基于多尺度自注意力生成对抗网络的LDCT图像去噪方法
基于多尺度自注意力生成对抗网络的ldct图像去噪方法
技术领域
1.本发明属于医学图像去噪技术领域,涉及一种基于多尺度自注意力的生成对抗(gan)ldct图像去噪方法。
背景技术:
2.计算机断层扫描是一种可靠且无创的医学图像成像模式,有助于发现人体的病理异常,肿瘤、心血管疾病、肺结节、内伤和骨折等。除了诊断方面以外,ct在指导各种临床治疗方面也大有用处,如放射治疗和手术等。
3.然而反复的ct扫描过程中的x射线辐射可能对人体有害,可能导致免疫功能下降、代谢异常、生殖器损伤,增加白血病、癌症、遗传疾病的风险。所以需要尽可能降低x射线辐射剂量,同时还要保证ct图像质量满足诊断需求。然而,在进行ct扫描时,若穿透过病人到达探测器的光子不足,生成得ct图像就会产生严重的条纹伪影和散斑噪声,具体表现为或亮或暗的直线,这种情况在进行低剂量ct扫描时更为明显。ct图像的质量下降严重影响诊断的准确性,尤其是对小面积、形状细微的早期的病变的诊断。因此非常有必要对医学图像预处理中的去噪技术进行分析和研究,在尽可能低的辐射剂量下,对噪声区域和细微结构纹理进行准确的区分,并对噪声区域进行高效的去噪处理,从而获得与常规剂量ct图像(ndct)质量相近的ct图像。
4.过去的几十年里,提出了很多低剂量ct(ldct)恢复方法,这些传统方法可以分为三大类:正弦域滤波(sinogram domain filtering)、迭代重建(iterative reconstruction)和图像域恢复(image domain restoration),这些传统的ldct去噪算法对提高去噪图像的质量起到了重要的作用。随着深度学习的兴起,卷积神经网络(cnn)被广泛应用于图像去噪领域。由于cnn强大的特征学习能力和特征映射能力,基于cnn的ldct图像去噪网络取得了很好的效果,但仍然存在去噪图像过度平滑而导致关键细节丢失或引入了新的噪声等问题。其中损失函数的选择对图像的去噪效果起到了决定性的作用。通过传统的像素级损失函数如均方误差(mse)来计算生成的去噪图像与ndct图像对应像素点误差的平方和的均值,旨在取可能输出的平均值来适应预测中的不确定性。因为ldct图像中的噪声呈现出不同尺度、不同方向和不同密度分布等特征,所以通过这种方式训练生成的去噪图像通常会发生模糊、过度平滑、缺少纹理细节的问题。
技术实现要素:
5.本发明目的在于提供一种基于多尺度自注意力生成对抗网络的ldct图像去噪方法;利用生成对抗网络gan的对抗性损失,在训练期间动态的测量去噪图像和正常剂量图像之间的相似性,结合均方误差和平均绝对误差(mae),保证去噪图像的去噪效果的同时还能保留有更多的结构和纹理信息,提高低剂量ct图像的去噪效果。
6.使用编码器-解码器结构的生成器,构建了基于transformer的局部增强的自注意力模块(local enhanced transformer,简称leformer)来替代原有的卷积层;在保留
transformer的多头注意力机制的同时,提出了一种局部增强模块,使得网络不仅能够学习全局信息也能捕获局部信息。
7.构建包含多尺度特征提取模块的判别器,通过提取图像相同尺度下的多尺度特征来扩展模块中的感受野。采用canny边缘检测算法计算图像梯度,在图像梯度域中计算生成的去噪图像和常规剂量图像之间的平均绝对误差,结合生成对抗网络的对抗性损失和图像域的像素级损失,来增强去噪网络去除伪影和获取图像边缘信息的能力。
8.本发明具体步骤如下:
9.步骤一、构建低剂量ct图像配对数据集:
10.获取多组不同部位的常规剂量ct图像,将泊松噪声添加到每个图像中,模拟对应于常规剂量图像的低剂量ct图像;构建ct图像数据集(i
ld
,i
nd
),其中i
ld
是低剂量ct图像,i
nd
是与低剂量图像匹配的常规剂量ct图像;
11.步骤二、构建低剂量ct图像去噪模型:
12.基于gan框架构建去噪模型,即去噪模型包括生成器结构和判别器结构;通过生成器g将低剂量ct图像i
ld
映射到对应的常规剂量ct图像i
nd
,从而达到去除噪声的目的,即i
nd
≈i
gen
=g(i
ld
),i
gen
表示去噪后的图像。
13.步骤1、构建去噪模型生成器:
14.生成器为基于transformer的编码器-解码器结构;编码器包括一个词元化模块(tokenization)、两个连续的leformer模块加下采样层组合,解码器包括两个连续的上采样层加leformer模块组合以及一个反词元化模块(detokenization);编码器和解码器通过一个leformer模块相连接;在编码器和解码器中相对应的leformer模块之间存在跳跃连接,避免梯度消失问题同时,在解码器阶段可以保留更多的图像结构和纹理细节;
