基于居民数据关系聚合画像模型计算居民画像的方法与流程
本发明涉及关系图谱识别,具体地,涉及一种基于居民数据关系聚合画像模型计算居民画像的方法。
背景技术:
1、基层街道、乡镇、社区、行政村的人员底数与需重点关注的居民信息管理一直是基层治理中的难点。在之前的实际工作中,基层工作人员通常使用excel或纸质台账等方式记录管理,此种方式不便于查询且时效性很低。具体的,传统的居民画像标签存在以下几个问题:
2、1.单独维护一张excel或纸质台账,甚至是每个标签记录一张excel。如:低保老人、独居老人、辖区管制人员等等,如此费时费力;
3、2.统计比较困难。因数据很分散,无法立刻知道某个人属于哪种画像标签,也不能随时了解当前辖区中各类人员及总体居民的信息情况;
4、3.时效性低,影响工作效率。因每个居民信息都需手动维护,人员分类等也需要统计汇聚维护,没有一个统一的系统,给基层人员带来了极大的工作量,增加了大量的人力成本。
技术实现思路
1、本发明的目的是提供一种基于居民数据关系聚合画像模型计算居民画像的方法,该方法使得基层治理工作中数据更加准确,便于基层人员查询和维护,提高工作效率,提升基层工作满意度。
2、为了实现上述目的,本发明提供了一种基于居民数据关系聚合画像模型计算居民画像的方法,所述方法包括:
3、步骤1、梳理收集居民信息;
4、步骤2、汇聚居民信息数据,利用数据仓库starrocks实现海量数据的实时同步,将数据实时同步到关系数据库mysql当中;
5、步骤3、数据同步服务,完成关系数据库mysql中源数据到starrocks数据表的同步工作,包括表结构、全量数据和增量数据;同时,通过kafka同步增量数据;
6、步骤4、建立标签,通过标签规则服务生成的sql语句,对数据库中的标签源数据按照规则sql进行计算,生成当前标签数据、标签历史数据和标签轨迹数据;
7、步骤5、建立用户画像,即给用户相关信息打上标签,通过收集街道、乡镇、社区、行政村各个维度数据数据关系,进而对于用户的特征和行为分析;再集合基层人员所需关注的画像标签逻辑,将画像组成分解为单个标签定义逻辑;最后,将标签汇聚到每个居民信息中,由多个标签组成每个居民独有的画像;
8、步骤6、标签数据搜索,包括提供标签明细数据和标签聚合数据;
9、步骤7、标签计算任务服务,其中,任务服务提供标签计算任务的任务调度、管理、审计服务;
10、步骤8、标签存储服务,提供标签明细数据、标签历史数据、标签差异数据、标签聚合数据的存储服务;
11、步骤9、失败补偿机制,对于实时获取失败的数据,使用逻辑代码定时维护检查,采用补偿的方式将最新数据维护到数据仓库中;
12、步骤10、重新计算逻辑,数据修改后,数仓会及时触发对应标签的重新计算与统计逻辑。
13、优选地,步骤1中梳理收集的居民信息的数据来源包括人社部门、民政部门信息、卫健部门信息、信息公安部门信息及教育部门信息。
