一种汽车座舱的音乐交互方法与流程
1.本发明属于人车交互技术领域,具体涉及一种汽车座舱的音乐交互方法。
背景技术:
2.当今智能网联汽车媒体播放器已经成为车辆标配,通常人们播放音乐时仅会通过车机系统将音乐播放出来,用户处于被动收音状态。用户仅能单方面接收音乐播放器播放的音乐,不能通过面部表情、手势动作,身体姿态等行为和音乐进行互动,缺乏了人车交互的乐趣。
技术实现要素:
3.鉴于以上所述现有技术的缺点,本发明的目的在于提供一种视觉识别手段,识别用户的面部属性,如视线方向,面部表情,眉毛动作等,手臂方位,手掌动作等,增强用户同座舱的互动。
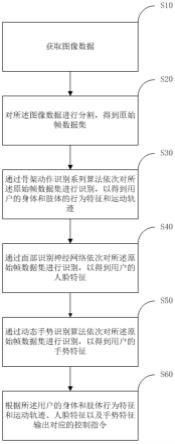
4.为实现上述目的及其他相关目的,本发明提供一种汽车座舱的音乐交互方法,应用于车载终端,所述汽车座舱的音乐交互方法包括:获取图像数据;对所述图像数据进行分割,得到原始帧数据集;通过骨架动作识别系列算法依次对所述原始帧数据集进行识别,以得到用户的身体和肢体的行为特征和运动轨迹;通过面部识别神经网络依次对所述原始帧数据集进行识别,以得到用户的人脸特征;通过动态手势识别算法依次对所述原始帧数据集进行识别,以得到用户的手势特征;根据所述用户的身体和肢体行为特征和运动轨迹、人脸特征以及手势特征输出对应的音乐控制指令。
5.根据本发明一具体实施例,所述通过骨架动作识别系列算法依次对所述原始帧数据集进行识别,以得到用户的身体和肢体的行为特征和运动轨迹的步骤包括:通过所述骨架动作识别系列算法中的2d动作识别算法依次对所述原始帧数据集进行提取,得到每一帧人像数据的2d动作信息和平面坐标;整合所有所述2d动作信息并将其输入到所述骨架动作识别系列算法中的3d动作识别网络中,得到所述用户的身体和肢体的行为特征;整合所有所述平面坐标,并根据所述原始帧数据集中的环境数据得到所述用户的身体和肢体的运动轨迹。
6.根据本发明一具体实施例,所述通过所述骨架动作识别系列算法中的2d动作识别算法依次对所述原始帧数据集进行提取,得到每一帧人像数据的2d动作信息和平面坐标的步骤包括:将所述原始帧数据集输入至训练好的hrnet网络中,得到人像数据的骨骼关键点以及平面坐标;通过st-gcn神经网络对所述骨骼的关键点关联并识别,得到对应的2d动作信息。
7.根据本发明一具体实施例,所述整合所有所述2d动作信息并将其输入到所述骨架动作识别系列算法中的3d动作识别网络中,得到所述用户的身体和肢体的行为特征的步骤包括:将所述2d动作信息输入至posec3d或3d-cnn模型中识别,得到用户的身体和肢体行为特征。
8.根据本发明一具体实施例,所述整合所有所述平面坐标,并根据所述原始帧数据集中的环境数据得到所述用户的身体和肢体的运动轨迹的步骤包括:根据所述原始帧数据集中的环境数据与实时环境信息生成环境3d模型;通过所述环境3d模型将所述平面坐标转换成空间坐标;整合所有所述空间坐标得到所述用户的身体和肢体的运动轨迹。
9.根据本发明一具体实施例,所述面部识别神经网络采用alexnet卷积神经网络。
10.根据本发明一具体实施例,所述通过动态手势识别算法依次对所述原始帧数据集进行识别,以得到用户的手势特征的步骤包括:根据用户的肤色分离干扰信息,得到用户皮肤裸露部分的特征数据;通过形态学灰度运算抹除所述特征数据中面部特征,得到中间特征数据;通过基于标记的分水岭分隔算法和八连通种子填充算法对所述中间特征数据进行分割,得到目标特征数据即手势信息;将所述目标特征数据输入至预设好的手势模型中识别,得到所述用户的手势特征。
