一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法
:本发明涉及一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法,该方法在森林图像中毁林因素的分类领域有着很好的应用。
背景技术
0、
背景技术:
1、无线电通信技术发展迅速。第五代移动信息系统(5g)与物联网相结合。无线电通信技术可以满足越来越多的应用需求,通信速度也越来越快。现在,我们已经开始向第六代移动信息系统(6g)迈进。6g网络将以5g技术为基础,结合地面通信网络和空间卫星通信网络,实现全球覆盖的全连接通信网络。因此,在6g环境下,地面-卫星网络(tsn)将成为通信探索空域资源的关键杠杆。通过卫星信号融合、全球无缝信号覆盖、全球定位卫星系统、图像卫星系统和6g地面网络,6g网络可以帮助人们快速探索地面信息。
2、在现代,保护森林资源可以防止物种灭绝,创造清洁的空气和水,检测气候变化。由于某种原因,热带地区的森林损失造成了全球每年约10%的温室气体排放,为了减少潜在的气候临界点,应该减少这些排放。导致热带雨林毁林的直接因素或具体活动包括自然事件(如火灾和洪水)、人工土地占用(如工农业发展)和人类活动。准确识别这些因素对于实施有针对性的保护森林政策和行动至关重要。
3、与之前的机器学习方法如决策树、随机森林分类器等相比,卷积神经网络convolutional neural networks(cnn)是提取数据特征最有效的方法。然而,这些基于cnn的方法通常只使用清晰、标准的数据进行发明训练,一旦数据发生变化,例如由于卫星旋转导致图像角度发生变化或由于云雾干扰导致图像模糊,性能就会变得不稳定。
4、考虑到数据多样性的增加,提出了一种基于cnn网络的森林砍伐图像分类发明。我们使用了一个编码器、一个分类头和一个角度预测头。通过数据模糊和旋转处理,该发明可以利用组合后的数据进行更深入的训练,更高效、更准确地预测森林损失的因素。
技术实现思路
1、为了解决针对于图像分类领域中的毁林因素的分类问题,本发明公开了一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法。
2、(一)技术方案
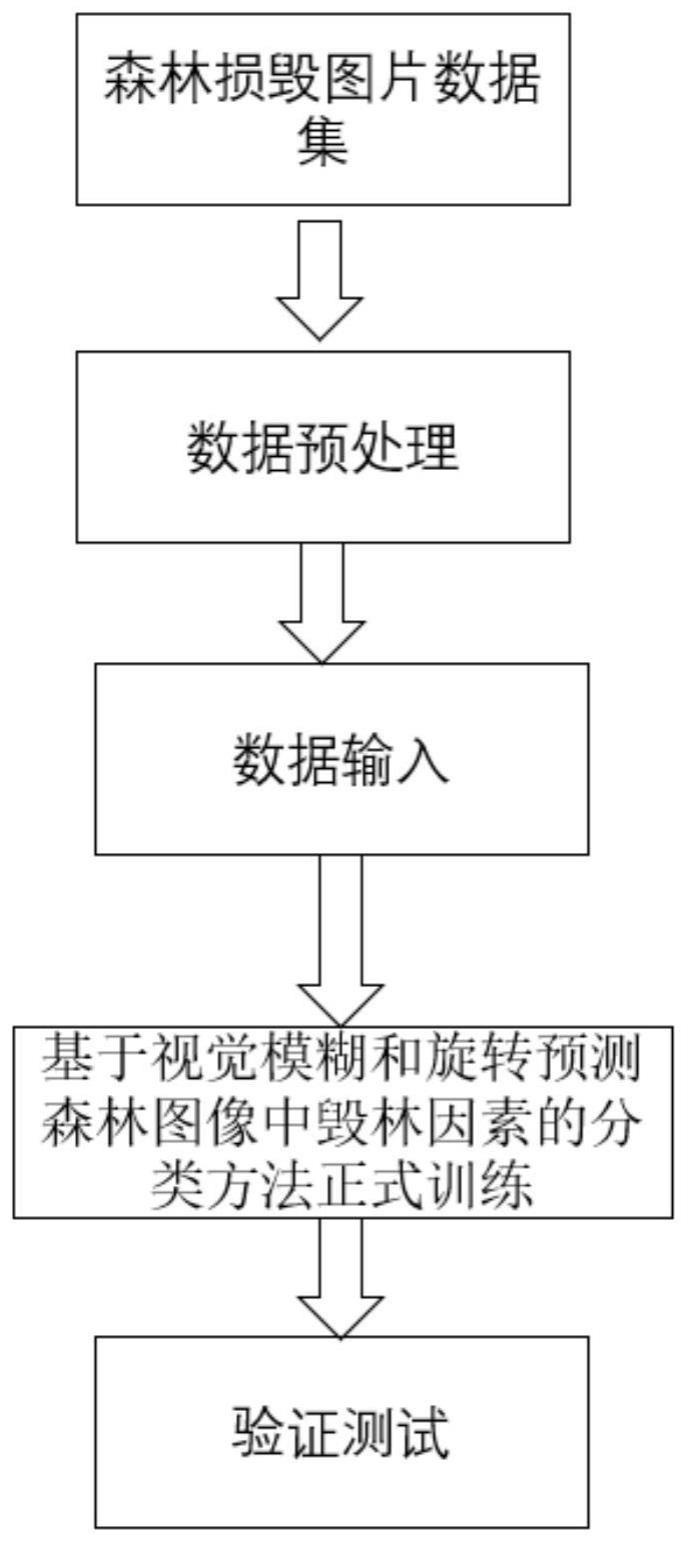
3、毁林因素的图像分类神经网络的框架使用resnet-18神经网络构成。该网络主要由多个基础块不断叠加构成。每个基础块都由两个残差块进行连接,每个残差块由两个卷积层、两个激活层、两个batchnorm层和一个短路连接层组成。构建并实现遥感图像发明包括以下具体步骤:
4、1.数据预处理阶段,通过使用pytorch代码,随机提取数据集中相应的数据组成新的数据集合。在原数据集中,所有数据都具有标签并根据类别划分集合。本发明将整体数据集大致划分为6:2:2的训练集、验证集、测试集。通过训练集、验证集、测试集的交替使用,得到更加严谨、正确、具有可靠性质的实验结果。
5、步骤1_1生成数据集。
6、步骤如下:
7、考虑一个有n种数据的数据集x,
8、其中60%是作为训练数据xt,
9、中间20%作为验证数据xv,
10、最后20%作为测试数据xv,
11、2.数据输入阶段,将原始数据经过处理,重新修订大小为128*128。然后将原始数据进行模糊和曝光等增强,以用来模拟经过恶劣天气后卫星照射出的失真图片。最后将原始数据进行旋转,用来模拟卫星探头的自转功能。
12、步骤2_1将原始数据通过datasets下的train.csv文件从example文件夹中读出,整理成一一对应的数据集合和标签集合。
13、步骤2_2通过使用dataloader.py文件中的代码,将两个数据集合经过简单处理将大小修改成128*128,然后通过使用transformer对图片进行模糊和曝光处理。将原始数据和增强数据通过进行整合,生成train_datasets。验证集和测试集数据也如上导入。
14、步骤2_3将train_datasets中存在的数据经过torch环境中所具有的的dataloader方法整理成train_dataloader,使其具有batch_size和打乱顺序的属性。验证集和测试集数据也如上处理。
