一种长江流域关键水位站点的水位数据预警方法与流程
本发明涉及基于大数据集算法分析的水位数据预警方法,具体地指一种长江流域关键水位站点的水位数据预警方法。
背景技术:
1、长江流域梯级水库的建设除了能起到可靠的防洪价值外,还能带来巨大的社会经济效益,如发电、航运、供水等。在这一巨大价值的背后,梯级水库防洪的可靠性和安全性以及发电的可靠性和可调控性就显得尤为重要。因此,精细准确的提供长江流域各站点的水位监测数据,对各水库积极开展预报和调度应用有着至关重要的作用。然而,目前对于站点数据的日常测量并非百分百准确,存在水位站自身装置损坏引起的测量偏差,周边人为干扰导致测量错误状况等。鉴于此,借助大数据分析算法研究长江流域关键水位站点间的数据相关性,并对站点数据测量制定合理的预警方法,对于指导提升数据的可靠性有重要价值,已成为提高水文预报精度和调度决策水平的应用新形势。
技术实现思路
1、本发明的目的在于克服上述不足,提供一种长江流域关键水位站点的水位数据预警方法,用于分析邻近水位站点间水位相关性联系,提高站点测量的数据质量,为提高水位数据测量准确性提供可靠依据和重要参考。
2、本发明为解决上述技术问题,采取的技术方案为:
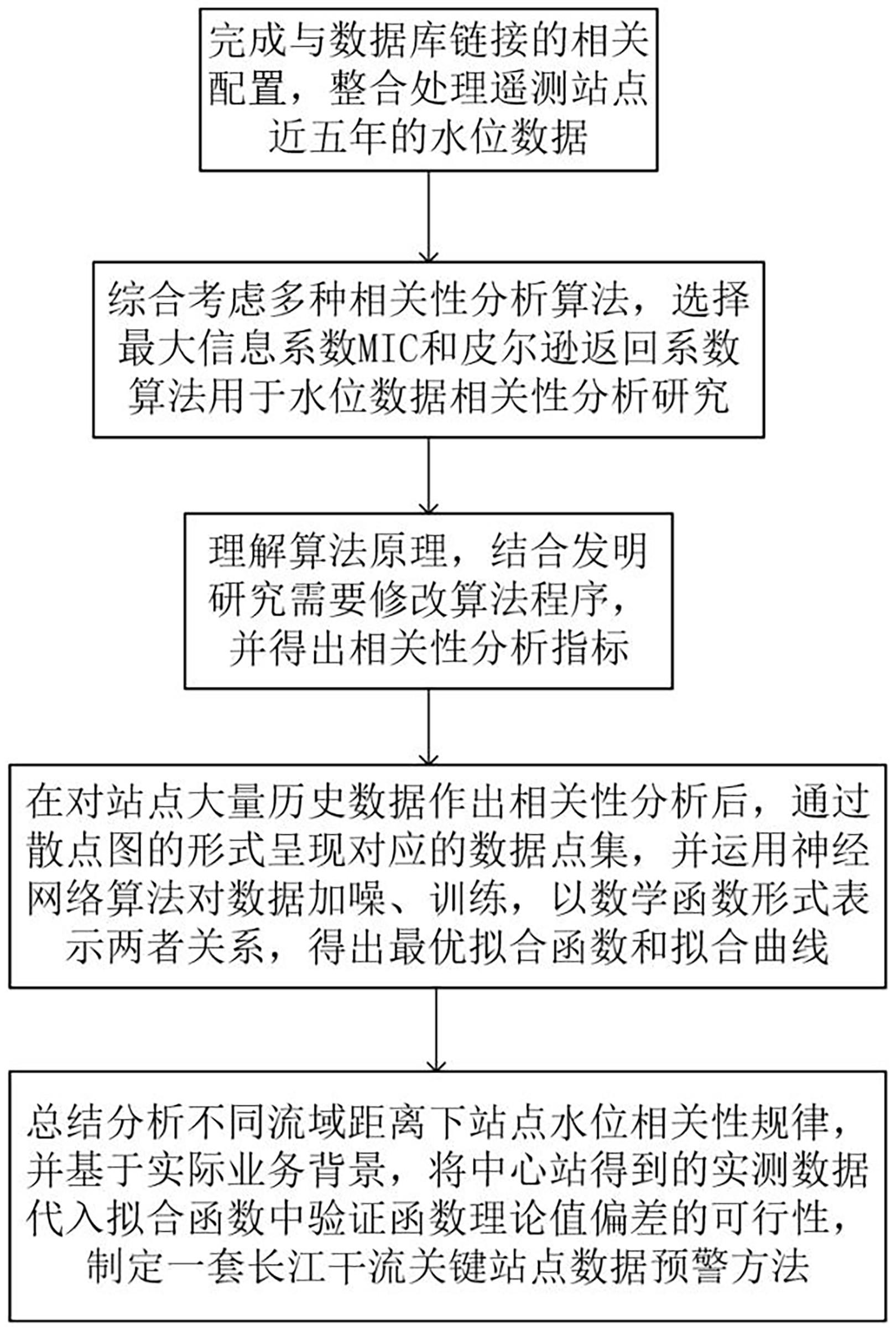
3、一种长江流域关键水位站点的水位数据预警方法,它包括如下步骤:
4、步骤1:结合长江流域不同时期的水流、水位特点,在汛期和非汛期两个场景对关键水位站点的水位历史数据进行挖掘、筛选以及整合处理,剔除少量明显偏差过大的无效数据,并把剩余有效数据作研究分析;
5、步骤2:利用最大信息系数mic(maximal information coefficient)和皮尔逊算法不断划分散点频率网格区间,计算不同网格区间对应的互信息值,分析两个场景下关键水位站点的数据关系,找出数据相关性联系;
6、步骤3:利用神经网络算法对水位数据加噪、训练,以数学函数形式表示站点间关系,得出最优拟合函数并画出拟合曲线;
7、步骤4:基于实际业务背景,将中心站得到的实测数据代入拟合函数中验证函数理论值偏差的可行性,并制定一套长江流域关键站点数据预警方法,用以提高水文预报精度,减少工作人员人工校验测站的次数。
8、进一步地,步骤1中,前期在jupyterlab上完成与水调数据库链接的相关配置,在python中实现水调数据库的连接,并对水位站点近五年的水位数据分不同场景进行整合处理,通过数据整合过程,筛选、剔除少量明显偏差过大值,剩余有效数据作为发明研究。
9、进一步地,步骤2中,查阅相关文献资料后,比较皮尔逊系数、斯皮尔曼系数、spearnman相关系数多种相关性分析算法后,综合考虑广泛性(可识别线性和非线性函数关系)、公平性(样本量足够大)、鲁棒性指标,选择mic最大信息系数和皮尔逊系数用于两站点水位数据相关性分析研究,其算法过程如下,
10、针对两个变量之间的关系,将其离散在x,y二维空间中,并使用散点图来表示,将当前二维空间在x,y方向分别划分为一定的区间数,然后查看当前的散点在各个方格中落入的情况,计算联合概率;mic的计算公式如下:
11、
12、
13、上式中,mic(x;y)和mic(x;y)均为最大信息系数计算公式,a,b是在x,y方向上的划分格子的个数,本质上就是对x,y方向上的网格分布,b是变量,其大小设置是数据量的0.6次方;其中i(x;y)为计算的互信息值,其计算公式如下:
14、
15、
16、上式中,p(x,y)为变量x和y之间的联合概率,边缘p(x),p(y)为对应x,y的概率;考虑到联合概率计算相对来说比较麻烦,以散点个数代表对应的联合概率,互信息值计算近似等于i(x,y);i(x,y)和i(x,y)均为互信息值计算公式;
17、算法计算分三个步骤展开:
18、(1)给定i、j,对x、y构成的散点图进行i列j行网格化,并求出最大的互信息值;
19、(2)对最大的互信息值进行归一化;
20、(3)选择不同尺度下互信息的最大值作为mic值
21、以上mic算法包括散点图中网格化的处理过称、不同尺度下最大互信息值计算和归一化处理;在vscode上用python语言中对要实现的功能编程,并结合自己研究需求修改算法程序,同时在最大信息系数mic值算法程序执行过程中,对散点图表示后,增加皮尔逊相关系数pearson的计算用以表示二者相关性的程度,以上算法均在python中的minepy、pandas类库中实现。
22、进一步地,步骤3中,在对大量历史数据作出相关性分析后,通过散点图的形式呈现对应数据点集,运用神经网络算法对数据加噪、训练,以数学函数形式表示两者关系,得出最优拟合函数和拟合曲线,用以分析数据相关性并提高相关站点的数据质量;算法基本过程是:
23、通过定义一个同y长度一样的预测值y_mat,与实际值y做损失,使均方损失(均方差)最小,并定义均方损失函数和优化器sgd函数;通过散点图的描绘,构建函数表达式y_mat=xw+b,经算法更新,训练、测试,最终得到最优参数值。
24、进一步地,步骤4中,在确定算法分析得到的拟合函数理论值裕度范围后,结合具体遥测人员业务工作,将算法分析的函数拟合理论值作为数据校验值,制定一套长江流域关键站点数据预警方法,以提高水文预报精度,减少工作人员现场人工校验测站的次数。
25、本发明的有益效果:
26、1.本发明所述的一种长江流域关键水位站点的水位数据预警方法,能够在不影响、改变业务系统正常运行的前提下,利用大数据集算法分析流域水位站点间的水位相关性,并对数据测量错误产生预警,及时调整数据精度,提升相关站点的数据质量。
27、2.本发明结合水情遥测业务实际需求,依托软件、算法技术,适用长江流域大部分水情遥测系统,只需在软件部署算法程序,功能应用速度快。
28、3.本发明使用python语句实现大量历史水位数据的整合,相关性分析算法和神经网络函数拟合应用于长江流域关键水位站点;其基于实际业务背景,制定了一套长江流域关键水位站点水位数据预警方法,并部署于现有软件中,最后在汛期和非汛期时期验证预警方法的有效性;整个发明既得出流域站点水位数据的相关性规律,又能提高数据测量质量,大大减少工作人员进入现场校验数据的次数。
