基于对偶注意力的视频关系预测方法、装置、设备和介质与流程
本发明涉及视频处理,特别涉及一种基于对偶注意力的视频关系预测方法、装置、设备和介质。
背景技术:
1、如今静态图像上的视觉关系检测已经得到了广泛的研究,但相比静态图像,视频中的关系检测要更加复杂多变。视觉关系检测问题最初主要解决对于关系的巨大标签空间建模问题。一些研究还尝试了修剪不太可能的关系候选来提高效率,或者改善训练对象来提升效率,目前现有技术对于视频的视觉关系研究遵循三阶段检测框架,即检测物体轨迹、物体关系预测、贪婪关系关联三个阶段。然而,目前的研究仅在于如何更好的提取目标对象的特征或识别目标对象的轨迹,忽略了关系组件(如谓词)的预测结果对关系预测结果的影响。
2、因此,如何精准预测视频中目标对象的动作谓词和位置谓词,并根据动作谓词和位置谓词预测目标对象的动作和位置之间的关系,以获取高置信度且符合语法表达形式的关系预测结果是目前需要解决的问题。
技术实现思路
1、本发明提供一种基于对偶注意力的视频关系预测方法、装置、设备和介质,旨在精准预测视频中目标对象的动作谓词和位置谓词,并根据动作谓词和位置谓词预测目标对象的动作和位置之间的关系,以获取高置信度且符合语法表达形式的关系预测结果,实现了对关系预测技术的优化。
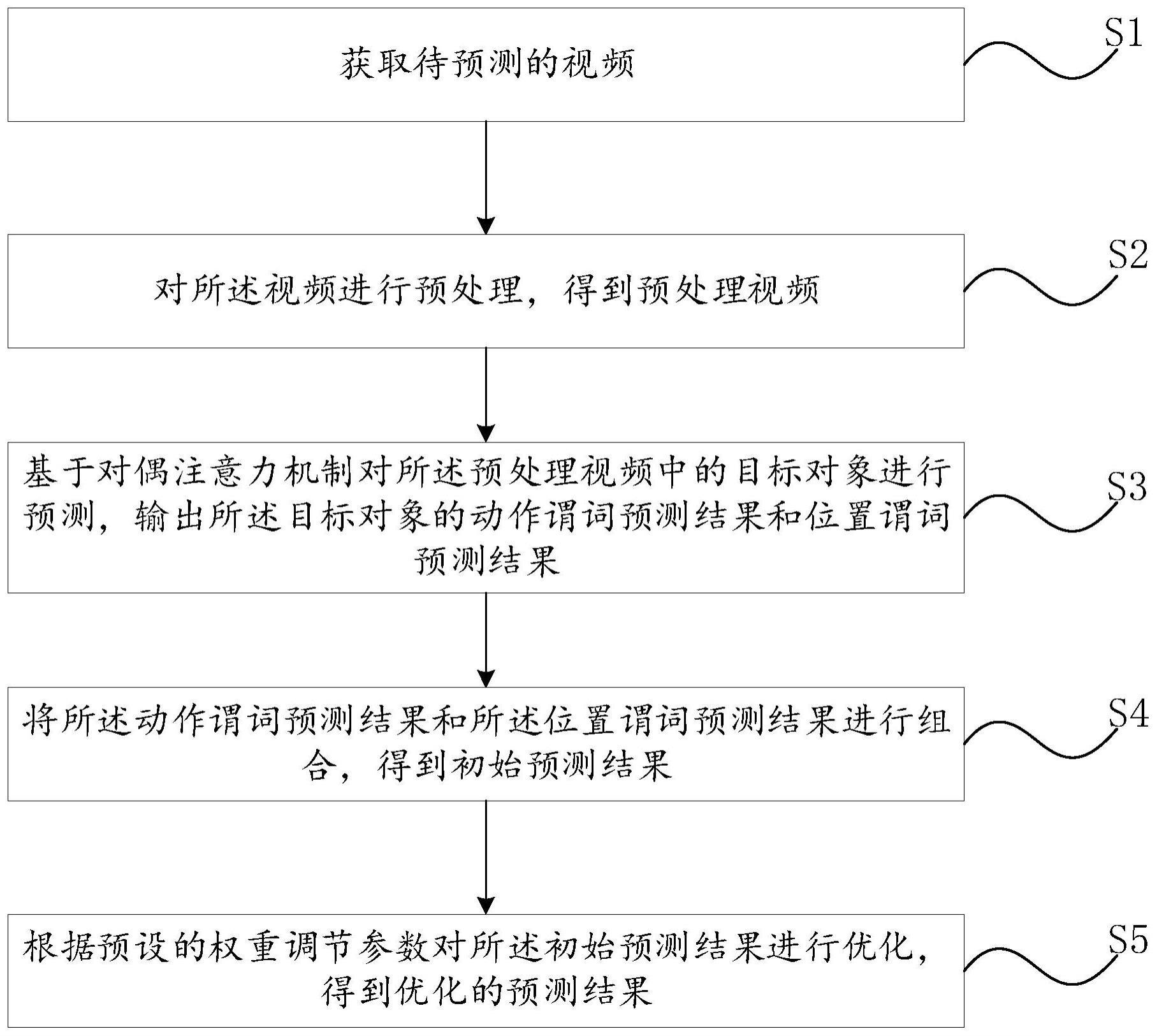
2、为了实现上述发明目的,本发明第一方面提出一种基于对偶注意力的视频关系预测方法,所述方法包括:
3、获取待预测的视频;
4、对所述视频进行预处理,得到预处理视频;
5、基于对偶注意力机制对所述预处理视频中的目标对象进行预测,输出所述目标对象的动作谓词预测结果和位置谓词预测结果;
6、将所述动作谓词预测结果和所述位置谓词预测结果进行组合,得到初始预测结果;
7、根据预设的权重调节参数对所述初始预测结果进行优化,得到优化的预测结果。
8、进一步地,所述对所述视频进行预处理,得到预处理视频,包括:
9、对所述视频进行去隔行处理,得到第一视频;
10、对所述第一视频进行图像重采样处理,得到第二视频;
11、对所述第二视频进行降噪处理,得到预处理视频。
12、进一步地,对偶注意力机制包括编码组件和解码组件,所述基于对偶注意力机制对所述预处理视频中的目标对象进行预测,输出所述目标对象的动作谓词预测结果和位置谓词预测结果,包括:
13、将所述预处理视频分解为一组重叠的片段,并在每个所述片段上生成目标对象的轨迹建议;
14、对所述轨迹建议进行特征提取,得到所述目标对象的特征数据,其中,所述特征数据包括轨迹特征、运动特征、视觉特征;
15、根据所述轨迹特征、所述运动特征以及所述视觉特征进行关系建模,得到关系特征;
16、采用关联规则算法结合所述关系特征将所述轨迹特征、所述运动特征、所述视觉特征进行合并,输出所述目标对象的动作谓词预测结果和位置谓词预测结果。
