本发明属于信息处理,尤其涉及一种网络个人信息识别提取及保护方法。
背景技术:
1、随着“数字经济”的快速发展,信息技术与经济社会持续深度融合,网络已成为生产生活的新空间、经济发展的新引擎、交流合作的新纽带。中国互联网络信息中心(cnnic)发布的《中国互联网络发展状况统计报告》显示,截至2021年12月,我国网民规模达10.32亿,互联网普及率达73.0%。然而,据监管部门的通报显示,移动互联网应用程序违法违规收集、使用个人信息的现象依然广泛存在。
2、当前,我国个人信息保护力度不断加大,已经形成一套相对完善的个人信息保护法律体系。2021年11月1日,《中华人民共和国个人信息保护法》的正式实施,为个人信息处理活动提供了明确的法律依据,为个人维护其自身信息权益提供了充分保障。2020年,国家标准化管理委员会发布和实施《信息安全技术个人信息安全规范》(gb/t 35273-2020),明确了个人信息的定义、范围和属性,为个人信息的识别和提取,提供了准则和依据。通过精准的个人信息识别技术,可以有效地对业务数据中个人信息进行去标识化处理,从而有效地保护公民个人信息。
3、当前技术是通过人工预先对数据库中的数据进行字段进行标识、或对业务系统中数据字段以及对应的变量名称进行标识,以此来识别哪些属于个人信息。
4、数据库表结构的设计、应用系统api接口数据交互(json\xml等格式)通常都由应用程序设计相应的字段名、变量名来标识数据的属性。例如:id:代表身份证号,mobile:代表手机号、address:代表家庭地址。
5、当前采用人工预先对个人信息数据定义进行标记的方式,虽然能够准确标记个人信息,但对于批量数据中或混杂在数据中的个人信息,无法有效地进行识别。
6、业务系统数据经过协议解析,将输出大量的文本信息,这些文本信息中,可能会掺杂着部分个人信息甚至个人敏感信息(参见gb/t35273-2020信息安全技术个人信息安全规范),如:手机号、身份证号、家住址等。在数据库系统里(以结构化为例),可以通过表结构定义,来标记数据的属性:如:姓名、电话、身份证号、家庭地址等。但是在网络应用中,许多个人信息并非独立地或者以特定的变量值进行传输,而是广泛地混杂于应用系统之中,如:网络社区、论坛、网络博客或电子邮件文本里等,都有可能大量存在敏感个人信息。这些信息的组织,并不像结构化数据库那样有着固定的规律性,而是以极不规则的形态存在于网络数据之中。如何从大量的网络(应用)文本数据中准确地筛选、识别出个人信息和敏感信息,将是数据安全和个人信息安全研究的重要内容。
技术实现思路
1、本发明的主要目的在于克服现有技术的缺点与不足,提供一种网络个人信息识别提取及保护方法及系统,能够自动解析、识别应用系统数据流中夹杂的个人信息,实现应用系统个人信息去标识化处理,为个人隐私保护创造有利条件。
2、根据本发明的一个方面,本发明提供了一种网络个人信息识别提取及保护方法,所述方法包括以下步骤:
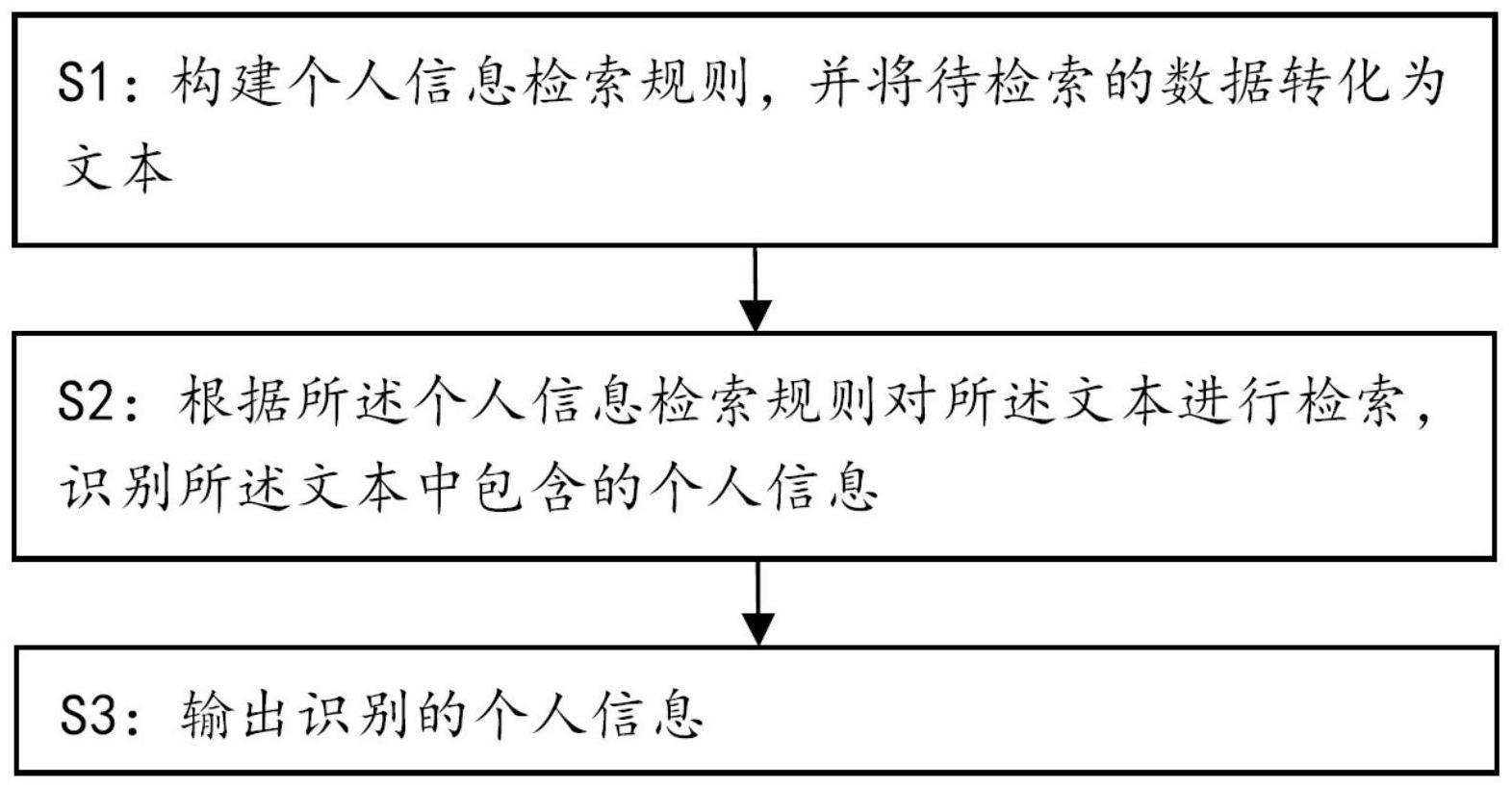
3、s1:构建个人信息检索规则,并将待检索的数据转化为文本;
4、s2:根据所述个人信息检索规则对所述文本进行检索,识别所述文本中包含的个人信息;
5、s3:输出识别的个人信息。
6、优选地,所述构建个人信息检索规则包括:
7、定义识别规则和分析函数,所述识别规则与个人信息的类型相匹配,所述分析函数用于对输入的文本进行分析。
8、优选地,所述根据所述个人信息检索规则对所述文本进行检索,识别所述文本中包含的个人信息包括:
