残差神经网络在线训练架构及存储压缩与计算加速方法与流程
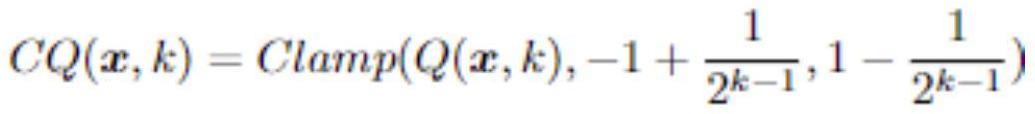
本发明属于计算机,尤其涉及一种残差神经网络在线训练架构及存储压缩与计算加速方法。
背景技术:
1、现有的深度残差神经网络在计算资源充足时表现出了强大的性能,但在计算资源有限时则不能表现出理想的效果,甚至当下大多数个人电脑都已经无法实现深度神经网络的有效训练。
2、深度残差神经网络的训练往往需要大批量数据作为并行输入,同时要求高精度的浮点数以保证训练的性能和精度。针对深度残差神经网络的在线训练的计算加速和压缩存储方法主要围绕着数据量化的算法的优化。
3、而应用常见的量化方式往往需要付出很大的性能下降的代价,这是因为在数据分布不平均时常用的离散化方法不能较好的表达出原数据的分布,造成离散化过程中的大量信息缺失。因此现有的残差神经网络算法大多使用量化算法来优化前向传播时的模型的调用,而针对残差神经网络的在线训练方法依旧有很多探索的空间。
技术实现思路
1、本发明目的在于提供一种残差神经网络在线训练架构及存储压缩与计算加速方法,以解决上述的技术问题。
2、为解决上述技术问题,本发明的一种残差神经网络在线训练架构及存储压缩与计算加速方法的具体技术方案如下:
3、一种残差神经网络在线训练架构,移除了批归一化运算模块,包括前向传播模块和反向传播模块两个部分,所述前向传播模块和反向传播模块均包含两个加法偏置bias,一个卷积层conv,一个乘法算子multiplier,和一个激活层relu,所述前向传播模块用于进行一个加法偏置bias、一个卷积层conv、一个乘法算子multiplier、一个加法偏置bias和一个激活层rel的运算,所述反向传播模块用于进行一个激活层rel、一个加法偏置bias、一个乘法算子multiplier、一个卷积层conv和一个加法偏置bias的运算。
4、本发明还公开了一种残差神经网络在线训练架构的存储压缩与计算加速方法,包括如下步骤:
5、步骤1:前向传播,经过加法偏置运算、卷积运算、乘法运算、加法偏置运算和激活运算后完成前行传播过程;
6、步骤2:反向传播,经过激活运算、加法偏置运算、乘法运算、一个卷积运算和加法偏置运算完成反向传播。
7、进一步地,所述步骤1包括如下具体步骤:
8、在第l个基本结构块中,输入的xl0先经过了一个加法运算后输出被整形化到ka位xl1;xl1进一步与量化到kw位的wl进行卷积运算,输出被整形化到ka位xl2;xl2与权重为γl相乘之后对位宽为ka+kγ-1的输出xl3在进行一次加法运算,得到位宽为ka+kγ-1的整形数xl4,最后xl4通过了激活函数relu并且再次使用qa量化到ka位。
9、进一步地,所述步骤2包括如下具体步骤:
10、步骤2.1:参数的量化;
11、步骤2.2:更新权重;
12、步骤2.3:浮点数整形化;
13、步骤2.4:根据不同参数的数据分布和作用制定离散化策略。
14、进一步地,所述步骤2.1包括如下具体步骤:
15、在反向传播时ke位整型数的第l层的误差el0输入;通过relu层后的计算得误差el1,其中bl2的梯度为经过el1量化函数qg(.)的结果;el2与xl2的乘积为乘法算子γl的梯度,对其使用qg(.)量化到kg位之后则获得了γl整形化的梯度同样的,得到卷积层权重wl的梯度
16、进一步地,所述步骤2.2包括如下具体步骤:
17、更新权重时,对所有参数使用相同的更新策略,对于学习率和参数z,权重更新值u及其整形化方案如公式所示:
18、
19、进一步地,所述参数z是乘法权重γ,偏置的权重b,或者卷积层的权重w。
20、进一步地,所述步骤2.3包括如下具体步骤:
21、采用的浮点数整形化函数方法如下:对于神经网络图像处理算法中的参数张量x,和离散化后的位宽k,使用函数将浮点数张量归一化后离散为定点数,cq(.)进一步将q(.)的结果的范围进行控制,限定在k位宽可以表达的空间之内,clamp(.)表示超出限定的边界的数值向左右边界取整,
22、
23、