11.一种汽车座舱的音乐交互系统,包括:信息采集模块,用于获取图像数据;信息处理模块,用于对所述图像数据进行分割,得到原始帧数据集;第一信息识别模块,用于通过骨架动作识别系列算法依次对所述原始帧数据集进行识别,以得到用户的身体和肢体的行为特征和运动轨迹;第二信息识别模块,用于通过面部识别神经网络依次对所述原始帧数据集进行识别,以得到用户的人脸特征;第三信息识别模块,用于通过动态手势识别算法依次对所述原始帧数据集进行识别,以得到用户的手势特征;信息反馈模块,用于根据所述用户的身体和肢体行为特征和运动轨迹、人脸特征以及手势特征输出对应的音乐控制指令。
12.一种汽车座舱的音乐交互设备,包括处理器,所述处理器与存储器耦合,所述存储器存储有程序指令,当所述存储器存储的程序指令被所述处理器执行时实现上述任一项所述的一种汽车座舱的音乐交互方法。
13.一种计算机可读存储介质,包括程序,当所述程序在计算机上运行时,使得计算机执行如上述任一项所述的汽车座舱的音乐交互方法。
14.本发明的技术效果在于,通过视觉手段识别汽车座舱内的用户的行为特征、人脸特征、手势特征以及和车辆的交流互动,控制车载音乐播放器、氛围灯或视频播放器给予相应的反馈,形成用户与音乐之间的互动,增强趣味性,提高用户的乘车体验感。
附图说明
15.图1为本发明所提供的一种汽车座舱的音乐交互方法一具体实施例的流程示意图;
16.图2为本发明所提供的一种汽车座舱的音乐交互系统一具体实施例的流程示意图;
17.图3为本发明所提供的一种汽车座舱的音乐交互设备一具体实施例的结构示意图。
具体实施方式
18.以下将参照附图和优选实施例来说明本发明的实施方式,本领域技术人员可由本说明书中所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在
没有背离本发明的精神下进行各种修饰或改变。应当理解,优选实施例仅为了说明本发明,而不是为了限制本发明的保护范围。
19.需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
20.在下文描述中,探讨了大量细节,以提供对本发明实施例的更透彻的解释,然而,对本领域技术人员来说,可以在没有这些具体细节的情况下实施本发明的实施例是显而易见的,在其他实施例中,以方框图的形式而不是以细节的形式来示出公知的结构和设备,以避免使本发明的实施例难以理解。
21.首先需要说明的是,当今车辆基本都配置有音乐播放器,且交互技术的更新迭代,然而用户仅能单方面接收车载音乐播放器播放的音乐,并不能与音乐进行互动,导致用户乘车体验感较差。本技术通过将人车交互技术应用在该领域,通过视觉手段,识别用户的面部表情、视线方向、手势动作、身体姿态等用户的身体行为特征,播放对应设置好的音乐或特效,从而实现用户与音乐之间的互动,增强趣味性,提高用户的乘车体验感。
22.为了使本技术领域的人员能够更好地理解本技术方案,对本技术实施例中的技术方案进行清楚、完整的描述。
23.本技术的系统架构可以为本地端设备,所述本地端设备包括:车载rgb和rgbir摄像头,或者景深摄像头,车载音乐播放器,车载视频播放器、氛围灯(车载led灯)以及车载终端。车载终端与车载rgb和rgbir摄像头,或者景深摄像头,车载音乐播放器,车载视频播放器以及车载led灯直接通过网络连接,既可以采用有线通信连接,也可以采用无线通信连接。
24.汽车座舱内的用户的面部表情、视线方向、手势动作、身体姿态等身体行为特征被摄像头捕捉采集,上传至车载终端进行识别,识别完成后车载终端输出控制指令,控制车机发声或控制车载音乐播放器、车载视频播放器以及氛围灯(车载led灯)做出相应的反应,以配合用户的身体行为特征,从而实现用户与音乐之间的交流互动。
25.需要说明的是,本技术实施例所提供的汽车座舱的音乐交互方法一般由车载终端执行,相应的,交互设备以及介质一般设置在车载终端中。
26.实施例1
27.请参见图1所示,一种汽车座舱的音乐交互方法,应用于车载终端,所述汽车座舱的音乐交互方法包括:
