文本分类方法、可读存储介质及电子设备与流程
本公开涉及自然语言处理领域,具体地,涉及一种文本分类方法、可读存储介质及电子设备。
背景技术:
1、bert(英文全称:bidirectional encoder representation from transformers)等大规模预训练模型的落地是nlp(英文全称:natural language processing;中文名词:自然语言处理)发展的重要里程碑之一,大模型在现实应用中取得了巨大进展。随着研究的深入,预训练模型在各类nlp任务上的表现不断提升,但现有的模型仍然存在泛化能力不强、鲁棒性差等缺陷。比如,在测试域外数据、应对对抗性攻击或者输入端的微小扰动时,预训练模型的性能会有大幅下降,影响了大模型的实际应用部署。
技术实现思路
1、本公开的目的是提供一种文本分类方法、可读存储介质及电子设备,用于解决现有技术中存在的,现有的文本分类模型泛化能力不强、鲁棒性差等技术问题。
2、为了实现上述目的,本公开第一方面提供文本分类方法,包括:
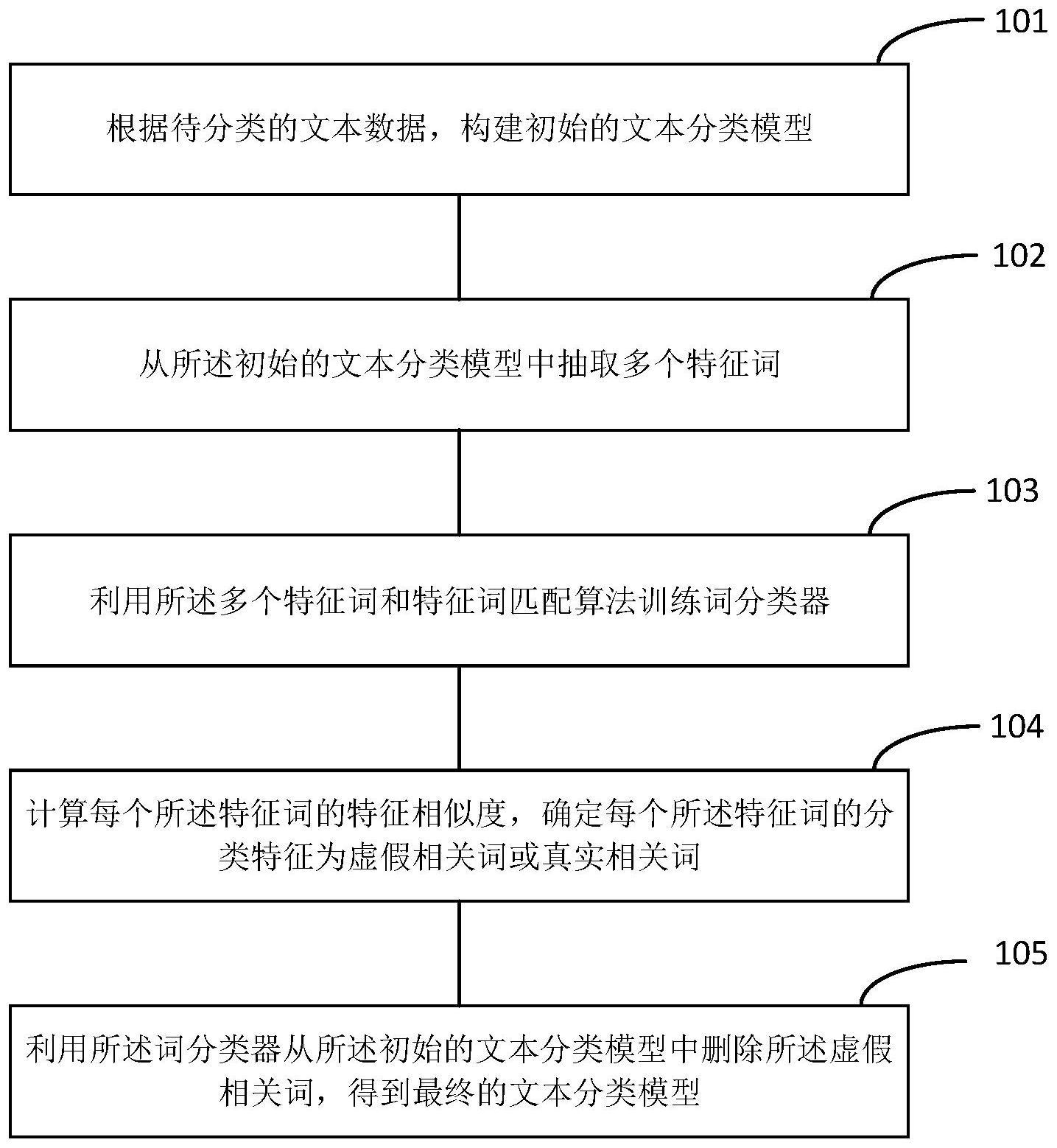
3、根据待分类的文本数据,构建初始的文本分类模型;
4、从所述初始的文本分类模型中抽取多个特征词;
5、利用所述多个特征词和特征词匹配算法训练词分类器;
6、计算每个所述特征词的特征相似度,确定每个所述特征词的分类特征为虚假相关词或真实相关词;
7、利用所述词分类器从所述初始的文本分类模型中删除所述虚假相关词,得到最终的文本分类模型。
8、可选的,根据待分类的文本数据,构建初始的文本分类模型,包括:
9、获取所述待分类的文本数据,对所述待分类的文本数据进行处理获得训练集;
10、利用所述训练集训练初始的文本分类器;其中,所述初始的文本分类器包括:输入层,用于输入所述文本数据;bert预训练模型,用于对输入文本数据进行编码获得词向量,基于所述词向量获得输入序列,并根据bert预训练模型编码后的序列获得词的重要性权重。
11、可选的,对所述bert预训练模型编码的词向量进行重要性权重分析,包括:
12、给定数据集d={(s1,y1),(s2,y2)…(sn,yn)},其中,si表示一条文本数据,yi是对应的标签;
13、每条文本数据si经过所述bert预训练模型编码后,取最后一层的cls标志位向量ci,所述标志位向量ci融合了所述文本数据中各个词的语义信息;
14、计算ci与各eij的相似度αij,eij是指其他位置词向量,所述利用相似度αij用于表示词的重要性权重。
15、可选的,从所述初始的文本分类模型中抽取多个特征词,包括:
16、基于所述词的重要性权重,对每个所述文本数据找出重要性权重靠前的多个词作为特征词,构成特征词集合。
17、可选的,所述方法还包括:
18、根据所述词的重要性权重大小抽取每个所述文本数据的前三个词作为特征词,构成所述特征词集合。
19、可选的,所述特征词匹配算法包括:
20、对于指定文本数据s,若s中有词w,记为s[w],若s中没有词w,记为s[w′];匹配的目标是寻找另一段文本s1[w′1],使得s1[w′1]的语义与s去掉词w后的文本数据s0[w′0]语义相似;计算n条文本数据中的词w的平均处理效应ate,n为大于等于2的正整数;若词w的atew值大于或等于预设阈值,则词w是真实相关词。
21、可选的,所述方法还包括:
22、计算特征参数对词分类器进行优化,所述特征参数包括多个最接近匹配项的上下文相似性的平均值、相似性分数的标准差、加权平均处理效应中的一个或多个,其中,加权平均处理效应中的权重由相似性分数计算而来。
23、可选的,所述方法还包括:在测试所述最终的文本分类模型时,将测试数据分为两组,第一组测试数据中包含虚假关联可能会误导所述文本分类器的文本数据,第二组测试数据中包含虚假相关帮助所述文本分类器的文本数据。
24、本公开第二方面提供一种非临时性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面所述方法的步骤。
25、本公开第三方面提供一种电子设备,包括:
26、存储器,其上存储有计算机程序;
27、处理器,用于执行所述存储器中的所述计算机程序,以实现第一方面所述方法的步骤。
28、本公开的方案针对文本分类模型通常只关注统计相关性而忽略因果相关性的缺点与不足,提供一种基于bert模型与数据增强的文本分类方法,考虑文本中的潜在因果关系,其中的数据增强方法借鉴了因果推断领域的反事实理论,主要解决现有文本分类模型泛化能力与鲁棒性较弱的问题,与目前的现有技术相比,本公开实施例中的方案的分类模型会实现更鲁棒的分类,能够减小文本分类中虚假相关性的影响。
29、本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
技术特征:
1.一种文本分类方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,根据待分类的文本数据,构建初始的文本分类模型,包括:
3.如权利要求2所述的方法,其特征在于,对所述bert预训练模型编码的词向量进行重要性权重分析,包括:
4.如权利要求3所述的方法,其特征在于,从所述初始的文本分类模型中抽取多个特征词,包括:
5.如权利要求4所述的方法,其特征在于,所述方法还包括:
6.如权利要求4所述的方法,其特征在于,所述特征词匹配算法包括:
7.如权利要求4所述的方法,其特征在于,所述方法还包括:
8.如权利要求2所述的方法,其特征在于,所述方法还包括:在测试所述最终的文本分类模型时,将测试数据分为两组,第一组测试数据中包含虚假关联可能会误导所述文本分类器的文本数据,第二组测试数据中包含虚假相关帮助所述文本分类器的文本数据。
9.一种非临时性计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现权利要求1-8中任一项所述方法的步骤。
10.一种电子设备,其特征在于,包括:
技术总结
本公开涉及一种文本分类方法、可读存储介质及电子设备,所述方法包括:根据待分类的文本数据,构建初始的文本分类模型;从所述初始的文本分类模型中抽取多个特征词;利用所述多个特征词和特征词匹配算法训练词分类器;计算每个所述特征词的特征相似度,确定每个所述特征词的分类特征为虚假相关词或真实相关词;利用所述词分类器从所述初始的文本分类模型中删除所述虚假相关词,得到最终的文本分类模型。与目前的现有技术相比,本方案的分类模型可以实现更鲁棒的分类,能够减小文本分类中虚假相关性的影响。
技术研发人员:秦小林,钱杨舸,张思齐,廖兴滨,陈敏,王乾垒,单靖杨
受保护的技术使用者:中科院成都信息技术股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!