9、根据所述识别规则对所述文本进行处理,将处理后的文本加载入所述分析函数,输出识别出的个人信息字符清单。
10、优选地,所述输出识别的个人信息,包括:
11、对所述个人信息字符清单进行信息校验,判断所述个人信息字符清单是否为个人信息,若是,则输出所述个人信息。
12、优选地,所述个人信息包括电话号码、身份证号码、家庭住址。
13、根据本发明的另一个方面,本发明还提供了一种个人信息自动识别系统,所述系统包括:
14、处理模块,用于构建个人信息检索规则,并将待检索的数据转化为文本;
15、识别模块,用于根据所述个人信息检索规则对所述文本进行检索,识别所述文本中包含的个人信息;
16、输出模块,用于输出识别的个人信息。
17、优选地,所述处理模块构建个人信息检索规则包括:
18、定义识别规则和分析函数,所述识别规则与个人信息的类型相匹配,所述分析函数用于对输入的文本进行分析。
19、优选地,所述识别模块根据所述个人信息检索规则对所述文本进行检索,识别所述文本中包含的个人信息包括:
20、根据所述识别规则对所述文本进行处理,将处理后的文本加载入所述分析函数,输出识别出的个人信息字符清单。
21、优选地,所述输出模块输出识别的个人信息,包括:
22、对所述个人信息字符清单进行信息校验,判断所述个人信息字符清单是否为个人信息,若是,则输出所述个人信息。
23、优选地,所述个人信息包括电话号码、身份证号码、家庭住址。
24、有益效果:本发明通过构建识别规则,编写相应的数据计算过程,可用于解析、自动识别应用系统数据流中夹杂的个人信息,为应用系统个人信息去标识化处理和个人隐私保护创造有利条件。
25、通过参照以下附图及对本发明的具体实施方式的详细描述,本发明的特征及优点将会变得清楚。
技术特征:1.一种网络个人信息识别提取及保护方法,其特征在于,所述方法包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,所述构建个人信息检索规则包括:
3.根据权利要求2所述的方法,其特征在于,所述根据所述个人信息检索规则对所述文本进行检索,识别所述文本中包含的个人信息包括:
4.根据权利要求3所述的方法,其特征在于,所述输出识别的个人信息,包括:
5.根据权利要求4所述的方法,其特征在于,所述个人信息包括电话号码、身份证号码、家庭住址。
6.一种个人信息自动识别系统,其特征在于,所述系统包括:
7.根据权利要求6所述的系统,其特征在于,所述处理模块构建个人信息检索规则包括:
8.根据权利要求7所述的系统,其特征在于,所述识别模块根据所述个人信息检索规则对所述文本进行检索,识别所述文本中包含的个人信息包括:
9.根据权利要求8所述的系统,其特征在于,所述输出模块输出识别的个人信息,包括:
10.根据权利要求9所述的系统,其特征在于,所述个人信息包括电话号码、身份证号码、家庭住址。
技术总结本发明涉及一种网络个人信息识别提取及保护方法一种网络个人信息识别提取及保护方法,属于信息处理技术领域。方法包括:构建个人信息检索规则,并将待检索的数据转化为文本;根据所述个人信息检索规则对所述文本进行检索,识别所述文本中包含的个人信息;输出识别的个人信息。本方法能够自动解析、识别应用系统数据流中夹杂的个人信息,实现应用系统个人信息去标识化处理,为个人隐私保护创造有利条件。
技术研发人员:贾建刚,费汉明,张伟辉,孟涛,张轩,程月龙
受保护的技术使用者:中国国家铁路集团有限公司
技术研发日:技术公布日:2024/1/13