14、优选地,步骤3包括:
15、步骤3.1、fe会在接收到客户端发出的任务之后,根据kafka导入任务中的内容执行相应任务并向客户端返回响应;
16、步骤3.2、在一个task内导入,最后通过任务的执行结果来判断是否成功;每个task由多个tasks组成,每个task由task manager负责管理,task manager根据任务的需要创建新的task或者把已有的task转成其他任务;
17、步骤3.3、每个task被分到对应的be上运行;在be上,一个task被看做一个导入任务,通过stream load的导入机制进行导入操作;每个task被分配到一个或多个数据结构;如果是多个,则可以将其视为单独的job,并将其中一个作为主job,另一个作为辅job;
18、步骤3.4、be是基于fe的一层扩展,在be导入之后开始向fe汇报;
19、步骤3.5、fe依据反馈结果生成一个新的任务,如果有失败的就对失败的任务进行重试;
20、步骤3.6、为了完成数据持续不断的导入,fe会持续不断生成新的任务。
21、优选地,步骤4包括:
22、步骤4.1、获取数据来源库和标签库,数据来源库存储的是待标记数据,标签库存储的是标签信息;
23、步骤4.2、将标记类型的值赋给数据来源库中对应的属性,从而使该标记的值能够被数据库识别并且进行处理;
24、步骤4.3、确定标签类型对应的模型,以及确定该模型相绑的至少一个标签库;
25、步骤4.4、利用模型和与之相绑定的至标签库对需要标记标记数据进行标签构建。
26、优选地,在步骤4生成标签之后,按照数据的实效性将标签分为:
27、静态标签,指的是客观的事实不会发生改变的;
28、动态标签,指有时效性的标签,需定期更新;
29、模型标签,无数据,规则自定义,需要后期建立模型来得出标签;
30、预测标签,依据现有的数据,预测用户的行为。
31、优选地,步骤5包括:
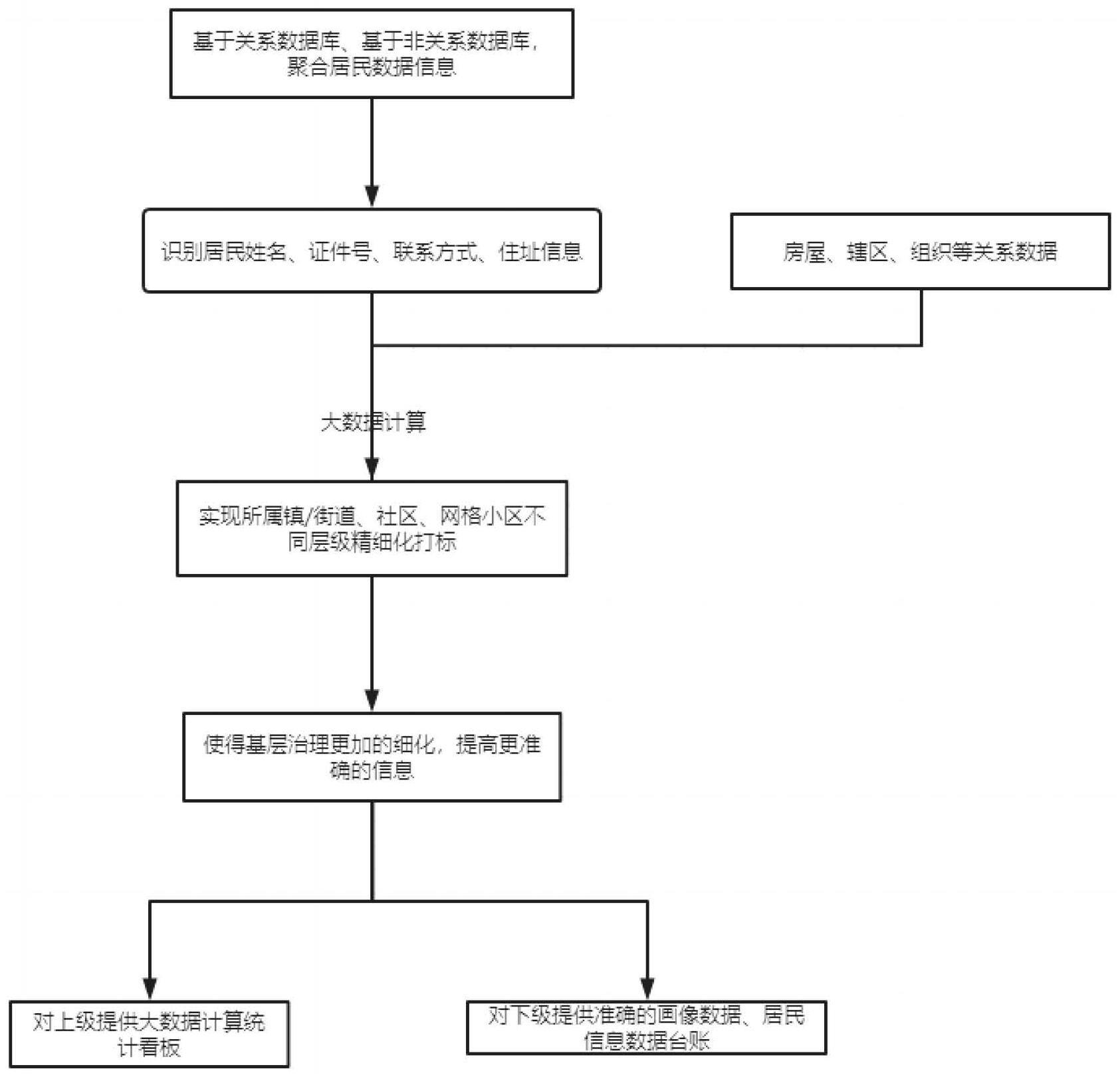
32、步骤5.1、用f(x,y)表示用户x标记了一个标签y的次数,tf(x,y)表示标记次数在当前用户下所有的标签中所占据的权重比例,公式为:其中,f(x,y)为标签y的次数,∑f(x,y’)表示全部标签数量;
33、步骤5.2、标签y在所有标签中的稀有程度使用idf(x,y)表示,即此标签的出现概率:其中,∑∑f(x1,y1)表示用户的全部标签之和,∑f(x1,y)为所有打y标签的用户之和;此时,如果某个标签出现概率很低,且同时被用于标记用户,则表明这个用户和这个标签之间的关系非常紧密;然后,根据idf*tf计算出这个用户该标签下的权重系数。
34、优选地,步骤6中的搜索步骤依次包括设计表、设计字段和建表。
35、优选地,在步骤8中对数据的执行方式做出调整,包括:
36、分区存储,各自执行作业;
