一种多层级关联数据异构数据同步方法与流程
本发明涉及数据处理,具体为一种多层级关联数据异构数据同步方法。
背景技术:
1、多层父子数据:目前的异构数据同步方案基本都是单表/宽表实现,当时其对业务人员的开发和理解造成一些误区,而父子数据的维护,会提升业务的理解和开发效率,业务场景不是宽表能解决的,随着我们分布式系统的发展,服务越多,数据的查询成本越高,这就涉及到各种数据的聚合。本发明能通过设置元数据来达到多父子层级的数据维护和查询,更加贴合业务理解。
2、2异构:目前该发明数据源支持持mysql、oraclesqlserver、db2、postgresql、mongodb、hive、hbase、elasticsearch等现在市场上几种数据同步方案分别是
3、1、监听binlog异步发送mq然后消费,但是他们没有保证mq消息的可靠性,如果机器宕机数据就会导致不一致问题;
4、2、直接单表对单表进行数据同步,但是这种业务语义不明确,没有解决分布式服务的数据聚合功能。
5、3、将预设数据仓库中的数据和自定义统计指标与可视化大屏进行配置管理,用的hive继续执行数据过滤,这个是一种方案,但是部署复杂,其中使用了hive,小中型公司不一定有hive,
6、所以针对以上问题,就需要一种能保证了数据的可靠性和正确性,和可以满足中小公司开启一个server就解决复杂数据的同步瓦内特,避免方案过重的问题的方法,所以就需要一种多层级关联数据异构数据同步方法。
技术实现思路
1、本发明的目的在于提供一种多层级关联数据异构数据同步方法,本发明提供一种绿色、环保、可靠性高的热、电、氧多种需求供应系统,充分利用青藏高原丰富的风光资源,一站式解决当地的低温供热、低氧供氧、供电困难的问题。
2、本发明是这样实现的:
3、本发明提供一种多层级关联数据异构数据同步方法,具体按以下步骤执行:
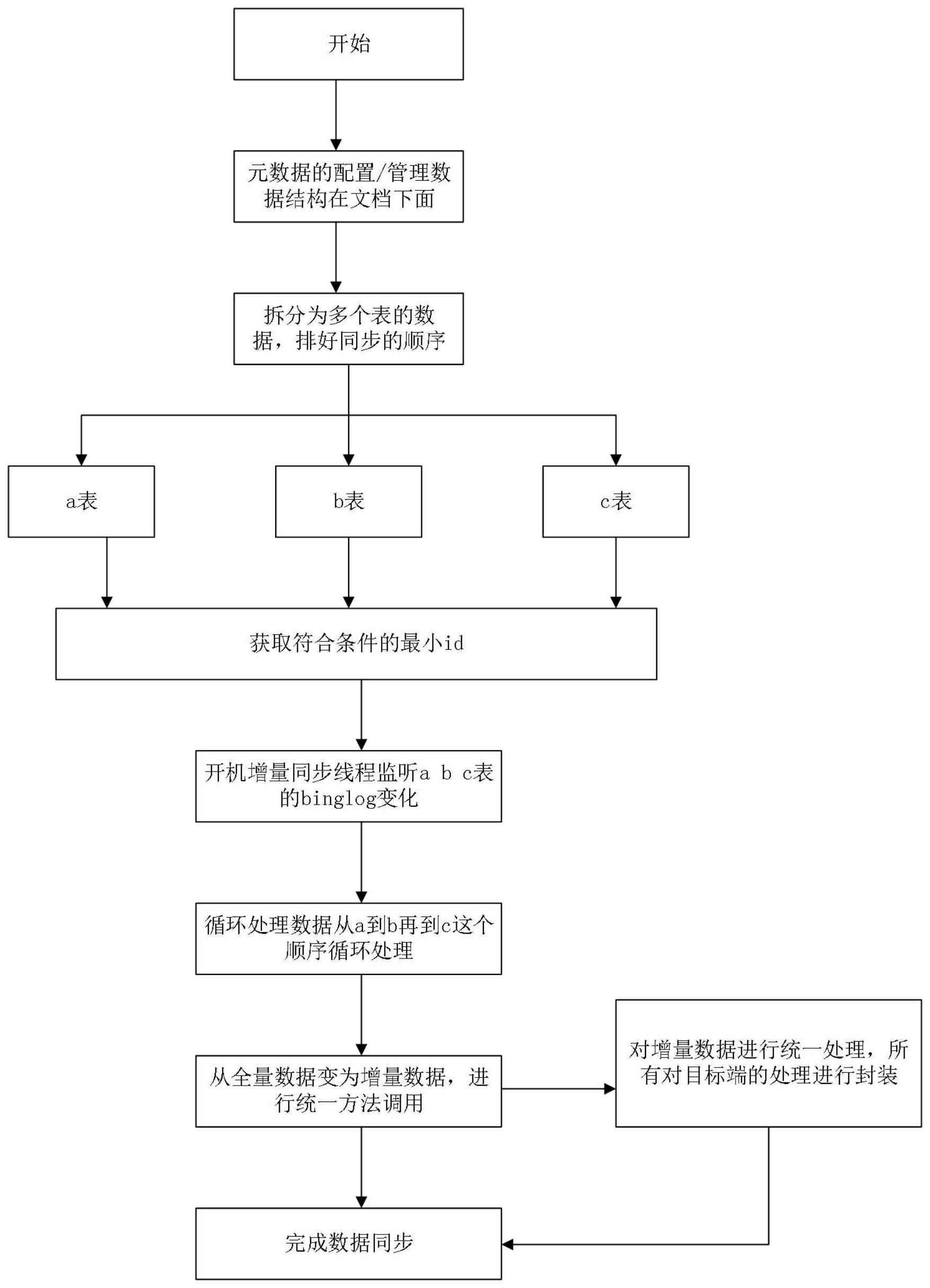
4、s1:首先对包括但不限于mysql、pgsql的多种数据源的binlog数据进行全量数据同步,具体包括以下步骤:
5、s1,1:根据元数据管理和异构数据同步规则区分出同步的先后顺序;根据元数据管理和异构数据同步规则将数量来源的数据分成多个表格,包括但不限于使用a表、b表和c表表示。
6、s1,2:根据表的顺序分别查询数据来源的最小id;
7、s1,3:在执行全量同步之前开启增量同步线程,保证全量同步之后数据的一致性;
8、s1,4:循环滚动数据;
9、s1,5:分批查询对应数据,如果没有就代表数据同步完成,
10、否则分批处理;
11、s1,6:分批处理是从全量数据通过代码变更为增量数据,进行统一方法调用,进行封装;