29、4.本发明通过大数据算法,分析不同流域距离下站点水位相关性规律,并基于实际业务背景提高业务工作效率,制定一套长江流域关键水位站点数据预警方法,用以提高水文预报精度和调度水平,减少工作人员现场人工校验测站的次数。
30、5.本发明能够用于分析邻近水位站点间水位数据相关性联系,提高站点测量的数据质量,为提高水位数据测量准确性提供可靠依据和重要参考。
技术特征:
1.一种长江流域关键水位站点的水位数据预警方法,其特征在于:它包括如下步骤:
2.根据权利要求1所述一种长江流域关键水位站点的水位数据预警方法,其特征在于:步骤1中,前期在jupyterlab上完成与水调数据库链接的相关配置,在python中实现水调数据库的连接,并对水位站点近五年的水位数据分不同场景进行整合处理,通过数据整合过程,筛选、剔除少量明显偏差过大值,剩余有效数据作为发明研究。
3.根据权利要求1所述一种长江流域关键水位站点的水位数据预警方法,其特征在于:步骤2中,查阅相关文献资料后,比较皮尔逊系数、斯皮尔曼系数、spearnman相关系数多种相关性分析算法后,综合考虑广泛性(可识别线性和非线性函数关系)、公平性(样本量足够大)、鲁棒性指标,选择mic最大信息系数和皮尔逊系数用于两站点水位数据相关性分析研究,其算法过程如下,
4.根据权利要求1所述一种长江流域关键水位站点的水位数据预警方法,其特征在于:步骤3中,在对大量历史数据作出相关性分析后,通过散点图的形式呈现对应数据点集,运用神经网络算法对数据加噪、训练,以数学函数形式表示两者关系,得出最优拟合函数和拟合曲线,用以分析数据相关性并提高相关站点的数据质量;算法基本过程是:
5.根据权利要求1所述一种长江流域关键水位站点的水位数据预警方法,其特征在于:步骤4中,在确定算法分析得到的拟合函数理论值裕度范围后,结合具体遥测人员业务工作,将算法分析的函数拟合理论值作为数据校验值,制定一套长江流域关键站点数据预警方法,以提高水文预报精度,减少工作人员现场人工校验测站的次数。
技术总结
本发明公开一种长江流域关键水位站点的水位数据预警方法,包括完成与数据库链接的相关配置,对水位站水位数据进行整合处理;调整软件和算法适用的环境变量及相关配置,定义邻近站点水位数据变量,在vscode上用python语言中对要实现的算法功能编程,利用大数据集算法最大信息系数MIC和皮尔逊返回系数计算不同网格区间对应的互信息值,分析两个场景(汛期和非汛期)下邻近水位站点的相关性;运用神经网络算法对数据加噪、训练,以数学函数形式表示两者关系,得出最优拟合函数和拟合曲线;最后制定关键站点预警方法;本发明能够用于分析邻近水位站间数据相关性,有效提高数据测量质量,对于保障流域水库防洪、提高水文预报精度和调度决策水平具有重要意义。
技术研发人员:涂杰,鲍正风,周保红,张玉松,刘帅,洪福鑫,欧思程,税海霞,杨锦辉,赵海波
受保护的技术使用者:中国长江电力股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!