15.词元化模块将输入的ct图像拉伸为由n个一维的词元(token)组成的词元序列:词元化模块将输入的ct图像拉伸为由n个一维的词元(token)组成的词元序列:其中,n表示词元的个数,da为每个词元的长度;
16.基于transformer结构的leformer模块不仅能学习全局信息,还拥有捕获局部信息的能力;leformer模块有两个处理阶段:
17.在第一阶段,词元序列经过一个层归一化层(layer norm)后,进入多头自注意力模块(msa),输出具体来说,在多头自注意力模块中,词元序列ta乘以三种不同得权值矩阵wq、wk、wv得到三类张量,分别称为q、k、v,继而多头自注意力模块的输出表达式为:其中,msa表示多头自注意力机制,为张量k的长度;
18.在第二阶段,词元序列经过一个层归一化层后进入局部增强模块(local enhance)中,首先使用一个线性投影层(mlp)增加其特征维数,接着使用反词元化模块将词元序列转换为二维特征图,然后使用连续的两个残差的3x3卷积加leaky relu组合来获取二维特征中的局部信息,随后使用词元化模块将二维特征图还原为词元序列,最后使用一个线性投影层还原其特征维数,输出词元序列经过leformer模块的表达式为:
19.t
′b=msa(ln(ta))+ta;tb=le(mlp(t
′b))+t
′b;
20.上式中,ln为层归一化层,le表示局部增强模块;
21.在下采样层中,使用卷积核大小为3x3,步长为2的卷积层来实现下采样的操作;在
上采样层中,使用卷积核大小为3x3,步长为2的反卷积层来实现上采样的操作;
22.步骤2、构建去噪模型判别器:
23.判别器包括三个连续的模块:
24.第一个模块包含一个卷积核大小为3x3,步长为2的卷积层和一个批量归一化层(batch normalization)以及一个leaky relu激活函数,在减少网络的计算量的同时还起到了扩大感受野的作用;
25.第二个模块由多尺度特征提取模块组成,通过提取图像相同尺度下的多尺度特征来扩展模块中的感受野,从而提高判别器的鉴别能力;具体来说,首先利用输出通道为128,卷积核大小为1x1的卷积层进行卷积运算,得到通道数为128的特征xa;将xa平分为通道数均为32的四组特征:xb、xc、xd、xe;第一组特征xb保持不变直接作为输出得到x
′b,第二组特征xc经过卷积核大小为3x3,步长为1,填充为1的卷积层进行计算后得到输出x
′c;第三组特征xd与第二组的输出x
′c相加后经过同样的卷积核大小为3x3,步长为1,填充为1的卷积层进行计算后得到输出x
′d;以此类推,第四组特征xe与第三组特征的输出x
′d相加后经过同样的卷积核大小为3x3,步长为1,填充为1的卷积层进行计算后得到输出x
′e;将这四组特征的输出在通道维度上叠加;最后使用输出通道为1,卷积核大小为1x1的卷积层对叠加后的特征进行降维得到输出x
′a,最终完成多尺度信息的融合;通过这种方式使得特征xa近似于同时经过了多个不同大小的卷积计算,获得了不同大小的感受野,即能够在相同尺度下获取多个不同尺度的特征;
26.第三个模块包含1个卷积核大小为3x3,步长为1的卷积层和一个sigmoid激活函数;输出为判别器对输入图像真假的判断,判别器的输入图像越与常规剂量ct图像相似,则输出越接近于1。
27.步骤三、数据预处理:
28.在数据预处理阶段将数据集划分为训练集,验证集与测试集;为了更好得获取图像的局部信息并扩充样本量,将训练集和验证集的每组配对图像随机裁剪至设定大小的图像块;
29.步骤四、训练去噪模型并更新参数:
30.去噪网络依照gan框架的训练模式进行训练,将低剂量ct图像输入到生成器后得到生成的去噪图像,随后将常规剂量ct图像和去噪图像输入到判别器当中进行处理,最后输出对于去噪图像的真假判断,使用最小二乘损失函数来计算对抗性损失,去噪网络的生成器的损失函数表达式为:
31.lg=αl
gen
+βl
canny
+γl
pixel
;
[0032][0033][0034][0035]
上式中,lg表示生成器g的整体损失函数,α、β、γ为超参数,分别表示l
gen
、l
canny
和l
pixel
的权重,通过调整其值来控制这三个损失函数的重要性;l
gen
表示生成器的损失函数,