15、3.模型训练阶段,使用60%的封装处理好的训练数据集train_dataloader。训练数据作为模型训练的输入,经过模型的训练,得到优化后的模型。
16、步骤3_1提取本次batch_size大小的数据进行随机旋转,生成旋转数据。将所旋转的角度保留下来处理成数据集的标签。其公式如下:
17、
18、
19、步骤3_2将得到的旋转数据集和原始数据集相拼接,得到一个传入网络前的完整数据集,具体公式如下所示:
20、
21、步骤3_3将拼接好的数据集传入准备好的网络模型中,得到属于该数据的特征表示。公式如下:
22、f=encoder(xr)
23、步骤3_4将得到的特征根据数据集重新划分,分别进入分类器和旋转预测器,得到模型预测。公式如下:
24、
25、
26、步骤3_5将所得到的预测概率进行softmax后,与所对应的标签进行交叉熵计算损失。
27、具体分类损失公式如下;
28、
29、其中b表示批量大小,p(y|xb)=softmax(f)是分类的预测。h是yb和p(y|xb).之间的交叉熵。预测损失如下所示:
30、
31、其中表示旋转数据xr,是预测输出。
32、步骤3_6反向传播损失值并优化发明。
33、步骤3_7不断迭代得到优化后的发明。
34、4.模型验证测试阶段,针对于优化完成并收敛的发明,使用数据集后40%的部分对其数据分析能力进行检测。本发明使用准确度作为本发明衡量发明优劣的标准,使用伪标签的方式模拟真实世界数据存在情况,为无标记数据生成标签,使发明可以通过更加大量、全面的数据进行训练。然后通过假数据提高发明对特征全面性的学习能力,避免发明过度注重通过标签对自身进行修正,遗漏部分特征的学习。
35、步骤4_1应用验证集对发明进行验证,判断发明当前迭代次数的学习效果,将最好成果进行替换保存。
36、步骤4_2若当前迭代次数验证结果为历史最好,则进行测试,保存当前测试结果。
37、步骤4_3输出最后正确率结果,与resnet-18模型进行对比。
38、(二)有益效果
39、1.本发明解决了原始的卫星图像未考虑到由于天气等因素所产生的图像模糊等问题,使用该模型进行训练学习看,可以有效避免因为图像模糊而造成的模型误判,提高模型的强健特性。
40、2.本发明解决了由于卫星探测头自动旋转的因素导致图片角度变换的问题,通过使用旋转预测进行训练,使模型在训练过程中就可以学习到有效的旋转表示,将角度问题与正常表示联系起来。
技术特征:
1.一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法,其特征在于该方法包括以下步骤:
2.根据权利要求1所述的一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法,其特征在于,所述步骤1中的数据预处理模块,具体步骤为:
3.根据权利要求1所述的一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法,其特征在于,所述步骤2中的数据输入模块,具体步骤为:
4.根据权利要求1所述的一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法,其特征在于,所述步骤3中的训练模块,具体步骤为:
5.根据权利要求1所述的一种基于视觉模糊和旋转预测森林图像中毁林因素的分类方法,其特征在于,所述步骤4中的模型测试模块,具体步骤为:
技术总结
本发明实施方式中的基于视觉模糊和旋转预测森林图像中毁林因素的分类方法,该框架使用新的数据增强方法,即使面对云层或极端天气,该模型的性能也不会受到干扰。此外,即使应用数据旋转和自监督方法,模型的分类预测也可以保持稳定。本发明创新地将数据模糊与数据旋转自监督学习相结合,使模型可以更全面与准确的学习数据的特征表示。同时,应用这种数据增强进行表示学习可以后的更加强健、稳定的模型效果,避免因为数据污染而造成的结果干扰。将所提的网络模型应用于毁林因素图片数据的分类,能达到提升准确率的目的,实验结果验证了所提方法的有效性。
技术研发人员:席亮,孟祥龙,何东
受保护的技术使用者:哈尔滨理工大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!