17、进一步地,所述将所述动作谓词预测结果和所述位置谓词预测结果进行组合,得到初始预测结果,包括:
18、基于字符串拼接将所述动作谓词预测结果和所述位置谓词预测结果进行组合,得到初始预测结果。
19、进一步地,所述根据预设的权重调节参数对所述初始预测结果进行优化,得到优化的预测结果,包括:
20、读取预设的权重调节参数,其中,所述权重调节参数包括动作谓词调节参数和位置谓词调节参数;
21、根据所述动作谓词调节参数和所述位置谓词调节参数对所述初始预测结果进行加权计算,获取加权分值最高的计算结果;
22、根据所述计算结果输出优化的预测结果。
23、本申请还提供一种基于对偶注意力的视频关系预测,其特征在于,所述装置包括:
24、获取模块,用于获取待预测的视频;
25、处理模块,用于对所述视频进行预处理,得到预处理视频;
26、预测模块,用于基于对偶注意力机制对所述预处理视频中的目标对象进行预测,输出所述目标对象的动作谓词预测结果和位置谓词预测结果;
27、组合模块,用于将所述动作谓词预测结果和所述位置谓词预测结果进行组合,得到初始预测结果;
28、优化模块,用于根据预设的权重调节参数对所述初始预测结果进行优化,得到优化的预测结果。
29、进一步地,所述预测模块,包括:
30、分解单元,用于将所述预处理视频分解为一组重叠的片段,并在每个所述片段上生成目标对象的轨迹建议;
31、提取单元,用于对所述轨迹建议进行特征提取,得到所述目标对象的特征数据,其中,所述特征数据包括轨迹特征、运动特征、视觉特征;
32、建模单元,用于根据所述轨迹特征、所述运动特征以及所述视觉特征进行关系建模,得到关系特征;
33、关联单元,用于采用关联规则算法结合所述关系特征将所述轨迹特征、所述运动特征、所述视觉特征进行合并,输出所述目标对象的动作谓词预测结果和位置谓词预测结果。
34、进一步地,所述优化模块,包括:
35、读取单元,用于读取预设的权重调节参数,其中,所述权重调节参数包括动作谓词调节参数和位置谓词调节参数;
36、计算单元,用于根据所述动作谓词调节参数和所述位置谓词调节参数对所述初始预测结果进行加权计算,获取加权分值最高的计算结果;
37、输出单元,用于根据所述计算结果输出优化的预测结果。
38、本申请还提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述任一项所述的基于对偶注意力的视频关系预测方法的步骤。
39、本申请还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述任一项所述的基于对偶注意力的视频关系预测方法的步骤。