12、s2:进行目标端数据插入,具体按以下步骤执行;
13、s2.1:批量查询新数据库、目标库的数据,循环处理数据;
14、s2.2:检查同步的记录在新数据库是否存在;
15、s2.3:存在则判断同步数据的时间是否大于新库的时间,将符合条件的数据放到binlogdatas数组中,此处使用jvm s0s1的概念进行生产者/消费者的性能优化;
16、s2.4:不存在或者现在是update数据,但是在目标端没有查询到,就会把update操作变为insert操作进行弥补;
17、s3:进行增量数据同步;
18、s3.1:根据全量数据的同步,同时开启增量数据监听,mq选择的rocketmq,使用其中的事务消息保证在mq的零丢失;
19、s3.2:多线程首先开启消息拉取任务,会先查询该消息是否存在消费记录,如果存在,状态为“消费成功、已提交,并且直接在mq中提交offset;通过binlog消息拉去重试任务,以此获取未消费记录,并写入内存队列,通过binlog拉取重试任务,获取未消费记录,并写入内存队列。如果状态为
20、“消费成功、已提交”不成立,则同样写入内存队列。
21、s3.3:不存在新增消费记录在数据库进行记录,并且将数据放入binlogdatas中,等待异步的数据处理;
22、s3.4:通过mq消息的拉取,在mq消息执行到一半,判断是否存在服务ki l l导致数据的未处理的情况,是则进行获取未消费记录,统一放入binlogdatas;统一拉取消息。
23、s3.5:另一种情况mq消息已经处理了,但offset失败,进行判断是mqserver或client出现问题,进行获取所有已消费状态的记录,提交已消费的信息offset,并且更新记录状态为已提交;
24、s3.6:将全量数据变成增量数据,进行统一调用;
25、s3.7:增量数据统一处理所有对目标端的处理,进行封装;s4:完成数据同步。
26、进一步,在进行全量数据同步时,当出现父数据和子数据先来,则按照缓存机制进行临时缓存,等主表数据到来后,再组装正确的数据结果并同步给目标端。
27、进一步,所述数据源包括但不限于mysql、oraclesqlserver、db2、postgresql、mongodb、hive、hbase、elasticsearch。
28、与现有技术相比,本发明的有益效果是:
29、1、通过全量更新/增量更新2种方案的支持下,实现多父子数据的多异构数据的同步(选用最终一致性方案),可以监听mysql,pgsql等多种数据源的binlog数据,通过元数据管理服务进行数据的转换,实现新增/修改/删除等操作,维护多层级的数据,方便业务系统进行查询。
