一种汉语自监督词义理解方法及系统
1.本发明属于自然语言处理技术领域,具体涉及一种汉语自监督词义理解方法及系统。
背景技术:
2.词义理解是机器理解句子与篇章的基础,是自然语言处理中的一项重要任务。在自然语言处理中,词义消歧是一种主要的词义理解任务。在国外,基于已发布的大型的英文词义标注语料库,研究者主要提出两类解决词义消歧的方法:基于知识的方法和基于监督的方法。前者主要利用义项词典来消歧,如srefkb方法,它是一种基于向量的方法,利用上下文化的词表示和wordnet义项词典中语义嵌入来执行消歧。后者主要依靠带词义标注的语料库去训练一个义项分类器,如基于semcor语料库训练的glossbert、escher方法,这些方法通过学习参数化函数将上下文中的单词映射到词语正确含义。
3.在国内,由于缺少大型汉语词义标注语料库,汉语词义消歧任务主要依赖hownet义项词典,主流方法为基于知识的方法。但这类方法只能理解词语表层含义,无法判别词义细微差别,整体性能远远低于基于监督的英语词义消歧方法。
技术实现要素:
4.针对目前汉语词义消歧缺乏大规模词义标注语料,无法有效训练机器理解词义的问题,本发明提供了一种汉语自监督词义理解方法及系统,通过解决词义消歧问题提升机器理解词义的能力。
5.为了达到上述目的,本发明采用了下列技术方案:
6.一种汉语自监督词义理解系统,包括面向词义理解的模型预训练模块、伪歧义词标记数据的构建模块、词义理解模型的建立模块;
7.所述面向词义理解的模型预训练模块:该模块从未标记汉语语料库中获取含歧义词的初始文本,根据歧义词不同词性特点对文本加入噪声,通过将带噪声的文本还原,让模型以生成式方式,自监督地学习歧义词语义表征;该模块旨在预训练一个针对歧义词理解的初始模型,将初始模型在较大无标记数据集中所学到的歧义词特征迁移到词义理解模型当中,让模型以更好初始状态训练词义理解的能力;
8.所述伪歧义词标记数据的构建:该模块通过筛选未标记汉语语料库中单义词作为待标记词语,利用相似度计算为其增添干扰释义,形成包含正确释义与干扰释义的伪歧义词的标记数据集;该模块旨在构造用于词义理解模型学习的正负样本,要求词义理解模型在投影空间中拉近目标词具体含义与正确释义的距离,拉远与干扰释义距离,以判别式方式,自监督地学习词义间差别;
9.所述词义理解模型的建立:该模块基于上述预训练模型与伪歧义词标记数据集,通过构建单选题的方式,训练机器理解词义的能力。
10.一种汉语自监督词义理解方法,包括以下步骤:
11.步骤1.1,收集原始语料:从各个领域收集训练所需文本;
12.步骤1.2,设计预训练任务:具体地,对于词义理解而言,其难点在于复杂歧义词的理解。在实际任务中,机器相比人缺乏语法语义知识,需要通过预训练任务学习上下文语义表征来获得相关知识,再通过适当微调获得语义表征与具体含义映射关系。然而传统预训练任务对随机选择的词做掩码操作来获得词义的理解,掩码对象过于宽泛,同时没有针对歧义词及其上下文信息进行专门学习,对序列信息考虑不够充分。
13.本步骤将从歧义词及其上下文入手,设计针对歧义词理解的预训练任务,帮助机器在学习更丰富的语言知识的同时,更准确地理解词义。
14.步骤1.2.1,歧义词掩码:将原始输入文本中歧义词替换为[mask]特殊符号,促使模型关注歧义词所在上下文,训练模型推断单个歧义词能力;
[0015]
步骤1.2.2,歧义词删除:将原始输入文本中歧义词删除,促使模型进一步理解整个句子,并关注到歧义词出现位置;
[0016]
步骤1.2.3,歧义词的依存词掩码:将歧义词所在上下文中与歧义词带有直接依存关系的对象替换为[mask]特殊符号,促使模型关注歧义词与依存词搭配关系;
[0017]
