一种通过深度学习技术实现表情识别的方法
本发明涉及表情识别方法,具体为一种通过深度学习技术实现表情识别的方法。
背景技术:
1、面部表情是一种常见的非语言交流形式,它能够有效的传达个人情感和意图;人类可以通过视觉获取他人的面部表情并通过大脑的分析了解他人的内心状态来达到交流的目的,随着科学繁荣和人工智能的发展,人们希望机器能够相对准确的识别面部表情达到人与机器间的交流,人脸表情自动识别在在改善人机交互、远程教育、辅助医疗、驾驶疲劳监测、营销辅助等方面都有着重要的研究价值和广泛的应用空间;
2、19世纪初,一些学者开始致力于人脸表情识别领域研究;1971年,心理学家ekman和他的伙伴深入研究了面部肌肉和不同表情之间的关系,将人脸表情化分为愤怒、厌恶、恐惧、高兴、悲伤和惊讶六类基本表情,并提出可以通过面部信号识别人脸表情;人脸表情识别过程可分为三个步骤:图像预处理,特征提取及人脸表情分类,如何有效的提取人脸表情特征是表情识别的关键步骤,此后研究的重点在就于人脸表情特征的提取;
3、但随着社会的快速发展,目前的表情识别的速度远远不急目前的市场的需求,且目前的识别方法具有冗余复杂、参数数量庞大,训练时间漫长等缺点,急需一种通过深度学习技术实现表情识别的方法来满足市场需求。
技术实现思路
1、本发明的目的在于提供一种通过深度学习技术实现表情识别的方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
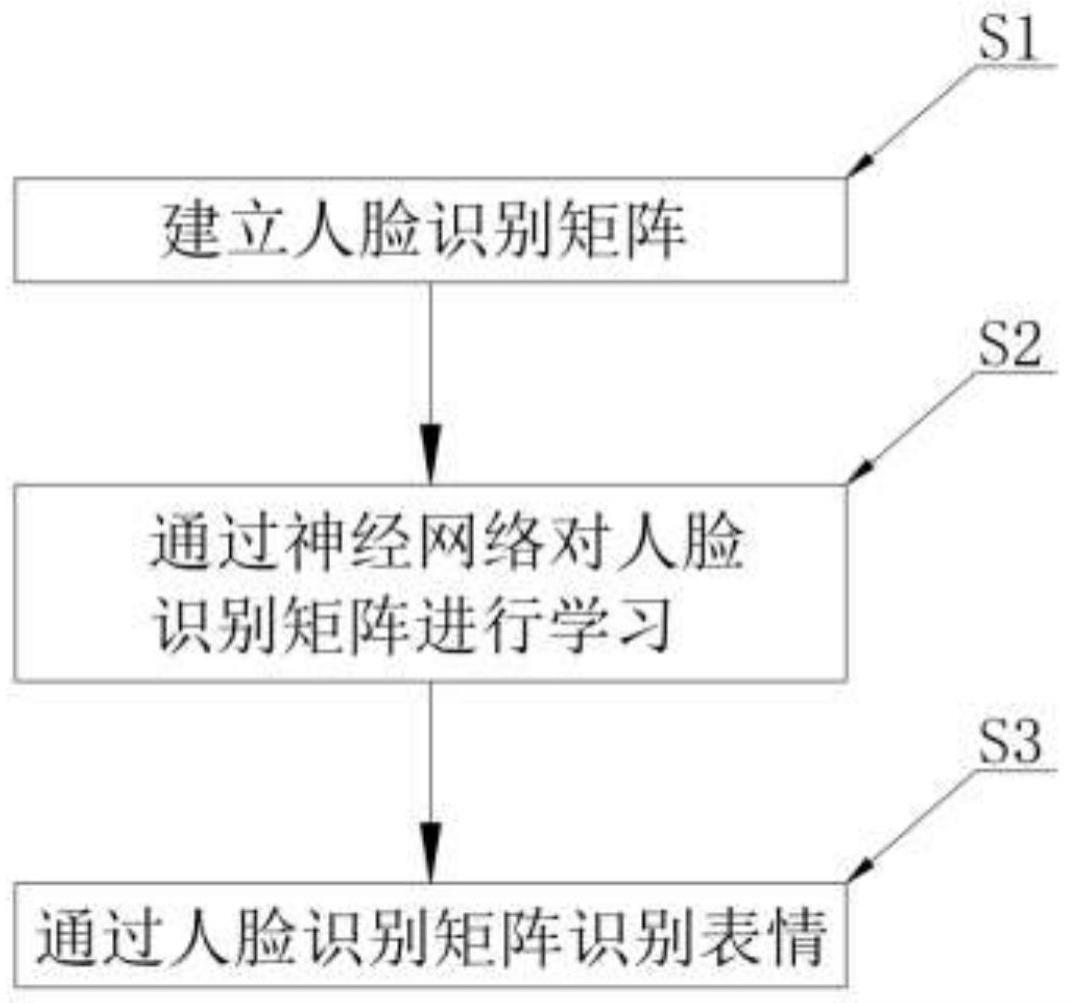
3、一种通过深度学习技术实现表情识别的方法,包括以下步骤:
4、s1,建立人脸识别矩阵,通过对图片进行灰度预处理,对图片建立人脸识别矩阵,包括以下步骤:
5、(1)首先对图片像素进行读取,每一个像素使用8个比特位,从而表示256个色阶;
6、(2)通过建立像素矩阵,通过对图片的横向及其竖向像素点进行读取,且每个像素均赋予一个色阶,从而建立由色阶组成的像素矩阵;
7、(3)建立人脸识别模型,通过神经网络引擎建立人脸识别模型,其中人脸识别模型标注对应的人脸特征点;
8、(4)通过将人脸识别模型中的人脸特征点与对应的色阶范围相匹配,从而将像素矩阵与人脸识别模型相结合建立人脸识别矩阵;
9、s2,通过神经网络对人脸识别矩阵进行学习,通过建立人脸表情数据库,数据库中共储存有7类表情,分别为:愤怒、厌恶、高兴、悲伤、恐惧、惊讶和中性;
10、通过将人脸识别模型中的人脸特征点与对应的愤怒、厌恶、高兴、悲伤、恐惧、惊讶和中性的特征点进行匹配,来使人脸识别矩阵推杆神经网络进行学习;
11、建立高效通道注意力网络模型,通过高效通道注意力网络模型为每个通道生成权重并学习其相关性,优先关注有用的信息,提升网络对主要特征的敏感度,同时降低模型的复杂度,通过权衡每个通道及其k近邻来实现局部跨通道交互,并通过自适应选择一维卷积核大小确定局部通道交互的覆盖范围;
12、自适应确定内核大小k:
13、
14、此处|t|odd表示最近的奇数t,并且我们将γ和b分别设为2和1,映射函数ψ使大的通道维度有更大的覆盖范围,反之亦然;
15、在线性瓶颈结构的深度卷积层后嵌入高效注意力机制,深度可分离卷积的深度卷积为表情特征提取部分,而在之后嵌入了高效通道注意力机制能够将深度卷积提取的特征权重重新加权,更着重提取重要的表情特征,接着在通过点卷积完成通道的缩放,并加入快捷连接层构成倒置残差结构,在减少网络结构的同时防止网络过拟合,最终基于线性瓶颈与倒置残差构成高效通道注意力网络;
16、通过高效通道注意力网络模型减少两层卷积层以适应表情特征的提取,该网络结构在减少网络计算量的同时提升网络识别率;
17、s3,通过人脸识别矩阵识别表情,通过已经进行学习的人脸识别矩阵来对图片中的表情进行识别;
