一种面向停车行为实验的城市路网仿真模型构建方法
本发明涉及交通仿真领域,尤其是涉及一种面向停车行为实验的城市路网仿真模型构建方法。
背景技术:
1、针对停车难的问题,多项针对城市停车资源配置和路网交通运行管控的优化措施相继出台。目前国内存在停车现存的供给能力短缺、治理水平不高、市场化进程滞后等问题,亟需优化停车信息管理、推广智能化停车服务、鼓励停车资源共享等。
2、由于现有交通系统分析理论缺乏对停车行为和交通状态的协同考虑,导致现有措施取得的效果不佳,直接制约了城市进一步提升品质和管理服务水平。对于出行者个体层面,缺乏精细化、个性化的停车指引方案,出行者无法有效判断自己的停车行为对于自己以及整个停车系统产生的影响。而对于整个停车系统来说,缺乏对于系统的统计性指标与建模优化方案。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种面向停车行为实验的城市路网仿真模型构建方法,通过构建城市路网仿真模型,在微观上反映用户面临不同交通环境的不同停车寻位决策行为,同时探究了停车寻位行为与道路交通情况的交互作用与相互影响机制,协同考虑了停车行为与交通状态对于停车系统的作用。
2、本发明的目的可以通过以下技术方案来实现:
3、一种面向停车行为实验的城市路网仿真模型构建方法,所述的方法包括以下步骤:
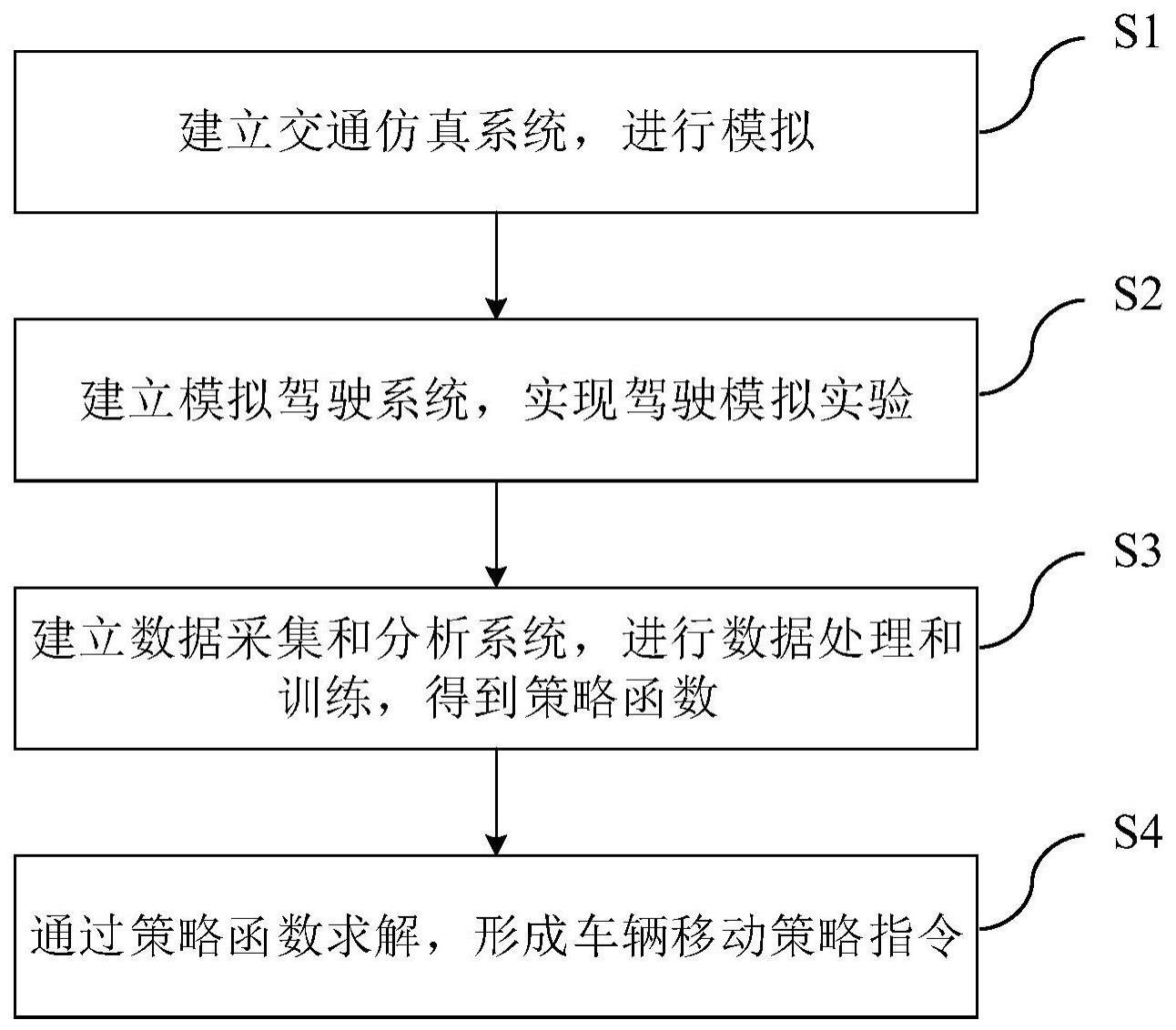
4、s1、建立交通仿真系统,对城市路网交通流和路边停车系统进行模拟;
5、s2、建立模拟驾驶系统,在s1中的交通仿真系统中实现驾驶环境模拟,并提供路况实时导航,以第一视角完成停车寻位模拟实验;
6、s3、建立数据采集和分析系统,对s2中的停车寻位模拟实验的轨迹数据和全局交通信息数据进行实时筛选采集,并转化成专家轨迹数据集,将专家轨迹数据集输入多种算法,进行数据的处理和模型训练,获得策略函数;
7、s4、通过策略函数对车辆信息和全局交通信息进行求解,形成一个单独的动作指令,指导车辆下一步移动策略。
8、进一步地,所述的步骤s1具体为:
9、s101、选取目标路网,使用游戏引擎进行建模,将路网信息提取为由点和边组成的图结构,以点和边为基础单位存储城市交通规则信息;
10、s102、将模拟城市路网交通流抽象为具体的车辆,赋予其车辆信息,通过车辆与路网节点的动态交互建立完整的城市路网交通流;
11、s103、以路段为基本操作单元,路段特征信息为交通规则信息以及城市路网交通流实时信息,建立一个逻辑主体作为主要交通规则载体,赋予路段可执行操作空间;
12、s104、为模拟城市路网交通流的车辆单元赋予寻路算法,形成多元的复杂城市路网交通流;
13、s105、为模拟城市路网交通流的车辆单元赋予车周障碍物检测功能,以游戏引擎的射线探测机制为基础制作弧形探测面,通过参数设置控制扇形探测面的射线密度、探测角度范围循环和控制中的射线层数。
14、进一步地,所述的步骤s102中的车辆信息包括车辆位置信息、车辆速度信息和车辆体积信息。
