一种积分系统中基于半监督学习的DPI数据分类方法与流程
本发明涉及互联网及积分领域,特别是涉及一种积分系统中基于半监督学习的dpi数据分类方法。
背景技术:
1、随着大数据的蓬勃发展,针对获得的海量dpi数据,各大电信运营商的大数据研发团队对此进行了不同程度的深入挖掘研究,其中涉及的关键技术有url分类和文本分类。
2、对于海量的dpi数据分类,单独使用url分类或文本分类,都存在较为明显的缺陷。鉴于此,最新的dpi数据分类选择基于url分类算法和文本分类算法相结合的dpi数据分类方法,实现对超大规模的用户上网记录实时、高效、准确地分类。
3、dpi数据分类的传统方法是根据url中的不同字段设计不同的逻辑进行分类。这一类方法分类过程中分析工作繁琐,分析主要依赖人工,自动化程度低。
4、最新的一种典型借助机器学习技术进行dpi数据分类方法流程中,先基于url分类器对dpi数据进行分类,若url分类器对待分类的dpi数据中的url分类成功,则直接返回分类结果;若分类失败,则提取该dpi数据中的url对应的网页正文,然后用文本分类器对其进行分类。这一类方法,对文本分类的过程中,为保证模型分类效果,需要大量的标注样本,人工标注成本巨大。而且,分类过程中需要爬取dpi数据所对应的网页内容,也会影响效率,增加成本。
技术实现思路
1、本发明提供了一种积分系统中基于半监督学习的dpi数据分类方法。本发明通过借助积分系统中大量未标注的dpi数据,在保证分类效果的同时,提供了n-gram特征向量生成和语义特征向量生成,并且通过生成两种不同维度的特征,构建两类模型,进行基于不同特征予以协同训练,扩充训练样本。
2、本发明包含数据预处理模块、数据标注模块、url特征生成模块、协同训练模块、dpi数据分类模型训练模块以及dpi数据分类模块。
3、1、数据预处理模块:用于对dpi数据进行预处理,清洗无效的dpi数据,包含但不限于字段缺失数据、不能体现用户行为的css, js, gif链接等。
4、2、数据标注模块:用于对训练dpi数据中的少量数据进行标注,所述标注的方式包含但不限于采集典型网站的url,人工标注等方式。
5、3、url特征生成模块:用于构建url字符串n-gram特征和url语义特征,所述url字符串n-gram特征为url中多个连续字符的出现、次数及其位置中体现出的特征,所述url语义特征为url中出现的词通过词向量所体现出的语义特征。
6、4、协同训练模块:用于基于少量标注的dpi数据和大量未标注的dpi数据,使用url字符串n-gram特征和url语义特征生成2个模型进行协同训练,并扩充标注数据集。
7、5、dpi数据分类模型训练模块:用于使用协同训练生成的2个模型和扩充的数据集,训练最终dpi数据分类模型。
8、6、dpi数据分类模块:用于使用训练完毕的dpi数据分类模型,对新输入的dpi数据进行分类。
9、一种积分系统中基于半监督学习的dpi数据分类方法,包括以下功能和步骤:
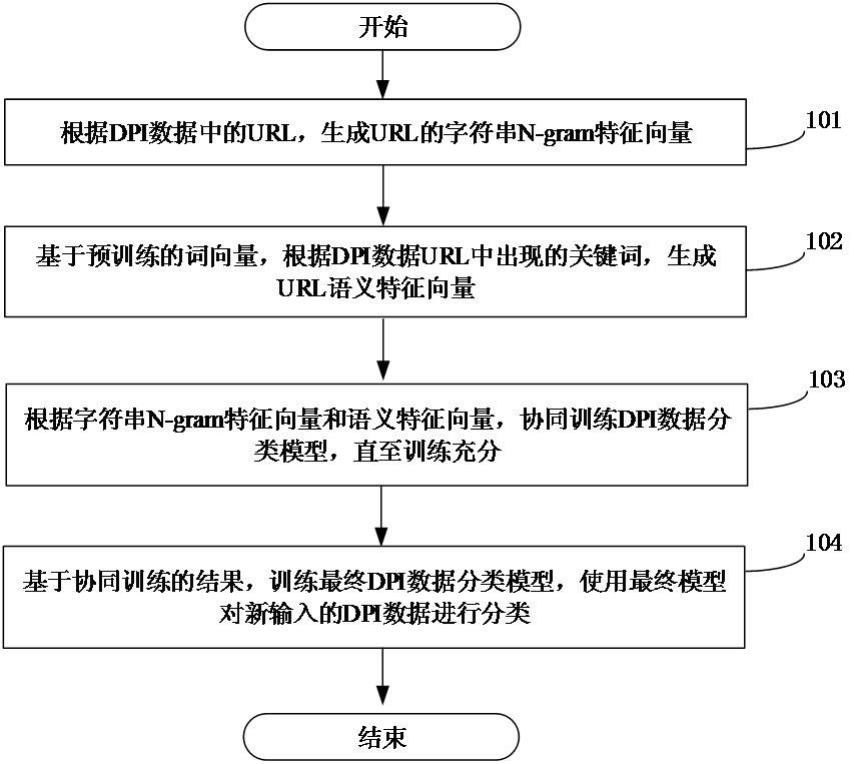
10、1.根据dpi数据中的url,生成url的字符串n-gram特征向量;
11、2.基于预训练的词向量,根据dpi数据url中出现的关键词,生成url语义特征向量;
12、3. 根据字符串n-gram特征向量和语义特征向量,协同训练dpi数据分类模型,直至训练充分;
13、4. 基于协同训练的结果,训练最终dpi数据分类模型,使用最终模型对新输入的dpi数据进行分类。
14、进一步地,上述方法中,所述根据dpi数据中的url,生成url的字符串n-gram特征向量包括:
15、1) 基于统计url中不同长度的n-gram个数,生成初始n-gram向量。其中n-gram的长度范围可以根据经验进行预设。
