</subgt;;本申请的解决了因人脸数据分布不均匀而引起的部分人群的人脸识别准确率低的技术问题。
技术研发人员:欧阳一村,王和平,洪志阳,付磊,陈海涛,李希,朱光强,赖时伍
受保护的技术使用者:盛视科技股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!