一种基于概率图和ViT模型的图片分类方法
本发明涉及一种基于概率图和vit模型的图片分类方法,属于计算机视觉图片分类。
背景技术:
1、transformer在自然语言处理领域取得了巨大的成功,激励了人们尝试将多头注意力机制引入主流框架为卷积神经网络的计算机视觉领域。相较于卷积神经网络,transformer在捕捉图片全局信息方面有着巨大的优势,同时,transformer的可并行化计算也促进了其在视觉领域的应用。目前vision transformer在计算机视觉的各类任务,如图片分类、目标检测和图片降噪等方面取得了令人瞩目的效果。但是大量研究发现,transformer的核心多头注意力机制中的不同头之间存在参数冗余,严重影响了模型的整体性能。
技术实现思路
1、本发明的目的是提供一种基于概率图和vit模型的图片分类方法,用来解决上述缺陷。
2、为了实现上述目的,本发明采用的技术方案是:
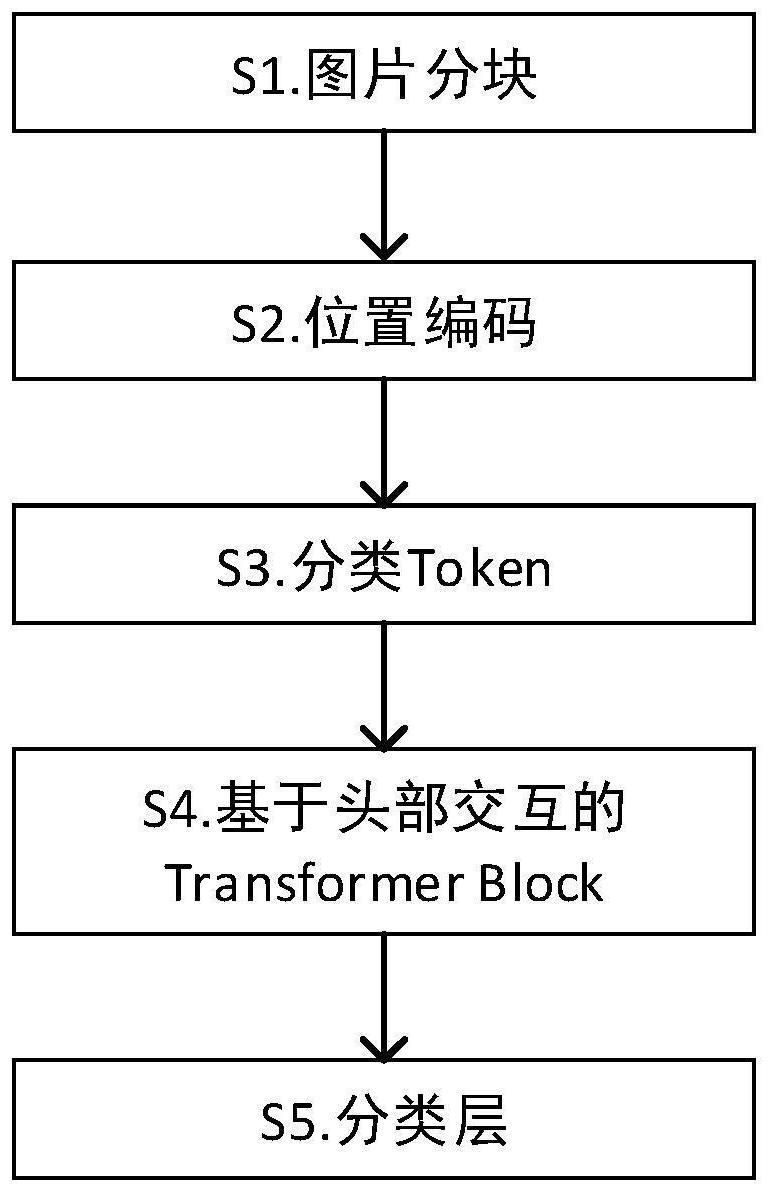
3、一种基于概率图和vit模型的图片分类方法,包括以下步骤:
4、s1、将输入模型的图片进行分块,然后将每个图片块展平成一维向量,最后通过线性变换生成patch embedding;
5、s2、给每个patch embedding加上位置编码,补充位置信息;
6、s3、增加一个用于分类的token,学习其他图片patch的整体信息;
7、s4、基于头部交互的transformer block,把attention values看作隐变量,利用概率图模型中的explaining-away effects以及transformer的层级结构,将attentionlogits层层传递,并将相邻层的值进行融合,促进不同头部之间的交互;
8、s5、使用两层全连接层,将分类token输入分类层,得到图片的分类结果。
9、本发明技术方案的进一步改进在于,所述s1的具体步骤为:
10、s11、将输入模型的图片进行分块、展平,具体操作为:
11、将图片patch的长宽均设置为p,即将图片数据h*w*c变换为
12、
13、其中,n为一张图分割的patch数量,c为通道数,h为图片高度,w为图片宽度;
14、s12、将patch向量线性变换为patch embedding:
15、patch_embedding=nn.linear(patch_dim,dim)
16、其中,patch_dim为patch向量的维度,dim为patch embedding的维度。
17、本发明技术方案的进一步改进在于,所述s2的具体操作为:
18、pos_embedding=nn.parameter(torch.randn(1,num_patches+1,dim))
19、其中,pos_embedding为patch的位置编码,num_patches为patch的数量。
20、本发明技术方案的进一步改进在于,所述s3的具体操作为:
21、添加一个专门用于分类的可学习编码,与输入进行拼接,具体为:
22、cls_token=nn.parameter(torch.randn(1,1,dim))
23、其中,cls_token为分类token,然后与其他patch token进行拼接。
24、本发明技术方案的进一步改进在于,所述s4的具体步骤为:
25、s41、attention head序列建模,将attention value看作隐变量,
26、p(y∣x)=∫ap(y∣a,x)p(a∣x)da