16、2)通过对初始向量的线性归一化、每个n-gram在dpi数据中的idf值、位置权重等方法对初始向量进行修正。
17、3)通过特征选择方法进行特征选择,得到最终的n-gram特征向量。
18、进一步地,上述方法中,所述基于预训练的词向量,根据dpi数据url中出现的关键词,生成url语义特征向量的步骤,包括:
19、1)通过维基百科或其他语料库,得到预训练词向量;
20、2)从url中抽取每个url中包含于预训练词向量中的特征词
21、3)对特征词进行筛选;
22、4)对筛选后的特征词的词向量进行加和,得到语义特征向量。
23、进一步地,上述方法中,所述根据字符串n-gram特征向量和语义特征向量,协同训练dpi数据分类模型,直至训练充分的步骤,包括:
24、1)基于不同特征表示的协同训练;
25、2)分别利用标注的样本集分别生成两类特征并各自训练分类器;
26、3)对无标记的数据进行标记预测,并选出置信度较高的样例添加至对方分类器的标记训练集中;
27、4)不断重复这个过程,直至所有的无标记数据都被标记或分类模型被充分训练后停止迭代。
28、进一步地,上述方法中,所述基于协同训练的结果,训练最终dpi数据分类模型,使用最终模型对新输入的dpi数据进行分类的步骤,包括:
29、1)使用扩充的标注数据和两个分类模型,训练最终分类模型。最终分类模型的训练可以采用以下2种形式:
30、a)将训练完毕的两个分类模型的输出合并作为特征,训练第二级分类模型。最终得到的分类模型分类两级,对于每个输入样本,采用两个基本模型进行分类,将两个模型的结果作为第二级模型的输入,将第二级模型的输出作为最终分类结果;
31、b)基于扩充后的训练数据集,合并2类特征,选取合适的模型结构,训练新的分类模型,使用新的分类模型的输出作为最终分类结果。
32、使用最终模型对输入的dpi数据进行分类。
技术特征:
1.一种积分系统中基于半监督学习的dpi数据分类方法,其特征在于:
2.如1中所述的根据dpi数据中的url,生成url的字符串n-gram特征向量,其特征在于:基于统计url中不同长度的n-gram个数,生成初始n-gram向量。
3.其中n-gram的长度范围可以根据经验进行预设;对对初始向量进行修正,修正的方式包含但不限于通过对初始向量的线性归一化、每个n-gram在dpi数据中的idf值、位置权重等方法;通过特征选择方法进行特征选择,得到最终的n-gram特征向量。
4.如1中所述的基于预训练的词向量,根据dpi数据url中出现的关键词,生成url语义特征向量,其特征在于:通过语料库,训练得到预训练词向量;从url中抽取每个url中包含于预训练词向量中的特征词;基于特征词的词向量,获得url语义特征向量。
5.如1中所述根据字符串n-gram特征向量和语义特征向量,协同训练dpi数据分类模型,直至训练充分,其特征在于:
6.如1中所述基于协同训练的结果,训练最终dpi数据分类模型,使用最终模型对新输入的dpi数据进行分类,其特征在于:
7.一种基于半监督学习的dpi数据分类系统,其特征在于,包括:
技术总结
本发明提供了一种积分系统中基于半监督学习的DPI数据分类方法。本发明通过借助积分系统中大量未标注的DPI数据,在保证分类效果的同时,提供了N‑gram特征向量生成和语义特征向量生成,并且通过生成两种不同维度的特征,构建两类模型,进行基于不同特征予以协同训练,扩充训练样本。本发明包含数据预处理模块、数据标注模块、URL特征生成模块、协同训练模块、DPI数据分类模型训练模块以及DPI数据分类模块。
技术研发人员:宋立伟,陈宝,汪哲
受保护的技术使用者:翼集分(上海)数字科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!