28.步骤s10,获取图像数据。
29.具体的,通过车载rgb和rgbir摄像头捕捉采集用户的身体行为特征的图像数据,所述图像数据包括图片数据和视频数据;若采集的图像数据为视频数据,则执行步骤s20,先对图像数据预处理,再进行识别;若采集的图像数据为图片数据,则跳过步骤s20,直接进入图像识别。
30.其中,所述图像数据的特征信息包括人像数据和环境数据,人像数据为用户的面部表情、视线方向、手势动作、身体姿态等身体行为特征;环境数据为当前用户所处空间的位置信息,以及周边物品器件的状态信息。
31.步骤s20,对所述图像数据进行分割,得到原始帧数据集。
32.具体的,将采集的视频数据分割成若干个连续帧,并作为原始帧数据集。通过对每一帧进行识别,从而具体分析用户的身体行为特征,并输出正确的控制指令。
33.步骤s30,通过骨架动作识别系列算法依次对所述原始帧数据集进行识别,以得到用户的身体和肢体的行为特征和运动轨迹。
34.其中,分析所述图像数据中的人像数据中的骨骼关键点的分布以及变化,从而获取用户的身体和肢体的行为特征;通过所述图像数据中的环境数据并结合实时环境信息,分析得到用户的身体和肢体的运动轨迹。进一步的,根据用户的身体和肢体的运动轨迹结合实时环境信息,判断得到用户与周边环境的交互状态。具体的,在应用中,用户的手臂上下反复摆动并拍击方向盘,识别用户肢体的骨骼关键点,并根据若干个同一骨骼关键点的变化情况,分析得到用户的身体和肢体行为特征为摆动手臂,并根据图像数据中的环境数据与实时环境相匹配,判断得到用户所处环境以及周边状态信息的3d模型,再根据得到的用户的身体和肢体的运动轨迹的起点、中点、落点等结合3d模型,分析得到用户此时正在通过摆动手臂拍击方向盘。此时输出与行为特征相对应的音乐、视频、氛围灯效等,或者输出预设好的拍击方向盘指令对应的音乐、视频、氛围灯效等,完成用户与音乐的交互。
35.具体的识别步骤包括:
36.步骤s31,通过所述骨架动作识别系列算法中的2d动作识别算法依次对所述原始帧数据集进行提取,得到每一帧人像数据的2d动作信息和平面坐标。
37.步骤s32,整合所有所述2d动作信息并将其输入到所述骨架动作识别系列算法中的3d动作识别网络中,得到所述用户的身体和肢体的行为特征。
38.步骤s33,整合所有所述平面坐标,并根据所述原始帧数据集中的环境数据得到所述用户的身体和肢体的运动轨迹。
39.其中,通过依次对图像数据的每一帧识别分析当前帧的身体和肢体动作,再串联所有连续帧识别分析一连串动作对应的行为特征。因此,首先通过骨架动作识别系列算法中的2d动作识别算法对每一帧进行识别,再通过骨架动作识别系列算法中的3d动作识别网络关联所有2d的动作信息生成3d的行为特征并识别。同时也将2d平面坐标生成3d空间坐标,分析运动轨迹。
40.进一步的,所述通过所述骨架动作识别系列算法中的2d动作识别算法依次对所述原始帧数据集进行提取,得到每一帧人像数据的2d动作信息和平面坐标的步骤包括:
41.步骤s311,将所述原始帧数据集输入至训练好的hrnet网络中,得到人像数据的骨骼关键点以及平面坐标。
42.其中,高分辨率网络hrnet(high-resolution net)是针对2d人体姿态估计(human pose estimation或keypoint detection)任务提出的,并且该网络主要是针对单一个体的姿态评估(即输入网络的图像中应该只有一个人体目标)。计算机视觉领域有很多任务是位置敏感的,比如目标检测、语义分割、实例分割等等。为了这些任务位置信息更加精准,就是维持高分辨率的feature map,通过下采样得到强语义信息,然后再上采样恢复高分辨率恢复位置信息,但是会导致大量的有效信息在不断的上下采样过程中丢失。而hrnet通过并行多个分辨率的分支,加上不断进行不同分支之间的信息交互,同时达到强语义信息和精准位置信息的目的。
