一种嘴型动画生成方法、装置、存储介质及电子设备与流程
本申请涉及计算机,尤其涉及一种嘴型动画生成方法、装置、存储介质及电子设备。
背景技术:
1、音频驱动嘴型动画生成技术,即根据给定的音频输入,利用计算机技术合成与音频同步的嘴型动画的技术。
2、该技术目前在虚拟人像交流领域得到广泛的应用。
技术实现思路
1、本申请实施例提供的一种嘴型动画生成方法、装置、存储介质及电子设备,可以根据音频数据生成与音频数据对应的嘴型动画。所述技术方案如下:
2、第一方面,本申请实施例提供的一种嘴型动画生成方法,其特征在于,所述方法包括:
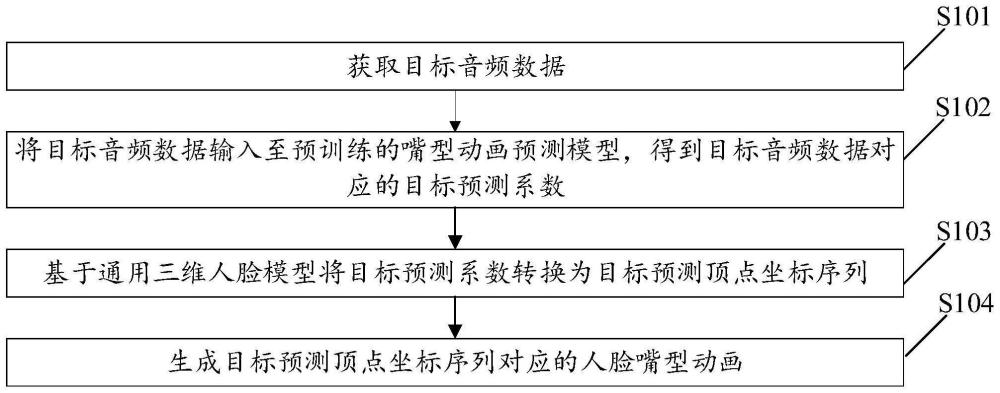
3、获取目标音频数据;
4、将所述目标音频数据输入至预训练的嘴型动画预测模型,得到所述目标音频数据对应的目标预测系数;
5、基于通用三维人脸模型将所述目标预测系数转换为目标预测顶点坐标序列;
6、生成所述目标预测顶点坐标序列对应的人脸嘴型动画。
7、第二方面,本申请实施例提供的一种嘴型动画生成装置,所述装置包括:
8、目标数据获取模块,用于获取目标音频数据;
9、预测系数获取模块,用于将所述目标音频数据输入至预训练的嘴型动画预测模型,得到所述目标音频数据对应的目标预测系数;
10、坐标序列生成模块,用于基于通用三维人脸模型将所述目标预测系数转换为目标预测顶点坐标序列;
11、嘴型动画生成模块,用于生成所述目标预测顶点坐标序列对应的人脸嘴型动画。
12、第三方面,本申请实施例提供一种计算机存储介质,所述计算机存储介质存储有多条指令,所述指令适于由处理器加载并执行上述的方法步骤。
13、第四方面,本申请实施例提供一种电子设备,可包括:处理器和存储器;其中,所述存储器存储有计算机程序,所述计算机程序适于由所述处理器加载并执行上述的方法步骤。
14、在本申请一个或多个实施例中,首先获取目标音频数据,将目标音频数据输入至预训练的嘴型动画预测模型中,基于嘴型动画生成模型对目标音频数据进行预测,得到目标音频数据对应的目标预测系数,然后基于通用三维人脸模型将目标预测系数转换为目标预测顶点坐标序列,最后再根据目标预测顶点坐标序列生成对应的人脸嘴型动画,实现了根据给定音频自动生成对应的人脸嘴型动画,预训练的嘴型动画预测模型充分保证所生成人脸嘴型动画的拟真度,使得生成的人脸嘴型动画具有极佳的自然观感。
技术特征:
1.一种嘴型动画生成方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述将所述目标音频数据输入至预训练的嘴型动画预测模型,得到所述目标音频数据对应的目标预测系数,包括:
3.根据权利要求2所述的方法,其特征在于,所述基于所述嘴型动画预测模型的系数预测层对所述各帧音频分别对应的音频特征进行系数预测,得到各帧音频分别对应的目标预测表情系数和目标预测形状系数,包括:
4.根据权利要求1所述的方法,其特征在于,所述获取音频数据之前,还包括:
5.根据权利要求4所述的方法,其特征在于,所述样本训练数据包括第一音频数据、第二音频数据、第三音频数据、所述第一音频数据对应的第一标准顶点坐标序列、所述第二音频数据对应的第二标准顶点坐标序列、所述第三音频数据对应的第三标准顶点坐标序列,所述第一音频数据为第一人物对第一文本内容录制的音频数据,所述第二音频数据为第一人物对第二文本内容录制的音频数据,所述第三音频数据为第二人物对第一文本内容录制的音频数据;
6.根据权利要求5所述的方法,其特征在于,所述将所述第一音频数据输入至嘴型动画预测模型中,得到所述第一音频数据对应的第一预测系数,所述第一预测系数包括第一音频数据中各帧音频分别对应的第一预测表情系数和第一预测形状系数,包括:
7.根据权利要求6所述的方法,其特征在于,所述基于所述嘴型动画预测模型的系数预测层对所述各帧音频分别对应的第一音频特征进行系数预测,得到各帧音频分别对应的第一预测表情系数和第一预测形状系数,包括:
8.根据权利要求5所述的方法,其特征在于,所述基于通用三维人脸模型将各音频数据分别对应的预测系数转换为各所述音频数据分别对应的预测顶点坐标序列,包括:
9.根据权利要求5所述的方法,其特征在于,所述将所述样本训练数据输入至嘴型动画预测模型中,得到所述样本训练数据中各所述音频数据分别对应的预测系数之后,所述方法还包括:
10.一种嘴型动画生成装置,其特征在于,所述装置包括:
11.一种存储介质,其上存储有多条指令,其特征在于,所述指令被处理器执行时实现权利要求1~9中任意一项所述方法的步骤。
12.一种电子设备,其特征在于,包括:处理器和存储器;其中,所述存储器存储有计算机程序,所述计算机程序适于由所述处理器加载并执行如权利要求1~9中任意一项所述方法的步骤。
技术总结
本申请公开了一种嘴型动画生成方法、装置、存储介质及电子设备,通过获取目标音频数据,然后将目标音频数据输入至预训练的嘴型动画预测模型,得到目标音频数据对应的目标预测系数,再基于通用三维人脸模型将目标预测系数转换为目标预测顶点坐标序列,最后生成目标预测顶点坐标序列对应的人脸嘴型动画,实现了根据给定音频自动生成对应的人脸嘴型动画。
技术研发人员:王乃洲,张玉兵,鲍文杰,谢宗生
受保护的技术使用者:广州视源电子科技股份有限公司
技术研发日:
技术公布日:2024/5/19
- 还没有人留言评论。精彩留言会获得点赞!