文本处理模型的训练方法、文本处理方法及相关设备与流程
本申请涉及自然语言处理,尤其涉及一种文本处理模型的训练方法、文本处理方法及相关设备。
背景技术:
1、数据增强是一种提升模型泛化能力和数据有效性的有效策略。在自然语言处理(natural language processing,nlp)领域,数据增强的目的是在不改变语义的前提下扩充文本数据。
2、目前在nlp场景下,通常对样本文本中表示实体的词语替换为同义词或者表示相同类型实体的词语,得到对应的增强文本,然后利用样本文本及其对应的增强文本训练相应的文本处理模型。但是,这种方式得到的增强文本较为片面,甚至与样本文本的语义相去甚远,并不能很好地提升文本处理模型的训练效果,进而影响文本处理模型的准确性和泛化能力。
技术实现思路
1、本申请实施例的目的提供一种文本处理模型的训练方法、文本处理方法及相关设备,用于解决目前在文本处理模型的训练过程中获得的增强文本片面而导致训练出的文本处理模型的准确性和泛化能力不佳的问题。
2、为了实现上述目的,本申请实施例采用下述技术方案:
3、第一方面,本申请实施例提供一种文本处理模型的训练方法,包括:
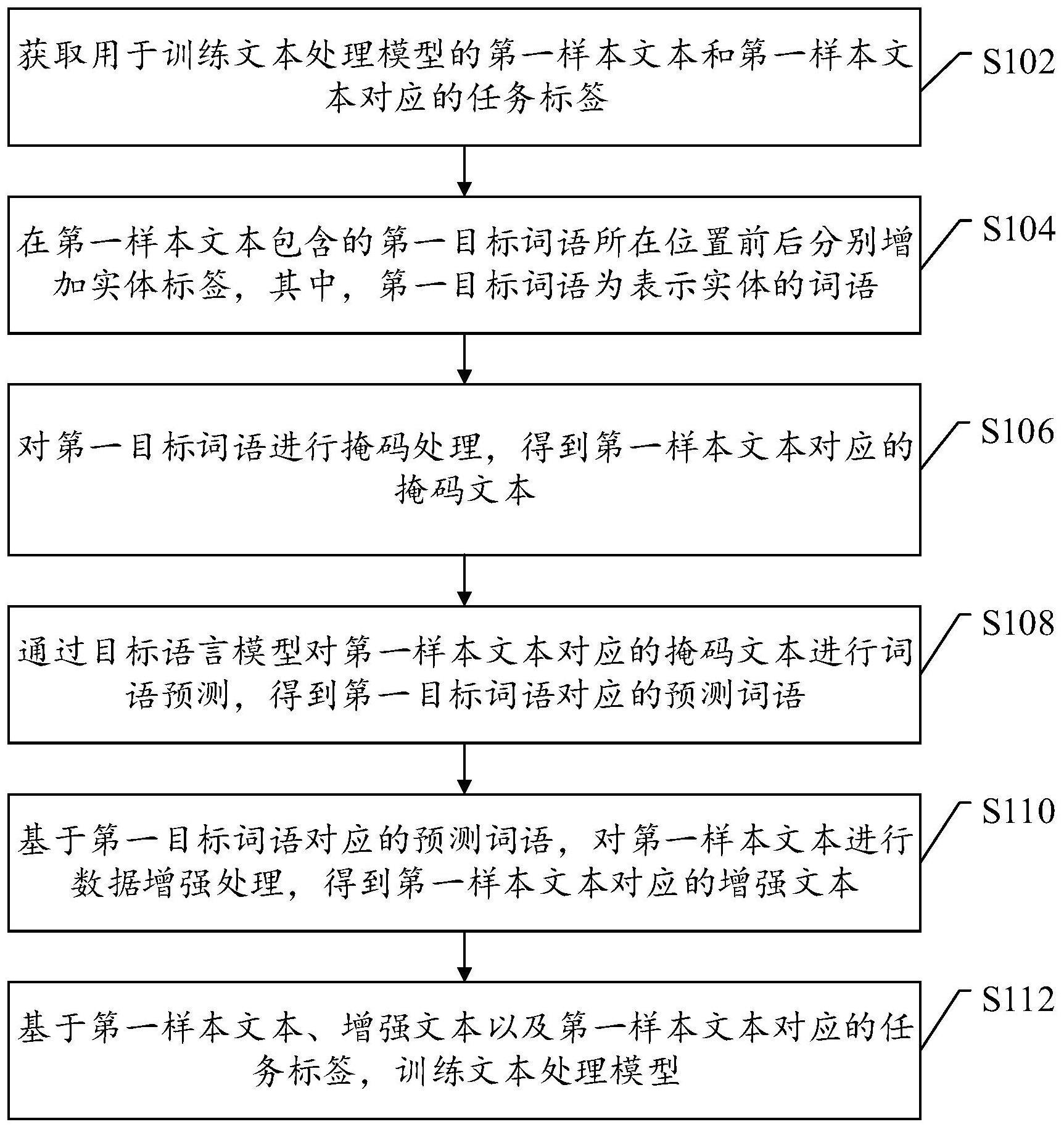
4、获取用于训练文本处理模型的第一样本文本和所述第一样本文本对应的任务标签,所述任务标签用于表示所述第一样本文本在目标文本处理任务下对应的目标处理结果;
5、在第一样本文本包含的第一目标词语所在位置前后分别增加实体标签,所述第一目标词语为表示实体的词语;
6、对所述第一目标词语进行掩码处理,得到所述第一样本文本对应的掩码文本;
7、通过目标语言模型对所述第一样本文本对应的掩码文本进行词语预测,得到所述第一目标词语对应的预测词语;
8、基于所述第一目标词语对应的预测词语,对所述第一样本文本进行数据增强处理,得到所述第一样本文本对应的增强文本;
9、基于所述第一样本文本、所述增强文本以及所述第一样本文本对应的任务标签,训练所述文本处理模型。
10、本申请实施例提供的文本处理模型的训练方法,利用目标语言模型的语义理解和词语预测能力,通过对用于训练文本处理模型的第一样本文本中表示实体的第一目标词语进行掩码处理,由目标语言模型基于掩码处理后所的掩码文本(也即目标词语的上下文)对第一目标词语进行语义理解后,对该掩码文本进行词语预测,也即预测第一目标词语所在位置处可能的词语,所得的预测词语更丰富,且能够较好地切合第一目标词语在其所属的第一样本文本中的语义;进一步,基于第一目标词语所在位置对应的预测词语,对第一样本文本进行数据增强处理,得到的增强文本更全面、且能够更好地切合第一样本文本的语义,在第一样本文本的基础上结合这类增强文本训练文本处理模型,有利于提升文本处理模型的训练效果,从而提高文本处理模型的准确性和泛化能力;在此基础上,通过在第一样本文本中第一目标词语所在位置前后分别增加实体标签,可以确保第一目标词语与实体标签相匹配,使得第一目标语言模型能够更加容易学习和掌握第一目标词语的边界信息,有利于目标语言模型更加准确地理解掩码文本的语义而能够更准确地对第一目标词语所在位置进行词语预测,得到的预测词语能够更好地切合第一目标词语在第一样本文本中的语义,从而有利于提高增强文本的全面性及其与第一样本文本的语义的切合度。