表示一个数据批量中第i个由g生成的去噪图像;l
canny
表示由经canny边缘检测算法处理后的梯度图像的l1损失函数,canny()为canny边缘检测算法,表示一个数据批量中第i个常规剂量ct图像;l
paxel
表示与的mse损失函数;
[0036]
去噪网络的判别器的损失函数
[0037]
上式中,ld表示判别器的损失函数,d为图像域判别器,表示一个数据批量中第i个常规剂量ct图像,为一个数据批量中第i个由g生成的去噪图像;
[0038]
使用adam优化器来更新网络的权重参数,在训练过程中,生成器和判别器进行交替训练;针对训练过后的去噪模型采用客观标准与主观判断相结合的方式验证模型的去噪效果,不断调整学习率以及相应超参数进行模型的优化;
[0039]
步骤五、使用在测试集中测试精度最高的去噪模型,将任意需去噪处理的低剂量ct图像输入去噪模型中,输出去噪后的低剂量ct图像。
[0040]
本发明采用以上技术方案与现有技术相比,创新和优点在于:
[0041]
构建包括leformer模块的编码器-解码器结构生成器,相较于现有的基于卷积网络的方法只能感知局部区域且提取高级特征的手段严重依赖于网络深度,基于transformer的leformer模块能够计算任意两个位置之间的关系,充分利用全局区域的相似性,此外还使用了局部增强模块来增强transformer结构学习局部信息的能力,从而增强生成器学习多尺度信息的能力,使得生成的去噪图像更好得保留原有得整体结构和局部纹理细节。
[0042]
构建基于多尺度卷积网络的判别器,其中的多尺度特征提取模块可以在相同尺度下提取多尺度特征来拓展网络的感受野,使得判别器在不过多增加卷积层数的条件下能更稳定得提取图像的整体器官结构信息,从而增强判别器辨别输入图像真假的能力,进而通过对抗性损失辅助训练生成器生成逼真的去噪图像。
[0043]
采用对抗性损失与图像域损失以及图像梯度域损失组合的损失函数,以图像域损失为主要损失函数训练去噪网络生成去噪效果优秀的去噪图像,辅以对抗性损失,增强去噪图像的结构和纹理细节,此外,采用canny边缘检测算法计算图像梯度,在图像梯度域中计算ct图像的平均绝对误差,增强去噪图像的边缘细节。
[0044]
本发明可将低剂量ct图像中得噪声和伪影进行去除,同时还能保留原有图像的整体结构和局部纹理细节以及边缘模糊问题,防止图像过度平滑,丢失局部信息,便于临床诊断。
附图说明
[0045]
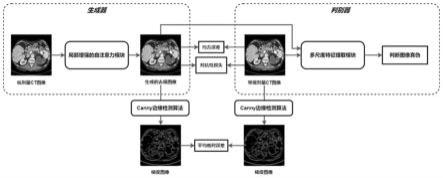
图1为本发明的整体网络结构示意图;
[0046]
图2是本发明的生成器模块结构示意图;
[0047]
图3是图2中局部增强的自注意力模块结构示意图;
[0048]
图4是本发明的判别器模块结构示意图;
[0049]
图5是实施例中低剂量ct图像示意图;
[0050]
图6是图5中低剂量ct图像去噪后的图像示意图。
具体实施方式
[0051]
以下结合附图对本发明做具体的解释说明。
[0052]
如图1所示,基于多尺度自注意力生成对抗网络的ldct图像去噪方法,具体步骤如下:
[0053]
步骤一、对ct图像数据集进行预处理:
[0054]
将ct图像数据集划分为训练集,验证集与测试集;将训练集和验证集的每组配对图像随机裁剪至10份64x64大小的图像块,获取图像的局部信息并扩充样本量。
[0055]
步骤二、优化判别器和生成器:
[0056]
将处理后的低剂量ct图像输入到生成器中,生成去噪图像,如图2所示,具体为:
[0057]
在编码器阶段:输入的低剂量ct图像xa首先经过词元化模块(tokenization),得到由n个一维的词元组成的词元序列ta;然后,ta输入局部增强的自注意力模块(leformer)中;
[0058]
如图3所示,在leformer模块中ta经历两个处理阶段:
[0059]
在第一阶段,ta经过层归一化层(layer norm)后,进入多头自注意力模块(msa),利用自注意力机制计算特征中任意两个位置之间的关系,充分利用全局区域的相似性学习全局信息,从而增强生成器学习图像整体结构的能力;在这个阶段的输出为t
′b;
[0060]
在第二阶段,t
′b经过层归一化层后进入局部增强模块(local enhance)中,首先使用线性投影层(mlp)增加其特征维数,接着使用反词元化模块将词元序列转换为二维特征图,然后使用连续的两个带有残差连接的3x3卷积加leaky relu组合来获取二维特征中的局部信息,从而增强生成器学习图像局部纹理细节的能力;随后使用词元化模块将二维特征图还原为词元序列,最后使用线性投影层还原其特征维数;在这个阶段的输出为tb;