43.优选地,本技术实施例通过hrnet网络对每一帧中的人像数据标记骨骼关键点并获取对应的平面坐标。
44.步骤s312,通过st-gcn神经网络对所述骨骼的关键点关联并识别,得到对应的2d动作信息。
45.其中,st-gcn(spatial temporal graph convolutional networks时空图卷积网络)是tcn(temporal convolutional network)与gcn(graph convolutional networks)的结合,用来处理有时序关系的图结构数据。tcn,对时间维度的数据进行卷积操作;gcn,则对空间维度的数据进行卷积操作。gcn属于gnn,而gnn的基础是图论。神经网络处理的传统数据都是欧式距离结构的数据,比如二维的图像、一维的声音等等。而对于非欧式距离结构的数据,比如社交网络、交通运输网等等,传统的网络结构无法直接处理,而gnn就是用来处理这类型数据的。
46.st-gcn与传统卷积神经网络的区别在于输入的是骨架关节数据即对应所述的骨骼关键点。尽管输入量并未像传统卷积神经网络那样大,但进一步的,由于输入的数据只保留了有效数据,更加精简,因此数据纯净度高,噪声少。同时,st-gcn不仅考虑了空间上的相邻节点,也考虑了时间上的相邻节点,将邻域的概念扩展到了时间上,实验效果表明精度也更高。
47.优选地,本技术实施例通过st-gcn将标记有骨骼关键点的人像数据进行关联,生成2d动作信息。具体的,在应用中,步骤s311得到仅为标记有骨骼关键点的人像数据,且骨骼关键点之间相对独立,因此并不能识别出人像数据对应行为特征。通过输入st-gcn中将所述骨骼关键点之间相互联系生成识别为动作特征。
48.步骤s32的具体步骤包括:将所述2d动作信息输入至posec3d和3d-cnn模型中识别,得到用户的身体和肢体行为特征。
49.其中,经过步骤s31处理得到为所述原始帧数据集中每一帧对应的2d动作信息,每一个2d动作信息仅仅对应所述原始帧数据中的一个信息片段。因此需要将每一帧的2d动作信息串联,分析得到该原始帧数据集对应的用户的身体和肢体行为特征。例如,用户弹指、用户双手击掌、用户双手比划形成一些乐器特效等。
50.2d卷积是针对一张原始图像或者视频的一帧进行的特征提取,但是很多场景中多张图片或者视频的连续帧之间往往存在关联信息,这就是3d-cnn(3d-convolutional neural network)提出的背景。3d-cnn主要是为了解决图片之间的关联信息,增加一个新的维度信息。3d-cnn以连续的多帧作为输入,增加了时间维度的信息,能够提取到更具表达性的特征。
51.posec3d是一种基3d-cnn的骨骼行为识别框架,同时具备良好的识别精度与效率,在包含finegym,nturgb+d,kinetics-skeleton等多个骨骼行为数据集上达到了sota。不同于传统的基于人体3维骨架的gcn方法,posec3d仅使用2维人体骨架热图堆叠作为输入,就能达到更好的识别效果。传统gcn方法容易被输入扰动影响,使其难以处理关键点缺失或训练测试时使用骨骼数据存在分布差异(例如出自不同姿态提取器)等情形。同时,gcn使用图序列表示骨架序列,这一表示很难与其他基于3d-cnn的模态(rgb,flow等)进行特征融合。最重要的是,gcn所需计算量随视频中人数线性增长,很难被用于群体动作识别等应用。
52.优选地,在本技术实施例中采用posec3d和3d-cnn模型将步骤s31提取的连续帧的
2d动作信息进行串联整合并识别,从而得到所述图像数据对应的用户的身体和肢体行为特征。
53.步骤s331,根据所述原始帧数据集中的环境数据与实时环境信息生成环境3d模型。