15、进一步地,所述的步骤s104中的寻路算法包括全局最优择路算法、局部最优择路算法和特定人群偏好式择路算法;所述的特定人群偏好式择路算法使用强化学习得到策略函数,逐帧计算得出路径选择参数。
16、进一步地,所述的步骤s2具体为:
17、s201、构建基本的加速度控制框架,实现通过键盘操作驾驶员所驾驶的车辆行驶方向和行驶速度;
18、s202、经过反复真人实验调试驾驶员车辆驾驶相关变量,使车辆驾驶接近真实情况;
19、s203、基于游戏引擎已有的物理实体模拟功能,实现驾驶员车辆和s1中建立的交通仿真系统中的物体碰撞的检测以及特殊边界情况的处理;
20、s204、在驾驶员车辆上配备游戏引擎导航摄像头的自动跟随功能;
21、s205、通过分层可视化将实验员所驾驶的车辆位置在地图上进行放大显示,实时更新地图上的车流显示信息,实现目标地点自动指引计算。
22、进一步地,所述的步骤s201中的键盘操作具体为:w键赋予车辆前进的加速度,s键赋予车辆与当前车头方向相反的加速度,a键控制车辆向左转动,d键控制车辆向右转动。
23、进一步地,所述的步骤s3具体为:
24、s301、通过城市路网交通流获取实时的全局交通信息,以交通规则为基本要求进行数据正确性检测,将数据进行预处理形成以轨迹为基本数据格式的数据测试集;
25、s302、通过匹配实验中所有车辆的坐标与路段及停车位的坐标范围,统计得出各路段的实时交通流量及停车情况信息,从而构建全局特征信息;
26、s303、通过匹配实验者操控的车辆的实时坐标与路段坐标范围,实时获取受控车辆所在路段的位置信息,保存信息构建专家轨迹数据集;
27、s304、将获得的轨迹数据输入多种算法进行模型训练,获得策略函数。
28、进一步地,所述的多种算法包括聚类算法、逆强化学习算法和强化学习算法。
29、进一步地,所述的步骤s4具体为:将策略函数整体存储于后台文件中,当交通模拟仿真流中的车辆到达决策路口时自动将当前车辆信息及全局交通信息作为输入项输入策略函数中求解,所得解形成一个单独的动作指令指导该车辆下一步移动策略。
30、进一步地,所述的动作指令包括直行指令、左转指令、右转指令和掉头指令。
31、与现有技术相比,本发明具有以下有益效果:
32、一、本发明采用高性能游戏引擎unity来构建城市路网仿真模型,全还原现实场景,使实验者做出的决策动作无限接近现实情况,微观上反映了用户面临不同交通环境的不同停车寻位决策行为,极大的方便了交通道路模式领域的系统建模和相关研究;且unity仿真模型可以获取实时的全局信息数据,数据收集不但延时仅在60毫秒之内,而且信息获取非常齐全准确。
33、二、本发明以轨迹形式输出车辆的行驶路径,该轨迹模式适用于后期的多种算法处理,包括但不限于聚类算法、逆强化学习算法、强化学习算法,有助于对交通道路模式进行系统建模和研究。
34、三、本发明可适用于各种的交通道路环境,包括平面交通和立体交通,有利于各种情况的交通道路模拟及数据采集。
技术特征:
1.一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的方法包括以下步骤:
2.根据权利要求1所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的步骤s1具体为:
3.根据权利要求2所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的步骤s102中的车辆信息包括车辆位置信息、车辆速度信息和车辆体积信息。
4.根据权利要求2所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的步骤s104中的寻路算法包括全局最优择路算法、局部最优择路算法和特定人群偏好式择路算法;所述的特定人群偏好式择路算法使用强化学习得到策略函数,逐帧计算得出路径选择参数。
5.根据权利要求1所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的步骤s2具体为:
6.根据权利要求5所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的步骤s201中的键盘操作具体为:w键赋予车辆前进的加速度,s键赋予车辆与当前车头方向相反的加速度,a键控制车辆向左转动,d键控制车辆向右转动。
7.根据权利要求1所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的步骤s3具体为:
8.根据权利要求7所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的多种算法包括聚类算法、逆强化学习算法和强化学习算法。
9.根据权利要求1所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的步骤s4具体为:将策略函数整体存储于后台文件中,当交通模拟仿真流中的车辆到达决策路口时自动将当前车辆信息及全局交通信息作为输入项输入策略函数中求解,所得解形成一个单独的动作指令指导该车辆下一步移动策略。
10.根据权利要求9所述的一种面向停车行为实验的城市路网仿真模型构建方法,其特征在于,所述的动作指令包括直行指令、左转指令、右转指令和掉头指令。
技术总结
本发明涉及一种面向停车行为实验的城市路网仿真模型构建方法,包括以下步骤:S1、建立交通仿真系统,对城市路网交通流和路边停车系统进行模拟;S2、建立模拟驾驶系统,实现驾驶环境模拟,并提供路况实时导航,以第一视角完成停车寻位模拟实验;S3、建立数据采集和分析系统,对停车寻位模拟实验的轨迹数据和全局交通信息数据进行实时筛选采集,并转化成专家轨迹数据集输入多种算法,进行数据的处理和模型训练,获得策略函数;S4、通过策略函数对车辆信息和全局交通信息进行求解,形成一个单独的动作指令,指导车辆下一步移动策略。与现有技术相比,本发明具有接近现实情况、数据延迟低、为后续研究提供支持等优点。
技术研发人员:赵聪,杨海晏,陈菁,唐艺嘉,杜豫川
受保护的技术使用者:同济大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!