37、基于标签的同源数据,开发中间表;
38、以及优化标签脚本和中间表执行的性能。
39、根据上述技术方案,本发明通过以下步骤:1、基于关系数据库、非关系数据库聚合居民数据信息,识别居民姓名、证件号、联系方式、住址信息等多要素信息;2、通过居民画像标签定义,使用大数据计算将居民与房屋、辖区、组织等关系根据所属镇/街道、社区、网格小区等不同层级精细化打标,使得基层治理更加的细化,提高更准确的信息。3、对上级提供大数据计算统计看板,对下级提供准确的画像数据、居民信息数据台账,根据组织角色分配不同的画像标签权限,使得基层治理工作中数据更加的准确,便于基层人员查询、维护。
40、本发明的其他特征和优点将在随后的具体实施方式部分予以详细说明。
技术特征:
1.一种基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,步骤1中梳理收集的居民信息的数据来源包括人社部门、民政部门信息、卫健部门信息、信息公安部门信息及教育部门信息。
3.根据权利要求1所述的基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,步骤3包括:
4.根据权利要求1所述的基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,步骤4包括:
5.根据权利要求4所述的基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,在步骤4生成标签之后,按照数据的实效性将标签分为:
6.根据权利要求1所述的基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,步骤5包括:
7.根据权利要求1所述的基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,步骤6中的搜索步骤依次包括设计表、设计字段和建表。
8.根据权利要求1所述的基于居民数据关系聚合画像模型计算居民画像的方法,其特征在于,在步骤8中对数据的执行方式做出调整,包括:
技术总结
本发明公开了一种基于居民数据关系聚合画像模型计算居民画像的方法,所述方法包括:步骤1、梳理收集居民信息;步骤2、汇聚居民信息数据;步骤3、数据同步服务;步骤4、建立标签;步骤5、建立用户画像;步骤6、标签数据搜索;步骤7、标签计算任务服务;步骤8、标签存储服务;步骤9、失败补偿机制;步骤10、重新计算逻辑。该方法使得基层治理工作中数据更加准确,便于基层人员查询和维护,提高工作效率,提升基层工作满意度。
技术研发人员:朱世成,承孝敏,张名扬,孔慧宇,丁梦婷,张宗谦
受保护的技术使用者:长三角信息智能创新研究院
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!