54.步骤s332,通过所述环境3d模型将所述平面坐标转换成空间坐标。
55.步骤s333,整合所有所述空间坐标得到所述用户的身体和肢体的运动轨迹。
56.其中,通过识别所述图像数据中环境数据与车载终端存储的实时环境信息进行匹配,得到所述图像数据中环境数据对应的实际空间方位并建立环境3d模型。通过所述环境3d模型将步骤s31得到的骨骼关键点的平面坐标转化成空间坐标,从而获取了用户的身体和肢体运动轨迹。再将所述运动轨迹与环境3d模型结合分析,得到此时用户与车辆互动的具体信息,例如用户双手轻轻拍击方向盘、副驾在敲击前排塑料件等。
57.具体的,在应用中,车厂可以将车辆的模型导入到车载终端中。因此算法实际上可以了解到,乘客在车中的相对位置。当手部坐标同喇叭区域重叠,或手部坐标同扶手箱表面坐标重叠,则可以认定为方向盘/扶手箱为交互的客体。相对的,通过手臂方向射线在虚拟空间内同车身的焦点,亦可以判定焦点位置为交互的客体。如副驾在座椅位置靠后的时候,手臂指向前仪表板表面,此时用户无法直接触碰该处,但也可认定用户激活改区域的互动功能。
58.步骤s40,通过卷积神经网络依次对所述原始帧数据集进行识别,以得到用户的人脸特征。
59.其中,所述人脸特征包括用户的面部表情以及视线方向。进一步的,所述卷积神经网络采用alexnet神经网络。由于alexnet神经网络高精度以及准确率的面部识别,同时基于alexnet神经网络进行视线方向的识别,为了避免头部和视线之间的过拟合,分别对头部姿势和眼球运动进行建模,然后使用视线变换层将其聚合为视线向量;为了克服基于关键点的方法引入的头部姿势模糊,通过直接使用cnn网络从外观回归头部姿势,从而实现了用户的面部表情以及视线方向的识别。
60.步骤s50,通过动态手势识别算法依次对所述原始帧数据集进行识别,以得到用户的手势特征。
61.其中,骨架动作识别系列算法对人体骨骼的动作信息进行识别,由于手部体积较小,且占用图像数据的比例相对较小,因此基于skeleton-based的动态手势识别算法来识别和跟踪手势的姿态,增强人手检测能力。尽管人手在整个输入图像中占的像素比非常小。手虽然很小,但是手一般长“人”身上,而且距离人体特定的部位(如手腕、胳膊、人脸)较近,同时与这些部位可能会有相近的颜色。这些人体或人体部位往往较手要更大,为手的检测提供了额外线索。
62.具体的识别步骤包括:
63.步骤s51,根据用户的肤色对每一帧进行颜色分割,剔除其中的干扰信息,以获取特征数据。
64.步骤s52,通过形态学灰度运算抹除用户的面部特征,得到中间特征数据。
65.步骤s53,通过基于标记的分水岭分隔算法和八连通种子填充算法分割出需要获取的手势信息,将其余皮肤裸露部分的肢体信息排除,得到目标特征数据。
66.步骤s54,将所述手势信息输入预设好的手势识别模型中识别,得到所述用户的手势特征。
67.其中,当根据用户肤色剔除干扰信息后,仍保留了用于裸露皮肤的肢体部分,包括:面部,手部以及胳膊等。为获取目标的手部位置信息,需要继续进行信息分割。
68.分水岭技术是一种众所周知的分割算法,特别适用于提取图片中的相邻或重叠对象。任何灰度图像都可以看作是一个地形表面,高峰代表高强度,山谷代表低强度。首先,用各种颜色的水(标签)填充孤立的山谷(局部极小值)。来自不同山谷的河流,颜色明显不同,随着水位上升,根据相邻的山峰(梯度)开始融合。为了避免这种情况,在水与水相遇的地方建造了屏障。你不断注水,设置障碍,直到所有的山峰都被淹没,分割结果由创建的障碍决定。然而,由于图像中存在噪声或其他异常,该方法会产生过分割的结果。因此通过基于标记的分水岭方法,允许选择哪些谷点应该合并,哪些不应该合并。它是一种交互式图像分割方法。我们所做的就是给每一个前景物体区域贴上不同的标签,我们不确定的区域是标签记为0。然后,使用分水岭算法。获得的结果中,对象的边界值将为-1。