24、使用的sq(.)是在cq(.)的基础上增加了放缩算子,该放缩算子scale(.)用最接近浮点数张量x绝对值最大值的定点数来估计浮点数张量x绝对值最大值,当x数值较小时引入scale(.)使得离散化估计的精度提升,
25、
26、
27、进一步地,所述步骤2.4包括如下具体步骤:
28、根据不同参数的数据分布和作用,乘法算子γl和其梯度使用了带有放缩算子的量化方法sq(.);加法算子bl及其梯度卷积权重wl及其梯度激活函数后的输出xl以及误差el使用量化方法cq(.)。
29、本发明的一种残差神经网络在线训练架构及存储压缩与计算加速方法具有以下优点:
30、本发明相较于传统32-bit浮点数的深度残差神经网络,能够大幅降低功耗,提升处理速度。更重要的是,因为删去了批归一化中的平方根运算,深度神经网络在线学习芯片的设计可以大大简化。除此之外,该方法已被证明在批量样本较少的小批量在线训练中更具优势。该发明专为降低网络训练中卷积和批归一化的高计算成本而设计,在资源有限设备上的在线训练中有广阔应用前景。
技术特征:
1.一种残差神经网络在线训练架构,其特征在于,移除了批归一化运算模块,包括前向传播模块和反向传播模块两个部分,所述前向传播模块和反向传播模块均包含两个加法偏置bias,一个卷积层conv,一个乘法算子multiplier,和一个激活层relu,所述前向传播模块用于进行一个加法偏置bias、一个卷积层conv、一个乘法算子multiplier、一个加法偏置bias和一个激活层rel的运算,所述反向传播模块用于进行一个激活层rel、一个加法偏置bias、一个乘法算子multiplier、一个卷积层conv和一个加法偏置bias的运算。
2.一种如权利要求1所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,包括如下步骤:
3.根据权利要求2所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,所述步骤1包括如下具体步骤:
4.根据权利要求2所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,所述步骤2包括如下具体步骤:
5.根据权利要求4所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,所述步骤2.1包括如下具体步骤:
6.根据权利要求4所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,所述步骤2.2包括如下具体步骤:
7.根据权利要求6所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,所述参数z是乘法权重γ,偏置的权重b,或者卷积层的权重w。
8.根据权利要求4所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,所述步骤2.3包括如下具体步骤:
9.根据权利要求4所述的残差神经网络在线训练架构的存储压缩与计算加速方法,其特征在于,所述步骤2.4包括如下具体步骤:
技术总结
本发明属于计算机技术领域,公开了一种残差神经网络在线训练架构及存储压缩与计算加速方法,移除了批归一化运算模块,包括前向传播模块和反向传播模块两个部分,所述前向传播模块和反向传播模块均包含两个加法偏置Bias,一个卷积层Conv,一个乘法算子Multiplier,和一个激活层ReLu。本发明能够大幅降低功耗,提升处理速度。更重要的是,因为删去了批归一化中的平方根运算,深度神经网络在线学习芯片的设计可以大大简化。除此之外,该方法已被证明在批量样本较少的小批量在线训练中更具优势。该发明专为降低网络训练中卷积和批归一化的高计算成本而设计,在资源有限设备上的在线训练中有广阔应用前景。
技术研发人员:李国齐,杨玉宽,裴京,陈恒努,孟子阳
受保护的技术使用者:之江实验室
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!