步骤1.2.4,词语顺序打乱:将原始输入文本中词语顺序随机打乱,促使模型关注上下文语序,训练模型对整体语义的把控。
[0018]
步骤1.3,构建预训练模型:模型采用了标准的序列到序列transformer架构,由6层编码器与6层解码器构成;编码器的输入是加了噪音的序列,解码器的输入包括两部分,一部分是编码器的输出另一部分是原始输入的right-shifted的序列,解码的输入是原始输入序列;编码器对噪声输入文本进行编码;解码器利用交叉多头注意力机制与编码器最后一层的隐藏状态结果进行注意力计算,进而以自回归的方式对噪声文本进行复原;
[0019]
步骤2.1,伪歧义词的定位与筛选:抽取汉语词典中所有词语及其词义,根据词义数量判断该词语为单义词还是多义词,并生成相应的词表;获取未标记语料库中初始文本,基于单义词词表识别文本中单义词;计算单义词tf-idf值,选择大于一定阈值且不为人名、地名、机构名等专有名词的单义词作为伪歧义词,并在语料库中进行标记;
[0020]
步骤2.2,构建伪歧义词的干扰释义:针对步骤2.1所定位的伪歧义词,利用同义词词林与多义词词表寻找与其同义的多义词;针对每个多义词,计算其释义与伪歧义词正确释义的相似度,剔除与正确释义最相似的释义,将剩余释义视为干扰释义;
[0021]
步骤3,建立词义理解模型:本模块将词义理解任务视为抽取式问答任务,在上述预训练模型基础上,通过增加一个非线性全连接层建立词义理解模型,并通过伪词义标记数据训练模型判别词义的能力,具体地,获取包含伪词义标记数据,把目标词的上下文作为问题,目标词的所有释义作为文章,根据问题从文章中抽取正确释义的片段。模型的输入为目标词的上下文及所有释义,模型通过预训练网络学习每个token的嵌入表示,再将这些特征送入全连接层进行线性变换,为每个token计算开始位置和结束位置的logits分数,进而在所有释义中选择概率最高的释义作为正确释义。
[0022]
与现有技术相比本发明具有以下优点:
[0023]
本发明通过生成式自监督与判别式自监督两种方式,提高模型对词语具体含义识别的准确性。生成式方式即设计面向词义理解的预训练任务,提升模型对文本中歧义词表示的能力;判别式方式即构建伪歧义词标记数据,引导模型学习判别词义间差别的能力,具
体包括面向词义理解的模型预训练、伪歧义词标记数据的构建、词义理解模型的建立三个模块;
[0024]
(1)本发明在面向词义理解预训练任务中,针对歧义词及上下文设计了四类噪声。在大型未标注语料库上,通过自监督的方式学习歧义词潜在语义特征表示,并将预训练模型学到的知识迁移到词义理解模型中,有效解决词义理解模型由于缺乏大规模标注语料导致性能低的问题。
[0025]
(2)本发明利用单义词构建伪词义标记数据,正负样本可信度高,并通过数据增强方式缩小与真实词义标记数据的差距,更有利为模型获得判别词义的能力提供监督信息。
[0026]
(3)本发明所提出的词义理解模型采用抽取式问答任务形式,相比基于一个释义进行判断的二分类做法,本发明能够在输入序列中一次性输入所有释义,模型在训练参数时会对所有释义进行考虑,对细微词义判别更好。
附图说明
[0027]
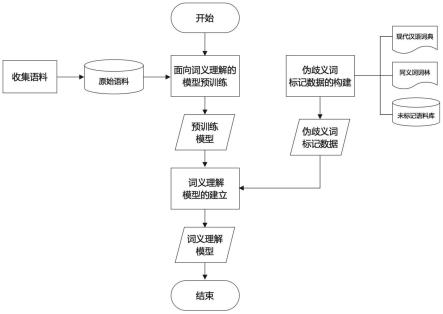
图1为本发明一种汉语自监督词义理解方法及系统流程图;
[0028]
图2为本发明所描述的面向词义理解的模型预训练具体流程图;
[0029]
图3为本发明所描述伪歧义词标记数据的构建具体流程图;
[0030]
图4为本发明所描述的词义理解模型的建立具体流程图。
具体实施方式
[0031]
现在结合附图对本发明作进一步详细的说明,附图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
[0032]