40、有益效果:获取待预测的视频,对所述视频进行预处理,以增强所述视频的图像,并去除干扰信息,得到预处理视频;基于对偶注意力机制对所述预处理视频中的目标对象进行预测,以精准预测视频中的目标对象的动作谓词和位置谓词,输出所述目标对象的动作谓词预测结果和位置谓词预测结果;将所述动作谓词预测结果和所述位置谓词预测结果进行组合,得到语义连贯的初始预测结果;根据预设的权重调节参数对所述初始预测结果进行优化,使得所述初始预测结果中的所述动作谓词和所述位置谓词的组合的表述与语法表达形式相符,进而得到高置信度且符合语法表达形式的关系预测结果,实现了对关系预测技术的优化。
技术特征:
1.一种基于对偶注意力的视频关系预测方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于对偶注意力的视频关系预测方法,其特征在于,所述对所述视频进行预处理,得到预处理视频,包括:
3.根据权利要求1所述的基于对偶注意力的视频关系预测方法,其特征在于,对偶注意力机制包括编码组件和解码组件,所述基于对偶注意力机制对所述预处理视频中的目标对象进行预测,输出所述目标对象的动作谓词预测结果和位置谓词预测结果,包括:
4.根据权利要求1所述的基于对偶注意力的视频关系预测方法,其特征在于,所述将所述动作谓词预测结果和所述位置谓词预测结果进行组合,得到初始预测结果,包括:
5.根据权利要求1所述的基于对偶注意力的视频关系预测方法,其特征在于,所述根据预设的权重调节参数对所述初始预测结果进行优化,得到优化的预测结果,包括:
6.一种基于对偶注意力的视频关系预测装置,其特征在于,所述装置包括:
7.根据权利要求6所述的基于对偶注意力的视频关系预测装置,其特征在于,所述预测模块,包括:
8.根据权利要求6所述的基于对偶注意力的视频关系预测装置,其特征在于,所述优化模块,包括:
9.一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至5中任一项所述的基于对偶注意力的视频关系预测方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至5中任一项所述的基于对偶注意力的视频关系预测方法的步骤。
技术总结
本发明属于视频处理技术领域,特别是涉及一种基于对偶注意力的视频关系预测方法、装置、设备和介质,其中,方法包括:获取待预测的视频;对视频进行预处理,得到预处理视频;基于对偶注意力机制对预处理视频中的目标对象进行预测,输出目标对象的动作谓词预测结果和位置谓词预测结果;将动作谓词预测结果和位置谓词预测结果进行组合,及根据预设的权重调节参数进行优化,得到优化的预测结果。本发明通过对视频进行分析预测,精准预测视频中的目标对象的动作谓词和位置谓词,并将动作谓词和位置谓词进行组合及优化,进而获取高置信度且符合语法表达形式的预测结果,实现了对视频中目标对象的动作和位置关系预测技术的优化。
技术研发人员:狄东林,赵晨旭,茹彬鑫,曹峰,季聪
受保护的技术使用者:深圳市识渊科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!