30、2、通过mq的零丢失方案和系统中的多种补偿方案保证了数据的可靠性和正确性,通过父子结构来达到了分布式的聚合功能,解决了多层父子数据的数据聚合问题,可以满足中小公司开启一个server就解决复杂数据的同步瓦内特,避免方案过重的问题。
技术特征:
1.一种多层级关联数据异构数据同步方法,其特征在于:具体按以下步骤执行:
2.根据权利要求1所述的一种多层级关联数据异构数据同步方法,其特征在于,在进行全量数据同步时,当出现父数据和子数据先来,则按照缓存机制进行临时缓存,等主表数据到来后,再组装正确的数据结果并同步给目标端。
3.根据权利要求1所述的一种多层级关联数据异构数据同步方法,其特征在于,在步骤s1,1中,根据元数据管理和异构数据同步规则将数量来源的数据分成多个表格,包括但不限于使用a表、b表和c表表示。
4.根据权利要求1所述的一种多层级关联数据异构数据同步方法,其特征在于,所述数据源包括但不限于mysql、oraclesqlserver、db2、postgresql、mongodb、hive、hbase、elasticsearch。
5.根据权利要求1所述的一种多层级关联数据异构数据同步方法,其特征在于,在步骤s3.2中,通过binlog消息拉去重试任务,以此获取未消费记录,并写入内存队列。
6.根据权利要求5所述的一种多层级关联数据异构数据同步方法,其特征在于,在步骤s3.2中,如果状态为“消费成功、已提交”不成立,则同样写入内存队列。
7.根据权利要求1所述的一种多层级关联数据异构数据同步方法,其特征在于,在步骤s3.4中,统一拉取消息,通过binlog拉取重试任务,获取未消费记录,并写入内存队列。
技术总结
本发明公开了一种多层级关联数据异构数据同步方法,包括首先对包括但不限于Mysql、Pgsql的多种数据源的binlog数据进行全量数据同步,具体根据元数据管理和异构数据同步规则区分出同步的先后顺序;根据表的顺序分别查询数据来源的最小id;在执行全量同步之前开启增量同步线程,保证全量同步之后数据的一致性;循环滚动数据;分批查询对应数据,如果没有就代表数据同步完成,否则分批处理;分批处理是从全量数据通过代码变更为增量数据,进行统一方法调用,进行封装;进行目标端数据插入,具体按以下步骤执行;批量查询新数据库、目标库的数据,循环处理数据。本发明通过全量更新/增量更新2种方案的支持下,实现多父子数据的多异构数据的同步。
技术研发人员:谢高峰
受保护的技术使用者:北京华宇九品科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!