实施例1
[0033]
如图1所示,本实施例汉语自监督词义理解方法及系统,通过生成式自监督与判别式自监督两种方式,提高模型对词语具体含义识别的准确性。生成式方式即设计面向词义理解的预训练任务,提升模型对文本中歧义词表示的能力;判别式方式即构建伪歧义词标记数据,引导模型学习判别词义间差别的能力,具体包括面向词义理解的模型预训练、伪歧义词标记数据的构建、词义理解模型的建立三个模块。
[0034]
实施例2
[0035]
如图2所示,本实施例面向词义理解的模型预训练,包括收集原始语料、设计预训练任务、构建预训练模型三个步骤。
[0036]
具体来说:收集原始语料,包括:从新闻语料、社区互动、维基百科、百度百科、美食点评、电信点评中准备了近10g训练所需文本,对各个领域有所覆盖,如新闻、小说、文章、对话、聊天、评论、点评等。
[0037]
设计预训练任务,包括:从歧义词及其上下文入手,设计面向歧义词理解的预训练任务,帮助机器在学习更丰富的语言知识的同时,更准确地理解词义。具体涉及四类噪声,(1)歧义词掩码,将原始输入文本中歧义词替换为[mask]特殊符号,促使模型关注歧义词所在上下文,训练模型推断单个歧义词能力;(2)歧义词删除,将原始输入文本中歧义词删除,促使模型进一步理解整个句子,并关注到歧义词出现位置;(3)歧义词的依存词掩码,将所在上下文中与歧义词带有直接依存关系的对象替换为[mask],促使模型关注歧义词与依存
词搭配关系;(4)词语顺序打乱,将原始输入文本中词语顺序随机打乱,促使模型关注上下文语序,训练模型对整体语义的把控。
[0038]
训练预训练模型,包括:模型采用了标准的序列到序列transformer架构,由6层编码器与6层解码器构成。编码器的输入是加了噪音的序列,解码器的输入包括两部分,一部分是编码器的输出另一部分是原始输入的right-shifted的序列,解码的输入是原始输入序列。编码器对噪声输入文本进行编码;解码器利用交叉多头注意力机制与编码器最后一层的隐藏状态结果进行注意力计算,进而以自回归的方式对噪声文本进行复原。
[0039]
实施例3
[0040]
如图3所示,本实施例伪歧义词标记数据的构建,包括伪歧义词的定位与筛选、构建伪歧义词干扰释义两个步骤。
[0041]
具体来说,伪歧义词的定位与筛选,包括:抽取汉语词典中所有词语及其词义,根据词义数量判断该词语为单义词还是多义词,并生成相应的词表;获取未标记语料库中初始文本,基于单义词词表识别文本中单义词;计算单义词tf-idf值,选择大于一定阈值且不为人名、地名、机构名等专有名词的单义词作为伪歧义词,并在语料库中进行标记。
[0042]
具体来说,构建伪歧义词干扰释义,包括:针对步骤(一)所定位的伪歧义词,利用同义词词林与多义词词表寻找与其同义的多义词;针对每个多义词,计算其释义与伪歧义词正确释义的相似度,剔除与正确释义最相似的释义,将剩余释义视为干扰释义。
[0043]
实施例4
[0044]
如图4所示,本实施例词义理解模型建立,将词义理解任务视为抽取式问答任务,在上述预训练模型基础上,通过增加一个非线性全连接层建立词义理解模型,并通过伪词义标记数据训练模型判别词义的能力。
[0045]
具体地,获取包含伪词义标记数据,把目标词的上下文作为问题,目标词的所有释义作为文章,根据问题从文章中抽取正确释义的片段。模型的输入为目标词的上下文及所有释义,模型通过预训练网络学习每个token的嵌入表示,再将这些特征送入全连接层进行线性变换,为每个token计算开始位置和结束位置的logits分数,进而在所有释义中选择概率最高的释义作为正确释义。
[0046]
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1