27、其中,y为图片label,x为输入照片,a为中间层attention values,p(a∣x)是联合先验分布;
28、s42、transformer层次化建模,利用transformer的层级结构,将此过程可表示为:
29、
30、其中,aj表示第j层的attention分布,aj的计算需要依赖aj-1的递归结构,具体来讲,aj的计算通式如下:
31、
32、s43、相邻层的attention融合,在transformer的层级block的多头注意力计算模块添加mlp,将各层之间的attention vlaue进行融合交互,促进不同头部的去冗余,将此过程可表示为:
33、aj=softmax(zj+mlp(zj,zj-1))
34、其中,zj为第j层的attention logits,mlp是两层全连接层,用于相邻层注意力值得融合交互。
35、本发明技术方案的进一步改进在于,所述s5的具体操作公式为:
36、x=self.to_cls_token(x[:,0])
37、y=self.mlp_head(x)
38、其中,x为输出的分类token,mlp_head()为分类层,y为输出的预测。
39、由于采用了上述技术方案,本发明取得的技术效果有:
40、本发明设计的一种基于概率图和vit模型的图片分类方法针对普通visiontransformer模型中多头注意力机制头部参数的冗余问题,将多头注意力机制建模为概率图模型,将注意力值看作隐变量,促进不同注意力头部之间的交互。
41、本发明为了促进不同头部之间的交互,将attention logits逐层传递,将相邻层之间的attention logits进行融合,促使不同的头部捕捉不同的特征。
42、本发明通过促进头部交互,提升了参数效率,进而提升了图形分类正确率以及迁移学习效果,同时提高了特征的可解释性。
技术特征:
1.一种基于概率图和vit模型的图片分类方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于概率图和vit模型的图片分类方法,其特征在于,所述s1的具体步骤为:
3.根据权利要求1所述的一种基于概率图和vit模型的图片分类方法,其特征在于,所述s2的具体操作为:
4.根据权利要求1所述的一种基于概率图和vit模型的图片分类方法,其特征在于,所述s3的具体操作为:
5.根据权利要求1所述的一种基于概率图和vit模型的图片分类方法,其特征在于,所述s4的具体步骤为:
6.根据权利要求1所述的一种基于概率图和vit模型的图片分类方法,其特征在于,所述s5的具体操作公式为:
技术总结
本发明涉及一种基于概率图和ViT模型的图片分类方法,属于计算机视觉图片分类技术领域,将多头注意力机制从概率论的角度进行建模,将多头注意力中的attention value看作隐变量,利用概率图模型的Explaining‑away Effects以及Transformer的层级结构,将attention logits层层传递,并将相邻层的值进行融合,促进不同头部之间的交互。本发明针对普通Vision Transformer模型中多头注意力机制头部参数的冗余问题,将多头注意力机制建模为概率图模型,将注意力值看作隐变量,促进不同注意力头部之间的交互。
技术研发人员:宫继兵,彭吉全,林宇庭,赵金烨,丛方鹏
受保护的技术使用者:燕山大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!