11、第二方面,本申请实施例提供一种文本处理方法,包括:
12、获取待处理文本;
13、通过文本处理模型对所述待处理文本执行目标文本处理任务,得到所述待处理文本对应的文本处理结果;其中,所述文本处理模型为基于第一方面所述的训练方法训练得到。
14、本申请实施例提供的文本处理方法,由于本申请实施例的文本处理模型的训练方法训练得到的文本处理模型具有较高的准确性和较优的泛化能力,利用该文本处理模型对待处理文本进行处理,有利于提高文本处理准确性。
15、第三方面,本申请实施例提供一种文本处理模型的训练装置,包括:
16、获取单元,用于获取用于训练文本处理模型的第一样本文本和所述第一样本文本对应的任务标签,所述任务标签用于表示所述第一样本文本在目标文本处理任务下对应的目标处理结果;
17、文本处理单元,用于在第一样本文本包含的第一目标词语所在位置前后分别增加实体标签,所述第一目标词语为表示实体的词语;
18、所述文本处理单元,还用于对所述第一目标词语进行掩码处理,得到所述第一样本文本对应的掩码文本;
19、预测单元,用于通过目标语言模型对所述第一样本文本对应的掩码文本进行词语预测,得到所述第一目标词语对应的预测词语;
20、数据增强单元,用于基于所述第一目标词语对应的预测词语,对所述第一样本文本进行数据增强处理,得到所述第一样本文本对应的增强文本;
21、训练单元,基于所述第一样本文本、所述增强文本以及所述第一样本文本对应的任务标签,训练用于执行目标文本处理任务的文本处理模型,其中,所述任务标签用于表示所述第一样本文本在所述目标文本处理任务下对应的目标处理结果。
22、第四方面,本申请实施例提供一种文本处理装置,包括:
23、获取单元,用于获取待处理文本;
24、任务执行单元,用于通过文本处理模型对所述待处理文本执行目标文本处理任务,得到所述待处理文本对应的文本处理结果;其中,所述文本处理模型为基于第一方面所述的训练方法训练得到。
25、第五方面,本申请实施例提供一种电子设备,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现如第一方面所述的方法;或者,所述处理器被配置为执行所述指令,以实现如第二方面所述的方法。
26、第六方面,本申请实施例提供一种计算机可读存储介质,当所述存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行如第一方面所述的方法;或者,使得电子设备能够执行如第二方面所述的方法。
技术特征:
1.一种文本处理模型的训练方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述在第一样本文本包含的第一目标词语所在位置前后分别增加实体标签,包括:
3.根据权利要求1所述的方法,其特征在于,所述基于所述第一目标词语对应的预测词语,对所述第一样本文本进行数据增强处理,得到所述第一样本文本对应的增强文本,包括:
4.根据权利要求1所述的方法,其特征在于,在所述在第一样本文本包含的第一目标词语所在位置前后分别增加实体标签之前,所述方法还包括:
5.根据权利要求4所述的方法,其特征在于,在基于所述候选词语在所述第一样本文本中的上下文信息,对所述实体识别结果进行正确性校验之后,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,在通过目标语言模型对所述掩码文本中所述第一目标词语进行词语预测之前,所述方法还包括:
7.根据权利要求6所述的方法,其特征在于,所述在第二样本文本i包含的第二目标词语所在位置前后分别增加实体标签,包括:
8.根据权利要求6所述的方法,其特征在于,所述基于所述样本集中每个第二样本文本包含的第二目标词语以及所述第二目标词语对应的预测词语,调整所述待训练的语言模型的模型参数,包括:
9.根据权利要求8所述的方法,其特征在于,若所述第二样本文本i包含多个第二目标词语,则所述基于所述第二样本文本i包含的第二目标词语以及所述第二目标词语对应的预测词语,确定所述第二样本文本i对应的预测条件概率,包括:
10.根据权利要求1-9中任一项所述的方法,其特征在于,所述基于所述第一样本文本、所述增强文本以及所述第一样本文本对应的任务标签,训练所述文本处理模型,包括:
11.一种文本处理方法,其特征在于,包括:
12.一种文本处理模型的训练装置,其特征在于,包括:
13.一种文本处理装置,其特征在于,包括:
14.一种电子设备,其特征在于,包括:
15.一种计算机可读存储介质,其特征在于,当所述存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行如权利要求1-10中任一项所述的方法;或者,使得电子设备能够执行如权利要11所述的方法。
技术总结
本申请公开了一种文本处理模型的训练方法、文本处理方法及相关设备,所述训练方法包括:获取第一样本文本及其对应的任务标签,任务标签用于表示第一样本文本在目标文本处理任务下对应的目标处理结果;在第一样本文本包含的第一目标词语所在位置前后分别增加实体标签,第一目标词语为表示实体的词语;对第一目标词语进行掩码处理,得到样本文本对应的掩码文本;通过目标语言模型对样本文本对应的掩码文本进行词语预测,得到第一目标词语对应的预测词语;基于第一目标词语对应的预测词语,对第一样本文本进行数据增强处理,得到第一样本文本对应的增强文本;基于第一样本文本及其对应的增强文本及任务标签,训练文本处理模型。
技术研发人员:杨森,蒋宁,肖冰,李宽
受保护的技术使用者:马上消费金融股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!