[0061]
接着进入下采样层;首先使用反词元化模块将tb转换为二维特征图xb∈rc×h×w,其中,c为特征图xb的通道数,h和w分别表示高度和宽度;使用卷积核大小为3x3,步长为2的卷积层来进行下采样操作,此时二维特征图的大小变为随后使用词元化模块将二维特征图恢复为词元序列tc;
[0062]
tc再经过一个同样的leformer模块得到输出td;然后经过一个下采样层,得到编码器的输出te;
[0063]
在瓶颈阶段,通过一个leformer模块捕获更大范围的图像结构信息,te经过这个阶段得到输出为tf;
[0064]
接着进入解码器阶段,tf首先进入一个上采样层,使用反词元化模块将tf转换为二维特征图后,利用卷积核大小为3x3,步长为2的反卷积层来进行上采样操作,随后使用词元化模块将二维特征图恢复为词元序列tg;
[0065]
在编码器和解码器的对应位置之间存在跳跃连接,能够避免梯度消失问题并且在解码器阶段可以保留更多的图像结构和纹理细节;故tg先与编码器中第二个leformer模块的输出td进行相加,然后再进入leformer模块进行图像恢复处理,得到输出为th;
[0066]
同样的,经过一个上采样层后,将输出与编码器中第一个leformer模块的输出tb进行相加后,将结果输入到最后一个leformer模块,然后利用反词元化模块将输出还原为二维特征图,最后将输出与低剂量ct图像相加,生成最终的去噪图像;
[0067]
将得到的去噪图像和对应的常规剂量ct图像输入到判别器中,以最小化判别器的损失函数为目标优化判别器,如图5所示,判别器包括三个连续的模块,具体为:
[0068]
第一个模块为一个卷积核大小为3x3,步长为2的卷积层和批量归一化层(batch normalization,简称bn)以及leaky relu激活函数;起到了下采样层的作用,在减少网络的计算量的同时还起到了扩大感受野的作用;
[0069]
第二个模块为多尺度特征提取模块,通过提取图像相同尺度下的多尺度特征来扩展模块中的感受野,从而提高判别器的鉴别能力;
[0070]
第三个模块为1个卷积核大小为3x3,步长为1的卷积层和一个sigmoid激活函数;
[0071]
生成器生成的去噪图像和对应的常规剂量ct图像进入判别器后,最终的输出为判别器对输入图像真假的判断,判别器的输入图像越与常规剂量ct图像相似,则输出越接近于1;优化判别器即最小化判别器的损失函数
[0072]
上式中,ld表示判别器的损失函数,d为图像域判别器,表示一个数据批量中第i个常规剂量ct图像,为一个数据批量中第i个由g生成的去噪图像;
[0073]
以最小化生成器损失、图像域均方误差和图像梯度域平均绝对误差为目标优化生成器,去噪网络的生成器的损失函数表达式为:
[0074]
lg=αl
gen
+βl
canny
+γl
pixel
;
[0075][0076][0077][0078]
上式中,lg表示生成器g的整体损失函数,α、β、γ为超参数,分别表示l
gen
、l
canny
和l
pixel
的权重,通过调整其值来控制这三个损失函数的重要性;l
gen
表示生成器的损失函数,表示一个数据批量中第i个由g生成的去噪图像;l
canny
表示由经canny边缘检测算法处理后的梯度图像的l1损失函数,canny()为canny边缘检测算法,表示一个数据批量中第i个常规剂量ct图像;l
pixel
表示与的均方误差。
[0079]
步骤三、交替训练判别器和生成器:
[0080]
重复步骤二的操作,即利用优化后的生成器生成去噪图像,将生成的去噪图像输入判别器中,优化判别器,随后,使用优化后的判别器对生成器进行优化;重复上述操作交替训练判别器和生成器,直至达到实验所设置的最大迭代次数;针对训练过后的去噪模型采用客观标准与主观判断相结合的方式验证模型的去噪效果,不断调整学习率以及相应超参数进行模型的优化。
[0081]
步骤四、对低剂量ct图像进行去噪处理:
[0082]
使用训练好的去噪网络对如图5所示低剂量ct图像进行去噪处理,生成如图6所示去噪效果良好的ct图像。
[0083]
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术
人员根据本发明构思所能够想到的等同技术手段。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1