69.种子填充算法假设在多边形或区域内部至少有一个像素是已知的。然后设法找到区域内所有其他像素,并对它们进行填充。区域可以用内部定义或边界定义。八连通算法其实就是给定一个种子点,通过循环查找以自己为中心的3*3其他八个点,满足要求的就填充自己的颜色,并调用该点旁边的八个点,不满足就跳出,循环往复。
70.通过分割算法将中间特征数据进行区域划分,并对目标区域进行标记,在通过填充算法将未标记的区域进行填充,得到目标特征数据即手势信息。
71.进一步的,根据高度和宽度建立手势模型,将手势信息输入至所述手势模型中识别,得到用户的手势特征。
72.步骤s60,根据所述用户的身体和肢体行为特征和运动轨迹、人脸特征以及手势特征与预存的指令进行比对并输出对应的音乐控制指令。
73.具体的,在应用中,当左舵车主坐在车内播放音乐时,用户伸出右手掌向上微抬,车载终端控制车载音乐播放器可以调整对应位置的音效,如加强该方向音箱的音量,重低音等,同理当用户伸出右掌向下按压时,车载终端控制车载音乐播放器可以降低该方向音箱的音效参数。
74.当用户向右侧弹指时,车载终端控制车载音乐播放器可以在右侧声道叠加三角铁音效。给用户营造出全方位的沉浸式音乐交互体验。
75.当用户双手轻轻拍击方向盘,车载终端控制车载音乐播放器可以在全车添加击鼓音效。
76.当副驾在敲击前排塑料件,车载终端控制车载音乐播放器可生成对应的钢琴特效。
77.当用户可以双手击掌,车载终端控制车载音乐播放器形成敲鼓或打镲特效。
78.当用户可以双手比划,车载终端控制车载音乐播放器形成吹唢呐特效。
79.同时,用户亦可以自定义音效,如录制打嗝,笑声等音效。
80.进一步的,音效适配敲击频率,生成对应旋律的特定音效,而不是单一声调的音效。例如用户右手做来回拉伸壮,生成对应的二胡音效。相应地,没有音乐播放的情况下,车载终端可以识别用户的动作的旋律,并控制音乐播放器播放对应旋律的音乐。如用户以特
定旋律模拟拉二胡,车载终端控制车载音乐播放器播放《二泉映月》,用户以特定旋律拍击方向盘,车载终端控制车载音乐播放器播放《西班牙进行曲》等。相应的处于交互位置,如弹指的方向/手臂的方向/敲击的塑料件附近,车载终端控制氛围灯进行相应的律动。用户也能够对车辆的不同区域进行自定义,每个区域可代表不同交互效果。如前排仪表台,可以表示钢琴效果,窗框可以表示竖琴,扶手箱表示手鼓,方向盘表示铃鼓等。
81.在一具体实施例中,可以根据用户动作的类型和节拍,使用生成对应的音效,音效可以使用karplus-strong弦乐的物理模型或算法生成。尽管音色简单,但音效却很自然。优选的,可以使用nivdia的aiva,google magenta的music vae,以及openai的jukebox模型和算法生成对应的高级音效。同时,车载终端还能够根据识别的信息,控制车载视频播放器播放特效,给予用户视觉听觉双重感受。
82.需要说明的是,上面各种方法的步骤划分,只是为了描述清楚,实现时可以合并为一个步骤或者对某些步骤进行拆分,分解为多个步骤,只要包含相同的逻辑关系,都在本专利的保护范围内;对算法中或者流程中添加无关紧要的修改或者引入无关紧要的设计,但不改变其算法和流程的核心设计都在该专利的保护范围内。
83.实施例2
84.请参见图2所示,本技术的实施例还提供一种汽车座舱的音乐交互系统,包括:
85.信息采集模块10,用于获取图像数据;
86.信息处理模块20,用于对所述图像数据进行分割,得到原始帧数据集;
87.第一信息识别模块30,用于通过骨架动作识别系列算法依次对所述原始帧数据集进行识别,以得到用户的身体和肢体的行为特征和运动轨迹;
88.第二信息识别模块40,用于通过卷积神经网络依次对所述原始帧数据集进行识别,以得到用户的人脸特征;