18、通过使用中心损失函数完成表情的分类,通过使用centerloss用于加强类内距,通过使用softmaxloss用于改进类间的分离度,提高人脸表情的识别效果;
19、通过centerloss得到的类中心位置,centerloss根据下式更新类中心:
20、
21、
22、γ是学习率,t是迭代次数,δ是一个条件函数,如果条件满足则δ=1,如果条件不满足则δ=0;
23、通过centerloss损失函数学习步骤如下:输入数据为输入训练样本{fi},初始化的卷积层参数θc,最后的全连接层参数w,初始化的n类中心{cj|j=1,2,3...,n-1,n},学习率μt,超参数α,类中心学习率λ和迭代次数t←1,输出为参数θc,对所有样本训练时会循环以下步骤:
24、(1)计算总损失:l=ls+αlc
25、(2)对每个样本i计算反向传播误差:
26、(3)更新参数w:
27、(4)对每个中心j更新cj:
28、(5)更新θc:
29、(6)t←t+1。
30、本发明中,优选的,所述步骤s1中的对图片进行预处理包括,对图片的每个像素点的r,g,b三个分量进行读取,并且求出三个分量的平均值,且将求出的平均值赋予给这个像素的三个分量。
31、本发明中,优选的,所述步骤s1中的256个色阶能够标识0到255的色彩范围,其中0代表纯黑色,255代表纯白色。
32、本发明中,优选的,所述步骤s1中人脸特征点包括:头发、左眼、右眼、鼻子、嘴巴、左耳和右耳。
33、与现有技术相比,本发明的有益效果是:
34、该一种通过深度学习技术实现表情识别的方法,该方法通过首先建立人脸识别矩阵,通过人脸识别矩阵能够通过人脸识别模型中的人脸特征点与对应的色阶范围相匹配从而对图片表情进行识别,并采用centerloss损失函数减少相同表情的类内特征差异,softmaxloss扩大不同表情类间特征间距,使网络具有更好的特征判别效果,最终完成实时的人脸表情识别;稳定的识别出七种基本的表情,且能够更好的达到实时性要求,识别速度达到每秒90帧以上,处理效果较好,运行效率高,具有较好的鲁棒性。
技术特征:
1.一种通过深度学习技术实现表情识别的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种通过深度学习技术实现表情识别的方法,其特征在于:所述步骤s1中的对图片进行预处理包括,对图片的每个像素点的r,g,b三个分量进行读取,并且求出三个分量的平均值,且将求出的平均值赋予给这个像素的三个分量。
3.根据权利要求1所述的一种通过深度学习技术实现表情识别的方法,其特征在于:所述步骤s1中的256个色阶能够标识0到255的色彩范围,其中0代表纯黑色,255代表纯白色。
4.根据权利要求1所述的一种通过深度学习技术实现表情识别的方法,其特征在于:所述步骤s1中人脸特征点包括:头发、左眼、右眼、鼻子、嘴巴、左耳和右耳。
技术总结
本发明涉及轻量级表情识别方法技术领域,具体为一种通过深度学习技术实现表情识别的方法,包括以下步骤:建立人脸识别矩阵,通过对图片进行灰度预处理,对图片建立人脸识别矩阵;通过神经网络对人脸识别矩阵进行学习,通过建立人脸表情数据库,通过人脸识别矩阵识别表情,通过已经进行学习的人脸识别矩阵来对图片中的表情进行识别,本发明通过首先建立人脸识别矩阵,通过人脸识别矩阵能够通过人脸识别模型中的人脸特征点与对应的色阶范围相匹配从而对图片表情进行识别,稳定的识别出七种基本的表情,且能够更好的达到实时性要求。
技术研发人员:张红英,韩兴,吴亚东,黄湝洋,卢玉慧,梁贝宇,周瑜
受保护的技术使用者:西南科技大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!