89.第三信息识别模块50,用于通过动态手势识别算法依次对所述原始帧数据集进行识别,以得到用户的手势特征;
90.信息反馈模块60,用于根据所述用户的身体和肢体行为特征和运动轨迹、人脸特征以及手势特征输出对应的控制指令。
91.需要说明的是,上述实施例所提供的汽车座舱的音乐交互系统与上述实施例1所提供的汽车座舱的音乐交互方法属于同一构思,其中各个模块和单元执行操作的具体方式已经在方法实施例中进行了详细描述,此处不再赘述。上述实施例1所提供的汽车座舱的音乐交互方法在实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能,本处也不对此进行限制。
92.实施例3
93.请参见图3所示,本技术的实施例还提供了一种汽车座舱的音乐交互设备,包括存储器2、处理器1及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
94.其中,存储器至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、移动硬盘、多媒体卡、卡型存储器(例如:sd或dx存储器等)、磁性存储器、磁盘、光盘等。存储器在一些实施例中可以是电子设备的内部存储单元,例如该电子设备的移动硬盘。存储器在
另一些实施例中也可以是电子设备的外部存储设备,例如电子设备上配备的插接式移动硬盘、智能存储卡(smart media card,smc)、安全数字(secure digital,sd)卡、闪存卡(flash card)等。进一步地,存储器还可以既包括电子设备的内部存储单元也包括外部存储设备。存储器不仅可以用于存储安装于电子设备的应用软件及各类数据,还可以用于暂时地存储已经输出或者将要输出的数据。
95.处理器在一些实施例中可以由集成电路组成,例如可以由单个封装的集成电路所组成,也可以是由多个相同功能或不同功能封装的集成电路所组成,包括一个或者多个中央处理器(central processing unit,cpu)、微处理器、数字处理芯片、图形处理器及各种控制芯片的组合等。处理器是所述电子设备的控制核心(control unit),利用各种接口和线路连接整个电子设备的各个部件,通过运行或执行存储在所述存储器内的程序或者模块,以及调用存储在所述存储器内的数据,以执行电子设备的各种功能和处理数据。
96.所述处理器执行所述电子设备的操作系统以及安装的各类应用程序。所述处理器执行所述应用程序以实现上述各个锂动力电池虚焊检测方法实施例中的步骤。
97.示例性的,所述计算机程序可以被分割成一个或多个模块,所述一个或者多个模块被存储在所述存储器中,并由所述处理器执行,以完成本发明。所述一个或多个模块可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序在所述电子设备中的执行过程。
98.上述以软件功能模块的形式实现的集成的单元,可以存储在一个计算机可读取存储介质中。上述软件功能模块存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、计算机设备,或者网络设备等)或处理器(processor)执行本发明各个实施例锂电池虚焊检测方法的部分功能。
99.综上所述,本发明的技术效果在于,通过视觉手段识别用户的行为特征、人脸特征、手势特征以及和车辆的交流互动,控制车载音乐播放器、氛围灯或视频播放器给予相应的反馈,形成用户与音乐之间的互动,增强趣味性,提高用户的乘车体验感。
100.上述实施例仅示例性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,但凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1